Learn the advanced features of SONET and SDH; specifically, the different ways of concatenating SONET and SDH signals, different techniques for mapping packet data onto SONET and SDH connections, transparency services for carrier’s carrier applications, and fault management and performance monitoring capabilities.
3.2.1 Standard Contiguous Concatenation in SONET and SDH
3.2.2 Arbitrary Concatenation
3.2.3 Virtual Concatenation
3.2.3.1 Higher-Order Virtual Concatenation (HOVC)
3.2.3.2 Lower-Order Virtual Concatenation (LOVC)
3.3 LINK CAPACITY ADJUSTMENT SCHEME
3.4 PAYLOAD MAPPINGS
3.4.1 IP over ATM over SONET
3.4.2 Packet over SONET/SDH
3.4.3 Generic Framing Procedure (GFP)
3.4.3.1 GFPFrame Structure
3.4.3.2 GFPFunctions
3.4.4 Ethernet over SONET/SDH
3.5 SONET/SDH TRANSPARENCY SERVICES
3.5.1 Methods for Overhead Transparency
3.5.2 Transparency Service Packages
3.6 WHEN THINGS GO WRONG
3.6.1 Transport Problems and Their Detection
3.6.1.1 Continuity Supervision
3.6.1.2 Connectivity Supervision
3.6.1.3 Signal Quality Supervision
3.6.1.4 Alignment Monitoring
3.6.2 Problem Localization and Signal Maintenance
3.6.2.1 Alarm Indication Signals
3.6.2.2 Remote Defect Indication
3.6.3 Quality Monitoring
3.6.3.1 Blips and BIPs
3.6.4 Remote Error Monitoring
3.6.5 Performance Measures
3.7 SUMMARY
3.1 Introduction
In the previous chapter, we described TDM and how it has been utilized in SONET and SDH standards. We noted that when SONET and SDH were developed, they were optimized for carrying voice traffic. At that time no one anticipated the tremendous growth in data traffic that would arise due to the Internet phenomenon. Today, the volume of data traffic has surpassed voice traffic in most networks, and it is still growing at a steady pace. In order to handle data traffic efficiently, a number of new features have been added to SONET and SDH.
In this chapter, we review some of the advanced features of SONET and SDH. Specifically, we describe the different ways of concatenating SONET and SDH signals, and different techniques for mapping packet data onto SONET and SDH connections. We also address transparency services for carrier’s carrier applications, as well as fault management and performance monitoring capabilities. The subject matter covered in this chapter will be used as a reference when we discuss optical control plane issues in later chapters. A rigorous understanding of this material, however, is not a prerequisite for dealing with the control plane topics.
3.2 All about Concatenation
Three types of concatenation schemes are possible under SONET and SDH. These are:
Standard contiguous concatenation
Arbitrary contiguous concatenation
Virtual concatenation
These concatenation schemes are described in detail next.
3.2.1 Standard Contiguous Concatenation in SONET and SDH
SONET and SDH networks support contiguous concatenation whereby a few standardized “concatenated” signals are defined, and each concatenated signal is transported as a single entity across the network [ANSI95a, ITU-T00a]. This was described briefly in the previous chapter.
The concatenated signals are obtained by “gluing” together the payloads of the constituent signals, and they come in fixed sizes. In SONET, these are called STS-Nc Synchronous Payload Envelopes (SPEs), where N = 3X and X is restricted to the values 1, 4, 16, 64, or 256. In SDH, these are called VC-4 (equivalent to STS-3c SPE), and VC-4-Xc where X is restricted to 1, 4, 16, 64, or 256.
The multiplexing procedures for SONET (SDH) introduce additional constraints on the location of component STS-1 SPEs (VC-4s) that comprise the STS-NcSPE (VC-4-Xc). The rules for the placement of standard concatenated signals are [ANSI95a]:
Concatenation of three STS-1s within an STS-3c: The bytes from concatenated STS-1s shall be contiguous at the STS-3 level but shall not be contiguous when interleaved to higher-level signals. When STS-3c signals are multiplexed to a higher rate, each STS-3c shall be wholly contained within an STS-3 (i.e., occur only on tributary input boundaries 1–3, 4–6, 7–9, etc.). This rule does not apply to SDH.
Concatenation of STS-1s within an STS-Nc (N = 3X, where X = 1, 4, 16, 64, or 256). Such concatenation shall treat STS-Nc signals as a single entity. The bytes from concatenated STS-1s shall be contiguous at the STS-N level, but shall not be contiguous when multiplexed on to higher-level signals. This also applies to SDH, where the SDH term for an STS-Nc is an AU-4-Xc where X = N/3.
When the STS-Nc signals are multiplexed to a higher rate, these signals shall be wholly contained within STS-M boundaries, where M could be 3, 12, 48, 192, or 768, and its value must be the closest to, but greater than or equal to N (e.g., if N = 12, then the STS-12c must occur only on boundaries 1–12, 13–24, 25–36, etc.). In addition to being contained within STS-M boundaries, all STS-Nc signals must begin on STS-3 boundaries.
The primary purpose of these rules is to ease the development burden for hardware designers, but they can seriously affect the bandwidth efficiency of SONET/SDH links.
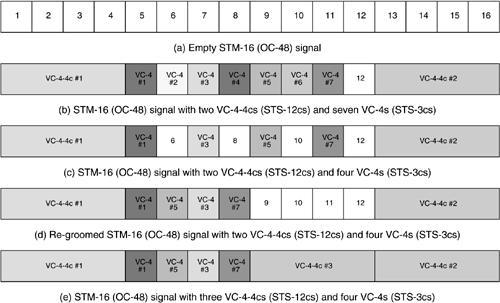
In Figure 3-1(a), an STM-16 (OC-48) signal is represented as a set of 16 time slots, each of which can contain a VC-4 (STS-3c SPE). Let us examine the placement of VC-4 and VC-4-4c (STS-3c and STS-12c SPE) signals into this structure, in line with the rules above. In particular a VC-4-4c (STS-12c SPE) must start on boundaries of 4. Figure 3-1(b) depicts how the STM-16 has been filled with two VC-4-4c (STS-12c) and seven VC-4 signals. In Figure 3-1(c), three of the VC-4s have been removed, that is, are no longer in use. Due to the placement restrictions, however, a VC 4-4c cannot be accommodated in this space. In Figure 3-1(d), the STM-16 has been “regroomed,” that is, VC-4 #5 and VC-4 #7 have been moved to new timeslots. Figure 3-1(e) shows how the third VC-4-4c is accommodated.
Figure 3-1. Timeslot Constraints and Regrooming with Contiguous (Standard) Concatenation
3.2.2 Arbitrary Concatenation
In the above example, a “regrooming” operation was performed to make room for a signal that could not be accommodated with the standard contiguous concatenation rules. The problem with regrooming is that it is service impacting, that is, service is lost while the regrooming operation is in progress. Because service impacts are extremely undesirable, regrooming is not frequently done, and the bandwidth is not utilized efficiently.
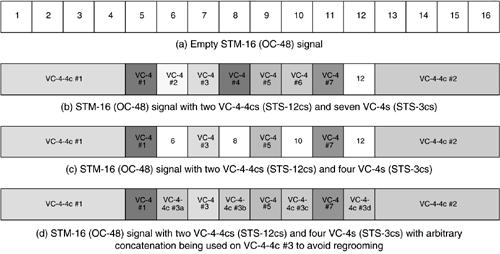
To get around these restrictions, some manufacturers of framers, that is, the hardware that processes the SDH multiplex section layer (SONET line layer), offer a capability known as “flexible” or arbitrary concatenation. With this capability, there are no restrictions on the size of an STS-Nc (VC-4-Xc) or the starting time slot used by the concatenated signal. Also, there are no constraints on adjacencies of the STS-1 (VC-4-Xc) time slots used to carry it, that is, the signals can use any combination of available time slots. Figure 3-2 depicts how the sequence of signals carried over the STM-16 of Figure 3-1 can be accommodated without any regrooming, when the arbitrary concatenation capability is available.
Figure 3-2. Timeslot Usage with Arbitrary Concatenation
3.2.3 Virtual Concatenation
As we saw earlier, arbitrary concatenation overcomes the bandwidth inefficiencies of standard contiguous concatenation by removing the restrictions on the number of components and their placement within a larger concatenated signal. Standard and arbitrary contiguous concatenation are services offered by the network, that is, the network equipment must support these capabilities. The ITU-T and the ANSI T1 committee have standardized an alternative, called virtual concatenation. With virtual concatenation, SONET and SDH PTEs can “glue” together the VCs or SPEs of separately transported fundamental signals. This is in contrast to requiring the network to carry signals as a single concatenated unit.
3.2.3.1 HIGHER-ORDER VIRTUAL CONCATENATION (HOVC)
HOVC is realized under SONET and SDH by the PTEs, which combine either multiple STS-1/STS-3c SPEs (SONET), or VC-3/VC-4 (SDH). Recall that the VC-3 and STS-1 SPE signals are nearly identical except that a VC-3 does not contain the fixed stuff bytes found in columns 30 and 59 of an STS-1 SPE. A SONET STS-3c SPE is equivalent to a SDHVC-4.
These component signals, VC-3s or VC-4s (STS-1 SPEs or STS-3c SPEs), are transported separately through the network to an end system and must be reassembled. Since these signals can take different paths through the network, they may experience different propagation delays. In addition to this fixed differential delay between the component signals, there can also be a variable delay component that arises due to the different types of equipment processing the signals and the dynamics of the fiber itself. Note that heating and cooling effects can affect the propagation speed of light in a fiber, leading to actual measurable differences in propagation delay.
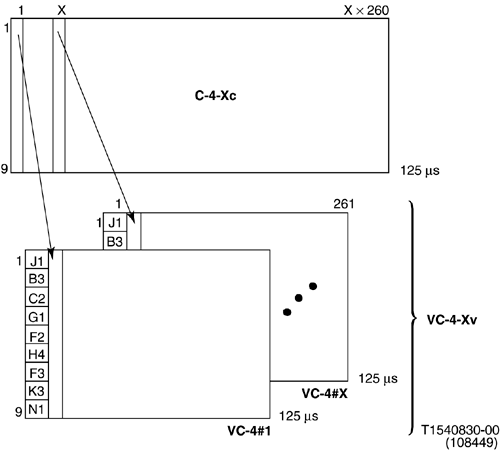
The process of mapping a concatenated container signal, that is, the raw data to be transported, into a virtually concatenated signal is shown in Figure 3-3. Specifically, at the transmitting side, the payload gets packed in XVC-4s just as if these were going to be contiguously concatenated. Now the question is, How do we identify the component signals and line them up appropriately given that delays for the components could be different?
Figure 3-3. Mapping a Higher Rate Payload in a Virtually Concatenated Signal (from [ITU-T00a])
The method used to align the components is based on the multiframe techniques described in Chapter 2. A jumbo (very long) multiframe is created by overloading the multiframe byte H4 in the path overhead. Bits 5–8 of the H4 byte are incremented in each 125µs frame to produce a multiframe consisting of 16 frames. In this case, bits 5–8 of H4 are known as the multiframe indicator 1 (MFI1). This multiframe will form the first stage of a two-stage multiframe. In particular, bits 1–4 of the H4 byte are used in a way that depends on the position in the first stage of the multiframe. This is shown in Table 3-1.
Within the 16-frame first stage multiframe, a second stage multiframe indicator (MFI2) is defined utilizing bits 1–4 of H4 in frames 0 and 1, giving a total of 8 bits per frame. It is instructive to examine the following:
How long in terms of the number of 125µs frames is the complete HOVC multiframe structure? Answer: The base frame (MFI1) is 16 frames long, and the second stage is 28 = 256 frames long. Since this is a two-stage process, the lengths multiply giving a multiframe that is 16 × 256 = 4096 frames long.
What is the longest differential delay, that is, delay between components that can be compensated? Answer: The differential delay must be within the duration of the overall multiframe structure, that is, 125µS × 4096 = 512mS, that is, a little over half a second.
Suppose that an STS-1-2v is set up for carrying Ethernet traffic between San Francisco and New York such that one STS-1 goes via a satellite link and the other via conventional terrestrial fiber. Will this work? Answer: Assuming that a geo-synchronous satellite is used, then the satellite’s altitude would be about 35775 km. Given that the speed of light is 2.99792 × 108 m/sec, this leads to a round trip delay of about 239 ms. If the delay for the fiber route is 20 ms, then the differential delay is 209 ms, which is within the virtual concatenation range. Also, since the average circumference of the earth is only 40,000 km, this frame length should be adequate for the longest fiber routes.
Table 3-1. Use of Bits 1–4 in H4 Byte for First Stage Multiframe Indication (MFI1)
Multi-Frame Indicator 1 (MFI1)
Meaning of Bits 1–4 in H4
0
2nd multiframe indicator MFI2 MSB (bits 1–4)
1
2nd multiframe indicator MFI2 LSB (bits 5–8)
2–13
Reserved (0000)
14
Sequence indicator SQ MSB (bits 1–4)
15
Sequence indicator SQ LSB (bits 5–8)
Now, the receiver must be able to distinguish the different components of a virtually concatenated signal. This is accomplished as follows. In frames 14 and 15 of the first stage multiframe, bits 1–4 of H4 are used to give a sequence indicator (SQ). This is used to indicate the components (and not the position in the multiframe). Due to this 8-bit sequence indicator, up to 256 components can be accommodated in HOVC. Note that it is the receiver’s job to compensate for the differential delay and to put the pieces back together in the proper order. The details of how this is done are dependent on the specific implementation.
3.2.3.2 LOWER-ORDER VIRTUAL CONCATENATION (LOVC)
The virtual concatenation of lower-order signals such as VT1.5s (VC-11), VT2 (VC-12), and so on are based on the same principles as described earlier. That is, a sequence number is needed to label the various components that make up the virtually concatenated signal, and a large multiframe structure is required for differential delay compensation. In the lower-order case, however, there are fewer overhead bits and bytes to spare so the implementation may seem a bit complex. Let us therefore start with the capabilities obtained.
LOVC Capabilities and Limitations
Table 3-2 lists the LOVC signals for SONET/SDH, the signals they can be contained in and the limits on the number of components that can be concatenated. The last two columns are really the most interesting since they show the range of capacities and the incremental steps of bandwidth.
LOVC Implementation
Let us first examine how the differential delay compensating multiframe is put together. This is done in three stages. Recall that the SONETVT overhead (lower-order SDHVC overhead) is defined in a 500 µs multiframe, as indicated in the path layer multiframe indicator H4. This makes available the four VT overhead bytes V5, J2, Z6, and Z7, from one SONET/SDH frame byte. Since a number of bits in these bytes are used for other purposes, an additional second stage of multiframe structure is used to define extended VT signal labels.
This works as follows (note that SDH calls the Z7 byte as K4 but uses it the same way): First of all, the V5 byte indicates if the extended signal label is being used. Bits 5 through 7 of V5 provide a VT signal label. The signal label value of 101 indicates that a VT mapping is given by the extended signal label in the Z7 byte. If this is the case, then a 1-bit frame alignment signal “0111 1111 110” is sent in bit 1 of Z7, called the extended signal label bit. The length of this second stage VT level multiframe (which is inside the 500 µs VT multiframe) is 32 frames. The extended signal label is contained in bits 12–19 of the multiframe. Multiframe position 20 contains “0.” The remaining 12 bits are reserved for future standardization.
Table 3-2. Standardized LOVC Combinations and Limits
Signal SONET/SDH
Carried in SONET/SDH
X
Capacity (kbit/s)
In steps of (kbit/s)
VT1.5-Xv SPE/VC-11-Xv
STS-1/VC-3
1 to 28
1600 to 44800
1600
VT2-Xv SPE/VC-12-Xv
STS-1/VC-3
1 to 21
2176 to 45696
2176
VT3-Xv SPE
STS-1
1 to 14
3328 to 46592
3328
VT6-Xv SPE/VC-2-Xv
STS-1/VC-3
1 to 7
6784 to 47448
6784
VT1.5/VC-11-Xv
STS-3c
1 to 64
1600 to 102400
1600
VT2/VC-12-Xv
STS-3c
1 to 63
2176 to 137088
2176
VT3-Xv SPE
STS-3c
1 to 42
3328 to 139776
3328
VT6-Xv SPE/VC-2-Xv
STS-3c
1 to 21
6784 to 142464
6784
VT1.5/VC-11-Xv
unspecified
1 to 64
1600 to 102400
1600
VT2/VC-12-Xv
unspecified
1 to 64
2176 to 139264
2176
VT3-Xv SPE
unspecified
1 to 64
3328 to 212992
3328
VT6-Xv SPE
unspecified
1 to 64
6784 to 434176
6784
Note: X is limited to 64 due the sequence indicator having 6 bits.
Bit 2 of the Z7 byte is used to convey the third stage of the multistage multiframe in the form of a serial string of 32 bits (over 32 four-frame multi-frames and defined by the extended signal label). This is shown in Figure 3-4. This string is repeated every 16 ms (32 bits × 500 µs/bit) or every 128 frames.
Figure 3-4. Third Stage of LOVC Multiframe Defined by Bit 2 of the Z7 Byte over the 32 Frame Second Stage Multiframe
The third stage string consists of the following fields: The third stage virtual concatenation frame count is contained in bits 1 to 5. The LOVC sequence indicator is contained in bits 6 to 11. The remaining 21 bits are reserved for future standardization.
Let us now consider a concrete example. Suppose that there are three stages of multiframes with the last stage having 5 bits dedicated to frame counting. What is the longest differential delay that can be compensated and in what increments? The first stage was given by the H4 byte and is of length 4, resulting in 4 × 125 µs = 500 µs. The second stage was given by the extended signal label (bit 1 of Z7) and it is of length 32. Since this is inside the first stage, the lengths multiply, resulting in 32 × 500 µs = 16 ms. The third stage, which is within the 32-bit Z7 string, has a length of 25 = 32 and is contained inside the second stage. Hence, the lengths multiply, resulting in 32 × 16 ms = 512 ms. This is the same compensation we showed with HOVC. Since the sequence indicator of the third stage is used to line up the components, the delay compensation is in 16 ms increments.
3.3 Link Capacity Adjustment Scheme
Virtual concatenation allows the flexibility of creating SONET/SDH pipes of different sizes. The Link Capacity Adjustment Scheme or LCAS [ITU-T01a] is a relatively new addition to the SONET/SDH standard. It is designed to increase or decrease the capacity of a Virtually Concatenated Group (VCG) in a hitless fashion. This capability is particularly useful in environments where dynamic adjustment of capacity is important. The LCAS mechanism can also automatically decrease the capacity if a member in a VCG experiences a failure in the network, and increase the capacity when the fault is repaired. Although autonomous addition after a failure is repaired is hitless, removal of a member due to path layer failures is not hitless. Note that a “member” here refers to a VC (SDH) or an SPE (SONET). In the descriptions below, we use the term member to denote a VC.
Note that virtual concatenation can be used without LCAS, but LCAS requires virtual concatenation. LCAS is resident in the H4 byte of the path overhead, the same byte as virtual concatenation. The H4 bytes from a 16-frame sequence make up a message for both virtual concatenation and LCAS. Virtual concatenation uses 4 of the 16 bytes for its MFI and sequence numbers. LCAS uses 7 others for its purposes, leaving 5 reserved for future development. While virtual concatenation is a simple labeling of individual STS-1s within a channel, LCAS is a two-way handshake protocol. Status messages are continuously exchanged and consequent actions taken.
From the perspective of dynamic provisioning enabled by LCAS, each VCG can be characterized by two parameters:
XMAX, which indicates the maximum size of the VCG and it is usually dictated by hardware and/or standardization limits
XPROV, which indicates the number of provisioned members in the VCG
With each completed ADD command, XPROV increases by 1, and with each completed REMOVE command XPROV decreases by 1. The relationship 0 ≤ XPROV ≤ XMAX always holds. The operation of LCAS is unidirectional. This means that in order to bidirectionally add or remove members to or from a VCG, the LCAS procedure has to be repeated twice, once in each direction. These actions are independent of each other, and they are not required to be synchronized.
The protocols behind LCAS are relatively simple. For each member in the VCG (total of XMAX), there is a state machine at the transmitter and a state machine at the receiver. The state machine at the transmitter can be in one of the following five states:
IDLE: This member is not provisioned to participate in the VCG.
NORM: This member is provisioned to participate in the VCG and has a good path to the receiver.
DNU: This member is provisioned to participate in the VCG and has a failed path to the receiver.
ADD: This member is in the process of being added to the VCG.
REMOVE: This member is in the process of being deleted from the VCG.
The state machine at the receiver can be in one of the following three states:
IDLE: This member is not provisioned to participate in the VCG.
OK: The incoming signal for this member experiences no failure condition. Or, the receiver has received and acknowledged a request for addition of this member.
FAIL: The incoming signal for this member experiences some failure condition, or an incoming request for removal of a member has been received and acknowledged.
The transmitter and the receiver communicate using control packets to ensure smooth transition from one state to another. The control packets consist of XMAX control words, one for each member of the VCG. The following control words are sent from source to the receiver in order to carry out dynamic provisioning functions. Each word is associated with a specific member (i.e., VC) in the VCG.
FADD: Add this member to the group.
FDNU: Delete this member from the group.
FIDLE: Indicate that this VC is currently not a member of the group.
FEOS: Indicate that this member has the highest sequence number in the group (EOS denotes End of Sequence).
FNORM: Indicate that this member is normal part of the group and does not have the highest sequence number.
The following control words are sent from the receiver to the transmitter. Each word is associated with a specific VC in the VCG.
RFAIL and ROK: These messages capture the status of all the VCG members at the receiver. The status of all the members is returned to the transmitter in the control packets of each member. The transmitter can, for example, read the information from member No. 1 and, if that is unavailable, the same information from member No. 2, and so on. As long as no return bandwidth is available, the transmitter uses the last received valid status.
RRS_ACK: This is a bit used to acknowledge the detection of renumbering of the sequence or a change in the number of VCG members. This acknowledgment is used to synchronize the transmitter and the receiver.
The following is a typical sequence for adding a member to the group. Multiple members can be added simultaneously for fast resizing.
The network management system orders the source to add a new member (e.g., a VC) to the existing VCG.
The source node starts sending FADD control commands in the selected member. The destination notices the FADD command and returns an ROK in the link status for the new member.
The source sees the ROK, assigns the member a sequence number that is one higher than the number currently in use.
At a frame boundary, the source includes the VC in the byte interleaving and sets the control command to FEOS, indicating that this VC is in use and it is the last in the sequence.
The VC that previously was “EOS ” now becomes “NORM” (normal) as it is no longer the one with the highest sequence number.
The following is a typical sequence for deleting the VC with the highest sequence number (EOS) from a VCG:
The network management system orders the source to delete a member from the existing VCG.
The source node starts sending FIDLE control commands in the selected VC. It also sets the member with the next highest sequence number as the EOS and sends FEOS in the corresponding control word.
The destination notices the FIDLE command and immediately drops the channel from the reassembly process. It also responds with RFAIL and inverts the RRS_ACK bit.
In this example, the deleted member has the highest sequence number. If this is not the case, then the other members with sequence numbers between the newly deleted member and the highest sequence number are renumbered.
LCAS and virtual concatenation add tremendous amount of flexibility to SONET and SDH. Although SONET and SDH were originally designed to transport voice traffic, advent of these new mechanisms has made it perfectly suitable for carrying more dynamic and bursty data traffic. In the next section, we discuss mechanisms for mapping packet payloads into SONET and SDH SPEs.
3.4 Payload Mappings
So far, the multiplexing structure of SONET and SDH has been described in detail. To get useful work out of these different sized containers, a payload mapping is needed, that is, a systematic method for inserting and removing the payload from a SONET/SDH container. Although it is preferable to use standardized mappings for interoperability, a variety of proprietary mappings may exist for various purposes.
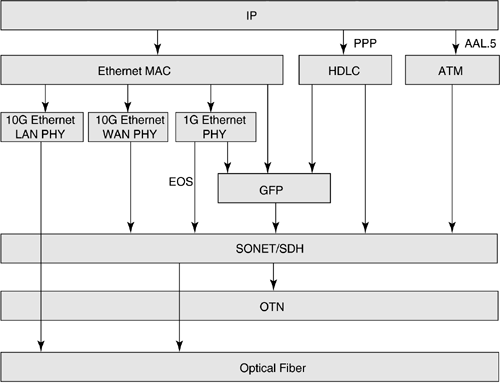
In this regard, one of the most important payloads carried over SONET/SDH is IP. Much of the bandwidth explosion that set the wheels in motion for this book came from the growth in IP services. Hence, our focus is mainly on IP in the rest of this chapter. Figure 3-5 shows different ways of mapping IP packets into SONET/SDH frames. In the following, we discuss some of these mechanisms.
Figure 3-5. Different Alternatives for Carrying IP Packets over SONET
3.4.1 IP over ATM over SONET
The “Classical IP over ATM” solution supports robust transmission of IP packets over SONET/SDH using ATM encapsulation. Under this solution, each IP packet is encapsulated into an ATM Adaptation Layer Type 5 (AAL5) frame using multiprotocol LLC/SNAP encapsulation [Perez+95]. The resulting AAL5 Protocol Data Unit (PDU) is segmented into 48-byte payloads for ATM cells. ATM cells are then mapped into a SONET/SDH frame.
One of the problems with IP-over-ATM transport is that the protocol stack may introduce a bandwidth overhead as high as 18 percent to 25 percent. This is in addition to the approximately 4 percent overhead needed for SONET. On the positive side, ATM permits sophisticated traffic engineering, flexible routing, and better partitioning of the SONET/SDH bandwidth. Despite the arguments on the pros and cons of the method, IP-over-ATM encapsulation continues to be one of the main mechanisms for transporting IP over SONET/SDH transport networks.
3.4.2 Packet over SONET/SDH
ATM encapsulation of IP packets for transport over SONET/SDH can be quite inefficient from the perspective of bandwidth utilization. Packet over SONET/SDH (or POS) addresses this problem by eliminating the ATM encapsulation, and using the Point-to-Point Protocol (PPP) defined by the IETF [Simpson94]. PPP provides a general mechanism for dealing with point-to-point links and includes a method for mapping user data, a Link Control Protocol (LCP), and assorted Network Control Protocols (NCPs). Under POS, PPP encapsulated IP packets are framed using high-Level Data Link Control (HDLC) protocol and mapped into the SONETSPE or SDHVC [Malis+99]. The main function of HDLC is to provide framing, that is, delineation of the PPP encapsulated IP packets across the synchronous transport link. Standardized mappings for IP into SONET using PPP/HDLC have been defined in IETF RFC 2615 [Malis+99] and ITU-T Recommendation G.707 [ITU-T00a].
Elimination of the ATM layer under POS results in more efficient bandwidth utilization. However, it also eliminates the flexibility of link bandwidth management offered by ATM. POS is most popular in backbone links between core IP routers running at 2.5 Gbps and 10 Gbps speeds. IP over ATM is still popular in lower-speed access networks, where bandwidth management is essential.
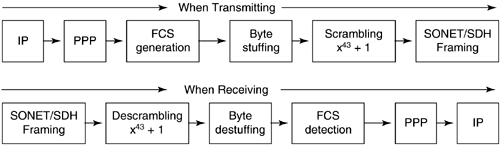
During the initial deployment of POS, it was noticed that the insertion of packets containing certain bit patterns could lead to the generation of the Loss of Frame (LOF) condition. The problem was attributed to the relatively short period of the SONET section (SDH regenerator section) scrambler, which is only 127 bits and synchronized to the beginning of the frame. In order to alleviate the problem, an additional scrambling operation is performed on the HDLC frames before they are placed into the SONET/SDH SPEs. This procedure is depicted in Figure 3-6.
Figure 3-6. Packet Flow for Transmission and Reception of IP over PPP over SONET/SDH
3.4.3 Generic Framing Procedure (GFP)
GFP [ITU-T01b] was initially proposed as a solution for transporting data directly over dark fibers and WDM links. But due to the huge installed base of SONET/SDH networks, GFP soon found applications in SONET/SDH networks. The basic appeal of GFP is that it provides a flexible encapsulation framework for both block-coded [Gorsche+02] and packet oriented [Bonenfant+02] data streams. It has the potential of replacing a plethora of proprietary framing procedures for carrying data over existing SONET/SDH and emerging WDM/OTN transport.
GFP supports all the basic functions of a framing procedure including frame delineation, frame/client multiplexing, and client data mapping [ITU-T01b]. GFP uses a frame delineation mechanism similar to ATM, but generalizes it for both fixed and variable size packets. As a result, under GFP, it is not necessary to search for special control characters in the client data stream as required in 8B/10B encoding,1 or for frame delineators as with HDLC framing. GFP allows flexible multiplexing whereby data emanating from multiple clients or multiple client sessions can be sent over the same link in a point-to-point or ring configuration. GFP supports transport of both packet-oriented (e.g., Ethernet, IP, etc.) and character-oriented (e.g., Fiber Channel) data. Since GFP supports the encapsulation and transport of variable-length user PDUs, it does not need complex segmentation/reassembly functions or frame padding to fill unused payload space. These careful design choices have substantially reduced the complexity of GFP hardware, making it particularly suitable for high-speed transmissions.
In the following section, we briefly discuss the GFP frame structure and basic GFP functions.
3.4.3.1 GFP FRAME STRUCTURE
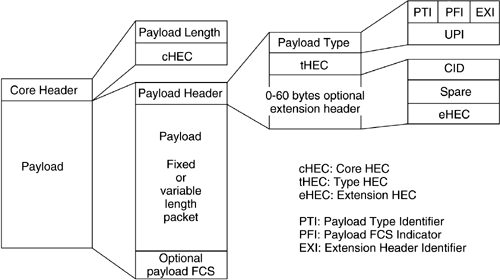
A GFP frame consists of a core header and a payload area, as shown in Figure 3-7. The GFP core header is intended to support GFP-specific data link management functions. The core header also allows GFP frame delineation independent of the content of the payload. The GFP core header is 4 bytes long and consists of two fields:
A 2-byte field indicating the size of the GFP payload area in bytes.
Core Header Error Correction (cHEC) Field
A 2-octet field containing a cyclic redundancy check (CRC) sequence that protects the integrity of the core header.
The payload area is of variable length (0–65,535 octets) and carries client data such as client PDUs, client management information, and so on. Structurally, the payload area consists of a payload header and a payload information field, and an optional payload Frame Check Sequence (FCS) field. The FCS information is used to detect the corruption of the payload.
Payload Header
The variable length payload header consists of a payload type field and a type Header Error Correction (tHEC) field that protects the integrity of the payload type field. Optionally, the payload header may include an extension header. The payload type field consists of the following subfields:
Payload Type Identifier (PTI): This subfield identifies the type of frame. Two values are currently defined: user data frames and client management frames.
Payload FCS Indicator (PFI): This subfield indicates the presence or absence of the payload FCS field.
Extension Header Identifier (EXI): This subfield identifies the type of extension header in the GFP frame. Extension headers facilitate the adoption of GFP for different client-specific protocols and networks. Three kinds of extension headers are currently defined: a null extension header, a linear extension header for point-to-point networks, and a ring extension header for ring networks.
User Payload Identifier (UPI): This subfield identifies the type of payload in the GFP frame. The UPI is set according to the transported client signal type. Currently defined UPI values include Ethernet, PPP (including IP and MPLS), Fiber Channel [Benner01], FICON [Benner01], ESCON [Benner01], and Gigabit Ethernet. Mappings for 10/100 Mb/s Ethernet and digital video broadcast, among others, are under consideration.
Continue Reading This Article
Sign in with a free account to unlock the full article and access the complete MapYourTech knowledge base.
This field contains the client data. There are two modes of client signal payload adaptation defined for GFP: frame-mapped GFP (GFP-F) applicable to most packet data types, and transparent-mapped GFP (GFP-T) applicable to 8B/10B coded signals. Frame-mapped GFP payloads consist of variable length packets. In this mode, client frame is mapped in its entirety into one GFP frame. Examples of such client signals include Gigabit Ethernet and IP/PPP. With transparent-mapped GFP, a number of client data characters, mapped into efficient block codes, are carried within a GFP frame.
3.4.3.2 GFP FUNCTIONS
The GFP frame structure was designed to support the basic functions provided by GFP, namely, frame delineation, client/frame multiplexing, header/payload scrambling, and client payload mapping. In the following, we discuss each of these functions.
Frame Delineation
The GFP transmitter and receiver operate asynchro nously. The transmitter inserts GFP frames on the physical link according to the bit/byte alignment requirements of the specific physical interface (e.g., SONET/SDH, OTN, or dark fiber). The GFP receiver is responsible for identifying the correct GFP frame boundary at the time of link initialization, and after link failures or loss of frame events. The receiver “hunts” for the start of the GFP frame using the last received four octets of data. The receiver first computes the cHEC value based on these four octets. If the computed cHEC matches the value in the (presumed) cHEC field of the received data, the receiver tentatively assumes that it has identified the frame boundary. Otherwise, it shifts forward by 1 bit and checks again. After a candidate GFP frame has been identified, the receiver waits for the next candidate GFP frame based on the PLI field value. If a certain number of consecutive GFP frames are detected, the receiver transitions into a regular operational state. In this state, the receiver examines the PLI field, validates the incoming cHEC field, and extracts the framed PDU.
Client/Frame Multiplexing
GFP supports both frame and client multiplexing. Frames from multiple GFP processes, such as idle frames, client data frames, and client management frames, can be multiplexed on the same link. Client data frames get priority over management frames. Idle frames are inserted when neither data nor management frames are available for transmission.
GFP supports client-multiplexing capabilities via the GFP linear and ring extension headers. For example, linear extension headers (see Figure 3-7) contain an 8-bit channel ID (CID) field that can be used to multiplex data from up to 256 client sessions on a point-to-point link. An 8-bit spare field is available for future use. Various proposals for ring extension headers are currently being considered for sharing GFP payload across multiple clients in a ring environment.
Header/Payload Scrambling
Under GFP, both the core header and the payload area are scrambled. Core header scrambling ensures that an adequate number of 0-1 transitions occur during idle data conditions (thus allowing the receiver to stay synchronized with the transmitter). Scrambling of the GFP payload area ensures correct operation even when the payload information is coincidentally the same as the scrambling word (or its inverse) from frame-synchronous scramblers such as those used in the SONET line layer (SDHRS layer).
Client Payload Mapping
As mentioned earlier, GFP supports two types of client payload mapping: frame-mapped and transparent-mapped. Frame mapping of native client payloads into GFP is intended to facilitate packet-level handling of incoming PDUs. Examples of such client signals include IEEE 802.3 Ethernet MAC frames, PPP/IP packets, or any HDLC framed PDU. Here, the transmitter encapsulates an entire frame of the client data into a GFP frame. Frame multiplexing is supported with frame-mapped GFP. Frame-mapped GFP uses the basic frame structure of a GFP client frame, including the required payload header.
Transparent mapping is intended to facilitate the transport of 8B/10B block-coded client data streams with low transmission latency. Transparent mapping is particularly applicable to Fiber Channel, ESCON, FICON, and Gigabit Ethernet. Instead of buffering an entire client frame and then encapsulating it into a GFP frame, the individual characters of the client data stream are extracted, and a fixed number of them are mapped into periodic fixed-length GFP frames. The mapping occurs regardless of whether the client character is a data or control character, which thus preserves the client 8B/10B control codes. Frame multiplexing is not precluded with transparent GFP. The transparent GFP client frame uses the same structure as the frame-mapped GFP, including the required payload header.
3.4.4 Ethernet over SONET/SDH
As shown in Figure 3-5, there are different ways of carrying Ethernet frames over SONET/SDH, OTN, and optical fiber. Ethernet MAC frames can be encapsulated in GFP frames and carried over SONET/SDH. Also shown in the figure are the different physical layer encoding schemes, including Gigabit Ethernet physical layer, and 10Gigabit Ethernet physical (PHY) layer optimized for LAN and WAN. Gigabit Ethernet physical layer is 8B/10B coded data stream, and it can be encapsulated into GFP frames and carried over SONET/SDH. 10-Gigabit Ethernet WAN PHY is SONET/SDH encoded, and hence it can be directly mapped into STS-192/STM-16 frames.
3.5 SONET/SDH Transparency Services
SONET and SDH have the following notions of transparency built-in, as described in Chapter 2:
Path transparency, as provided by the SONET line and SDH multiplex section layers. This was the original intent of SONET and SDH, that is, transport of path layer signals transparently between PTEs.
SONET line and SDH multiplex section transparency, as provided by the SONET section and SDH regenerator section layers, respectively.
SONET section and SDH regenerator section transparency, as provided by the physical layer.
Of these, only (1) was considered a “user service” within SONET and SDH. There are reasons now to consider (2) and (3) as services, in addition to newer transparency services.
Figure 3-8 shows a typical scenario where transparency services may be desired. Here, two SONET networks (labeled “Domain 1”) are separated by an intervening optical transport network of some type (labeled “Domain 2”). For instance, Domain 1 could consist of two metro networks under a single administration, separated by a core network (Domain 2) under a different administration. The two disjoint parts of Domain 1 are interconnected by provisioning a “link” between network elements NE1 and NE2, as shown. The characteristics of this link depend on the type of transparency desired. In general, transparency allows NE1 and NE2 to use the functionality provided by SONET overhead bytes in various layers. For instance, section transparency allows the signal from NE1 to NE2 to pass through Domain 2 without any overhead information being modified in transit. An all-optical network or a network with transparent regenerators can provide section layer transparency. This service is equivalent to having a dedicated wavelength (lambda) between NE1 and NE2. Thus, the service is often referred to as a lambda service, even if the signal is electrically regenerated within the network. Section transparency allows NE1 and NE2 to terminate the section layer and use the section (and higher layer) overhead bytes for their own purposes.
Figure 3-8. Networking Scenario Used to Define SONET/SDH Transparency Services
If the OC-N to be transported between NE1 and NE2 is the same size (in terms of capacity) as those used within the optical network, then the section transparency service is a reasonable approach. If the optical network, however, deals with signals much larger than these OC-N signals, then there is the potential for inefficient resource utilization. For example, suppose the optical network is composed of DWDM links and switches that can effectively deal with OC-192 signals. A “lambda” in this network could indeed accommodate an OC-12 signal, but only 1/16th of the capacity of that lambda will be used. In such a case, the OC-12 signal has to be multiplexed in some way into an OC-192 signal. But SONET (SDH) multiplexing takes place at the line (multiplex section) layer. Hence, there is no standard way to convey the OC-12 overhead when multiplexing the constituent path signals into an OC-192 signal. This means that section and line overhead bytes presented by NE1 will be modified within Domain 2. How then to transfer the overhead bytes transparently across Domain 2? Before we examine the methods for accomplishing this, it is instructive to look at the functionality provided by overhead bytes and what it means to support transparency.
Tables 3-3 and 3-4 list the overhead bytes available at different layers, the functionality provided and when the bytes are updated (refer to Figures 2-4 and 2-5).
These are repeated in all STS-1 signals within an OC-N. No impact on transparency.
J0 (Trace)
Only conveyed in the 1st STS-1, and covers entire frame. J0 bytes in signals 2–N are reserved for growth, i.e., Z0. Used to identify entire section layer signal.
B1 (Section BIP-8)
Only conveyed in the 1st STS-1, and covers entire frame. B1 bytes in signals 2–N are undefined. B1 byte must be updated if section, line or path layer content changes.
E1 (Orderwire)
F1 (User)
Only conveyed in the 1st STS-1, and covers for entire frame. E1 and F1 in signals 2–N are undefined.
D1-D3 (Section DCC)
Only conveyed in the 1st STS-1, and covers the entire frame. D1-D3 bytes in signals 2–N are undefined.
Table 3-4. SONET Line (SDH Multiplex Section) Overhead Bytes and Functionality
Overhead Bytes
Comments
H1, H2, H3 (Pointer bytes)
These are repeated in all STS-1s within an STS-N.
B2 (Line BIP-8)
This is used for all STS-1s within an STS-N. Must be updated if line or path layer content changes. Used to determine signal degrade conditions.
K1, K2 (APS bytes)
Only conveyed in the 1st STS-1 signal, and covers entire line. This space in signals 2 – N are undefined. This is the line APS functionality.
D4-D12 (Line DCC)
Only conveyed in the 1st STS-1 for the entire line. D4–D12 bytes in signals 2 – N are undefined.
S1 (Synchronization byte)
Only conveyed in the 1st STS-1, and carries the synchronization status message for the entire line. S1 bytes in STS-1 signals 2 – N are reserved for growth (Z1 byte). Note that if a re-multiplexing operation were to take place, this byte cannot be carried through.
M0, M1, (Line, Remote Error indication)
M0 or M1 is conveyed in the Nth STS of the STS-N signal. If N > 1, this byte is called M1. If N = 1, this byte is called M0. When N > 1, the corresponding bytes in signals 1 to N – 1 are reserved for growth (Z2 byte).
E2 (Line order wire)
Only conveyed in the 1st STS-1, and covers the entire line. The E2 bytes in signals 2 – N are undefined.
With standard SONET/SDH path layer multiplexing, the H1–H3 (pointer) bytes must be modified when the clocks are different for the streams to be multiplexed. The B2 byte must be updated when any of the line layer bytes are changed. Also related to timing is the S1 byte, which reports on the synchronization status of the line. This byte has to be regenerated if multiplexing is performed. Thus, it is not possible to preserve all the overhead bytes when the signal from NE1 is multiplexed with other signals within Domain 2. The additional procedures that must be performed to achieve transparency are discussed next.
3.5.1 Methods for Overhead Transparency
We can group the transport overhead bytes into five categories as follows:
Framing bytes A1 and A2, which are always terminated and regenerated
Pointer bytes H1, H2 and H3, which must be adjusted for multiplexing, and the S1 byte
With regard to the network shown in Figure 3-8, the following are different strategies for transparently transporting the general overhead bytes:
Information forwarding: The overhead bytes originating from NE1 are placed into the OC-N signal and remain unmodified in Domain 2.
Information tunneling: Tunneling generally refers to the encapsulation of information to be transported at the ingress of a network in some manner and restoring it at the egress. With respect to Figure 3-8, the overhead bytes originating from NE1 are placed in unused overhead byte locations of the signal transported within Domain 2. These overhead bytes are restored before the signal is delivered to NE2.
As an example of forwarding and tunneling, consider Figure 3-9, which depicts four STS-12 signals being multiplexed into an STS-48 signal within Domain 2. Suppose that the J0 byte of each of these four signals has to be transported transparently. Referring to Table 3-1, it can be noted that the J0 space in signals 2–4 of the STS-48 are reserved, that is, no specific purpose for these bytes is defined within Domain 2. Thus, referring to the structure of the multiplexed overhead information shown in Figure 2-5, the J0 bytes from the second, third, and fourth STS-12 signals can be forwarded unmodified through the intermediate network. This is not true for the J0 byte of the first STS-12, however, since the intermediate network uses the J0 byte in the first STS-1 to cover the entire STS-48 signal (Table 3-1). Hence, the J0 byte of the first STS-12 has to be tunneled by placing it in some unused overhead byte in the STS-48 signal at the ingress and recovering it at the egress.
Figure 3-9. Transparency Example to lllustrate Forwarding and Tunneling
Now, consider the error monitoring bytes, B1 and B2. Their usage is described in detail in section 3.6. Briefly, taking SONET as an example, B1 and B2 bytes contain the parity codes for the section and line portion of the frame, respectively. A node receiving these bytes in a frame uses them to detect errors in the appropriate portions of the frame. According to the SONET specification, B1 and B2 are terminated and regenerated by each STE or LTE, respectively. With regard to the network of Figure 3-8, the following options may be considered for their transport across Domain 2:
Error regeneration: B1 and B2 are simply regenerated at every network hop.
Error forwarding: As before, the B1 and B2 bytes are regenerated at each hop. But instead of simply sending these regenerated bytes in the transmitted frame (as in the previous case), the bytes are XOR’d (i.e., bit wise summed) with the corresponding bytes received. With this process, the B1 or B2 bytes will accumulate all the errors (at the appropriate layer) for the transparently transported signal. The only drawback of this method is that the error counts within Domain 2 would appear artificially high, and to sort out the true error counts, correlation of the errors reported along the transparent signal’s path would be required.
Error tunneling: In this case, the incoming parity bytes (B1 and/or B2) are carried in unused overhead locations within the transport signal in Domain 2. In addition, at each network hop where the bytes are required to be regenerated, the tunneled parity bytes are regenerated and then XOR’d (bit wise binary summation) with the error result that was obtained (by comparing the difference between the received and calculated BIP-8s). In this way, the tunneled parity bytes are kept up to date with respect to errors, and the standard SONET/SDH B1 and B2 bytes are used within Domain 2 without any special error correlation/compensation being performed.
3.5.2 Transparency Service Packages
We have so far looked at the mechanisms for providing transparent transport. From the perspective of a network operator, a more important issue is the determination of the types of transparency services that may be offered. A transparency service package defines which overhead functionality will be transparently carried across the network offering the service. As an example, let us consider the network shown in Figure 3-9 again. The following is a list of individual services that could be offered by Domain 2. These may be grouped in various combinations to create different transparency service packages:
J0 transparency: Allows signal identification across Domain 2.
Section DCC (D1–D3) transparency: Allows STE to STE data communication across Domain 2.
B2 and M0/M1 transparency: Allows line layer error monitoring and indication across Domain 2.
K1 and K2 byte transparency: Allow line layer APS across Domain 2. This service will most likely be used with (3) so that signal degrade conditions can be accurately detected and acted upon.
Line DCC (D4-D12) transparency: Allows LTE to LTE data communication across Domain 2.
E2 transparency: Allows LTE to LTE order wire communication across Domain 2.
Miscellaneous section overhead transparency, that is, E1 and F1.
Whether overhead/error forwarding or tunneling is used is an internal decision made by the domain offering the transparency service, based on equipment capabilities and overhead usage. Note that to make use of equipment capable of transparent services, a service provider must know the overhead usage, termination, and forwarding capabilities of equipment used in the network. For example, the latest release of G.707 [ITU-T00a] allows the use of some of the unused overhead bytes for physical layer forward error correction (FEC). Hence, a link utilizing such a “feature” would have additional restrictions on which bytes could be used for forwarding or tunneling.
3.6 When Things Go Wrong
One of the most important aspects built into optical transport systems is their “self-diagnosis” capability. That is, the ability to detect a problem (i.e., observe a symptom), localize the problem (i.e., find where it originated), and discover the root cause of the problem. In fact, SONET and SDH include many mechanisms to almost immediately classify the root cause of problem. This is done by monitoring the signal integrity between peers at a given layer, and also when transferring a signal from a client (higher) layer into a server (lower) layer (Figure 2-17).
In the following, we first consider the various causes of transport problems. Next, we examine how problems are localized and how signal quality is monitored. Finally, we review the methods and terminology for characterizing problems and their duration.
3.6.1 Transport Problems and Their Detection
Signal monitoring functionality includes the following: continuity supervision, connectivity supervision, and signal quality supervision. These are described next.
3.6.1.1 CONTINUITY SUPERVISION
A fundamental issue in telecommunication is ascertaining whether a signal being transmitted is successfully received. Lack of continuity at the optical or electrical layers in SONET/SDH is indicated by the Loss of Signal (LOS) condition. This may arise from either the failure of a transmitter (e.g., laser, line card, etc.) or break in the line (e.g., fiber cut, WDM failure, etc.). The exact criteria for when the LOS condition is declared and when it is cleared are described in reference [ITU-T00b]. For optical SDH signals, a typical criterion is the detection of no transitions on the incoming signal (before unscrambling) for time T, where 2.3 µs ≤ T ≤ 100 µs. An LOS defect is cleared if there are signal transitions within 125 µs. When dealing with other layers, the loss of continuity is discovered using a maintenance signal known as the Alarm Indication Signal (AIS). AIS indicates that there is a failure further upstream in the lower layer signal. This is described further in section 3.6.2.1.
3.6.1.2 CONNECTIVITY SUPERVISION
Connectivity supervision deals with the determination of whether a SONET/SDH connection at a certain layer has been established between the intended pair of peers. This is particularly of interest if there has been an outage and some type of protection or restoration action has been taken. A trail trace identifier is used for connection supervision. Specifically,
The J0 byte is used in the SONET section (SDH regenerator section) layer. The section trace string is 16 bytes long (carried in successive J0 bytes) as per recommendation G.707 [ITU-T00a].
The J1 byte is used in the SONET/SDH higher-order path layer (e.g., SONET STS-1 and above). The higher-order path trace string could be 16 or 64 bytes long as per recommendation G.707 [ITU-T00a].
The J2 byte is used in the SONET/SDH lower-order path layer (e.g., SONETVT signals). The lower-order path trace string is 16 bytes long as per recommendation G.707 [ITU-T00a].
For details of trail trace identifiers used for tandem connection monitoring (TCM), see recommendations G.707 [ITU-T00a] and G.806 [ITU-T00c]. The usage of this string is typically controlled from the management system. Specifically, a trace string is configured in the equipment at the originating end. An “expected string” is configured at the receiving end. The transmitter keeps sending the trace string in the appropriate overhead byte. If the receiver does not receive the expected string, it raises an alarm, and further troubleshooting is initiated.
3.6.1.3 SIGNAL QUALITY SUPERVISION
Signal quality supervision determines whether a received signal contains too many errors and whether the trend in errors is getting worse. In SONET and SDH, parity bits called Bit Interleaved Parity (BIP) are added to the signal in various layers. This allows the receiving end, known as the near-end, to obtain error statistics as described in section 3.6.3. To give a complete view of the quality of the signal in both directions of a bidirectional line, the number of detected errors at the far-end (transmitting end) may be sent back to the near-end via a Remote Error Indicator (REI) signal.
The following bits and bytes are used for near-end signal quality monitoring under SONET and SDH:
SONET section (SDH regenerator section) layer: The B1 byte is used to implement a BIP-8 error detecting code that covers the previous frame.
SONET line (SDH multiplex section) layer: In the case of SDHSTM-N signals, a BIPN × 24 composed of the 3 STM-1 B2 bytes is used. In the case of SONET STS-N, a BIP N × 8 composed of the N B2 bytes is used. These cover the entire contents of the frame excluding the regenerator section overhead.
SONET path (SDH HOVC) layer: The B3 byte is used to implement a BIP-8 code covering all the bits in the previous VC-3, VC-4, and VC-4-Xc.
SONET VT path (SDH LOVC) layer. Bits 1 and 2 of the V5 byte are used to implement a BIP-2 code covering all the bits in the previous VC-1/2.
SONET/SDH provides the following mechanisms for carrying the REI information. For precise usage, see either T1.105 [ANSI-95a] or G.707 [ITU-T00a].
Multiplex section layer REI: For STM-N (N = 0, 1, 4, 16), 1 byte (M1) is allocated for use as Multiplex Section REI. For STM-N (N = 64 and 256), 2 bytes (M0, M1) are allocated for use as a multiplex section REI. Note that this is in line with the most recent version of G.707 [ITU-T00a].
Path layer REI: For STS (VC-3/4) path status, the first 4 bits of the G1 path overhead are used to return the count of errors detected via the path BIP-8, B3. Bit 3 of V5 is the VT Path (VC-1/2) REI that is sent back to the originating VTPTE, if one or more errors were detected by the BIP-2.
3.6.1.4 ALIGNMENT MONITORING
When receiving a time division multiplexed (TDM) signal, whether it is electrical or optical, a critically important stage of processing is to find the start of the TDM frame and to maintain frame alignment. In addition, when signals are multiplexed together under SONET/SDH, the pointer mechanism needs to be monitored.
Frame Alignment and Loss of Frame (LOF)
The start of an STM-N (OC-3N) frame is found by searching for the A1 and A2 bytes contained in the STM-N (OC-3N) signal. Recall that the A1 and A2 bytes form a particular pattern and that the rest of the frame is scrambled. This framing pattern is continuously monitored against the assumed start of the frame. Generally, the receiver has 625 µs to detect an out-of-frame (OOF) condition. If the OOF state exits for 3 ms or more then a loss of frame (LOF) state will be declared. To exit the LOF state, the start of the frame must be found and remain valid for 3 ms.
Loss of Multiframe
SDH LOVCs and SONET VTs use the multi-frame structure described earlier. The 500 µs multiframe start phase is recovered by performing multiframe alignment on bits 7 and 8 of byte H4. Out-of-multiframe (OOM) is assumed once when an error is detected in the H4 bit 7 and 8 sequence. Multiframe alignment is considered recovered when an error-free H4 sequence is found in four consecutive VC-n (VT) frames.
Pointer Processing and Loss of Pointer (LOP)
Pointer processing in SONET/SDH is used in both the HOVC (STS path) and LOVC (VT path) layers. This processing is important in aligning payload signals (SDHVC or SONET paths) into their containing signals (STM-N/OC-3N). Without correct pointer processing, essentially one per payload signal, the payload signal is essentially “lost.” Hence, pointer values are closely monitored as part of pointer processing [ITU-T00a, ITU-T00b]. A loss of pointer state is declared under severe error conditions.
3.6.2 Problem Localization and Signal Maintenance
Once a problem has been detected, its exact location has to be identified for the purposes of debugging and repair. SONET/SDH provides sophisticated mechanisms to this in the form of Alarm Indication Signals (AIS) and the Remote Defect Indication (RDI). These are described below.
3.6.2.1 ALARM INDICATION SIGNALS
Suppose that there is a major problem with the signal received by an intermediate point in a SONET network. In this case, a special Alarm Indication Signal is transmitted in lieu of the normal signal to maintain transmission continuity. An AIS indicates to the receiving equipment that there is a transmission interruption located at, or upstream, of the equipment originating the AIS. Note that if the AIS is followed upstream starting from the receiver, it will lead to the location of the error. In other words, the AIS signal is an important aid in fault localization. It is also used to deliver news of defects or faults across layers.
A SONETSTE will originate an Alarm Indication Signal-Line (AIS-L) (MSAIS in SDH) upon detection of an LOS or LOF defect. There are two variants of the AIS-L signal. The simplest is a valid section overhead followed by “all ones” pattern in the rest of the frame bytes (before scrambling). To detect AIS-L, it is sufficient to look at bits 6, 7, and 8 of the K2 byte and check for the “111” pattern. A second function of the AIS-L is to provide a signal suitable for normal clock recovery at downstream STEs and LTEs. See [ANSI95a] for the details of the application, removal, and detection of AIS-L.
A SONETLTE will generate an Alarm Indication signal-Path (AIS-P) upon detection of an LOS, LOF, AIS-L, or LOP-P defect. AIS-P (AU AIS in SDH) is specified as “all ones” in the STS SPE as well as the H1, H2, and H3 bytes. STS pointer processors detect AIS-P as “111…” in bytes H1 and H2 in three consecutive frames.
A SONET STS PTE will generate an Alarm Indication signal-VT (AIS-V) for VTs of the affected STS path upon detection of an LOS, LOF, AIS-L, LOP-P, AIS-P, or LOP-V defect. The AIS-V signal is specified as “all ones” in the entire VT, including the V1-V4 bytes. VT pointer processors detect AIS-V as “111…” in bytes V1 and V2 in three consecutive VT superframes.
The SDHAIS signals for its various layers are nearly identical as those of SONET in definition and use as shown in Table 3-5.
3.6.2.2 REMOTE DEFECT INDICATION
Through the AIS mechanism, SONET allows the downstream entities to be informed about problems upstream in a timely fashion (in the order of milliseconds). The AIS signal is good for triggering downstream protection or restoration actions. For quick recovery from faults, it is also important to let the upstream node know that there is a reception problem downstream. The Remote Defect Indication (RDI) signal is used for this purpose. The precise definition of RDI, as per [ANSI95a], is
Table 3-5. SDH AIS Signals by Layer
Layer
Type
AIS Overhead
AIS Activation Pattern
AIS Deactivation Pattern
MSn
MS–AIS
K2, bits 6 to 8
“111”
≠ “111”
VC-3/4
AU-AIS
H1, H2
See Annex A/G.783 [ITU-T00b]
VC-3/4 TCM
IncAIS
N1, bits 1 to 4
“1110”
≠ “1110”
VC-11/12/2
TU–AIS
V1, V2
S11/12/2 (VC-11/12/2)
VC-11/12/2
TU–AIS
V1, V2
See Annex A/G.783 [ITU-T00b]
VC-11/12/2 TCM
IncAIS
N2, bit 4
“1”
“0”
A signal transmitted at the first opportunity in the outgoing direction when a terminal detects specific defects in the incoming signal.
At the line level, the RDI-L code is returned to the transmitting LTE when the receiving LTE has detected an incoming line defect. RDI-L is generated within 100 ms by an LTE upon detection of an LOS, LOF, or AIS-L defect. RDI-L is indicated by a 110 code in bits 6,7,8 of the K2 byte (after unscrambling).
At the STS path level, the RDI-P code is returned to the transmitting PTE when the receiving PTE has detected an incoming STS path defect. There are three classes of defects that trigger RDI-P:
Payload defects: These generally indicate problems detected in adapting the payload being extracted from the STS path layer.
Server defects: These indicate problems in one of the layers responsible for transporting the STS path.
Connectivity defects: This only includes the trace identifier mismatch (TIM) or unequipped conditions.
Table 3-6 shows current use of the G1 byte for RDI-P purposes (consult [ANSI95a] for details).
The remote defect indication for the VT path layer, RDI-V, is similar to RDI-P. It is used to return an indication to the transmitting VTPTE that the receiving VTPTE has detected an incoming VT Path defect. There are three classes of defects that trigger RDI-V:
Table 3-6. Remote Defect Indicator—Path (RDI-P) via the G1 Byte
G1, bit 5
G1, bit 6
G1, bit 7
Meaning
0
1
0
Remote payload defect
0
1
1
No remote defect
1
0
1
Server defect
1
1
0
Remote connectivity defect
Payload defects: These generally indicate problems detected in adapting the payload being extracted from the VT path layer.
Server defects: These generally indicate problems in the server layers to the VT path layer.
Connectivity defects: These generally indicate that there is a connectivity problem within the VT path layer.
For more information, see [ANSI95a] for details. RDI-V uses the Z7 bytes (bits 6 and 7).
One thing to note about RDI signals is that they are “peer to peer” indications, that is, they stay within the layer that they are generated. The AIS and RDI signals form the “fast” notification mechanisms for protection and restoration, that is, these are the primary triggers. Examples of their usage are given in the next chapter. The RDI signals in various SDH layers are nearly identical to those of SONET and they are summarized in Table 3-7.
Table 3-7. RDI Signals for Various SDH Layers
Layer
Type
RDI/ODI Overhead
RDI/ODI Activation Pattern
RDI/ODI Deactivation Pattern
MSn
RDI
K2, bits 6 to 8
“110”
≠ “110”
S3D/4D (VC-3/4 TCM option 2)
RDI
N1, bit 8, frame 73
“1”
“0”
S11/12/2 (VC-11/12/2)
RDI
V5, bit 8
“1”
“0”
S11D/12D/2D (VC-11/12/2 TCM)
RDI
N2, bit 8, frame 73
“1”
“0”
3.6.3 Quality Monitoring
3.6.3.1 BLIPS AND BIPS
The bit error rates are typically extremely low in optical networks. For example, in 1995, the assumed worst-case bit error rate (BER) for SONET regenerator section engineering was 10-10, or one error per 10 billion bits. Today, that would be considered quite high. Hence, for error detection in a SONET frame, we can assume very few bit errors per frame.
As an example, the number of bits in an STS-192 frame is 1,244,160 (9 rows × 90 columns per STS-1 x 8 bits/byte × 192 STS-1). With a BER of 10-10, it can be expected that there will be one bit error in every 8038 frames. The probability of two errors in the same frame is fairly low. Since the bit rate of an STS-192 signal is 10 Gbps (or 1010 bits per second), a BER of 10-10 gives rise to one bit error every second on the average. This is why a BER of 10-10 is considered quite high today.
Figure 3-10 shows the general technique used in SONET and SDH for monitoring bit errors “in-service” over various portions of the signal. This method is known as the Bit Interleaved Parity 8 Bits, or BIP-8 for short. Although the name sounds complex, the idea and calculation are rather simple. In Figure 3-10, X1-X5 represents a set of bytes that are being checked for transmission errors. For every bit position in these bytes, a separate running tally of the parity (i.e., the number of 1s that occur) is kept track of. The corresponding bit position of the BIP-8 byte is set to “1” if the parity is currently odd and a zero if the parity is even. The BIP-8 byte is sent, typically in the following frame, to the destination. The destination recomputes the BIP-8 code based on the contents of the received frame and compares it with the BIP-8 received. If there are no bit errors, then these two codes should match. Figure 3-10(b) depicts the case where one of the bytes, X2, encounters a single bit error during transmission, that is, bit 2 changes from 1 to 0. In this case, the received BIP-8 and the recomputed BIP-8 differ by a single bit and, in fact, the number of differing bits can be used as an estimate of the number of bit errors.
Figure 3-10. Example of BIP-8 Calculation and Error Detection
Note that the BIP-8 technique works well under the assumption of low bit error rates. The study of general mechanisms for error detection and correction using redundant information bits is known as algebraic coding theory (see [Lin+83]).
BIP-8 is used for error monitoring in different SONET/SDH layers. At the SONET section layer, the B1 byte contains the BIP-8 calculated over all the bits of the previous STS-N frame (after scrambling). The computed BIP-8 is placed in the B1 byte of the first STS-1 (before scrambling). This byte is defined only for the first STS-1 of an STS-N signal. SDH uses this byte for the same purpose. Hence, the BIP-8 in this case is calculated over the entire SONET frame and covers a different number of bytes for different signals, for example, STS-12 vs. STS-192.
At the SONET line layer, BIP-8 is calculated over all the bits of the line overhead and the STS-1 SPE (before scrambling). The computed BIP-8 is placed in the B2 byte of the next STS-1 frame (before scrambling). This byte is separately computed for all the STS-1 signals within an STS-N signal. These NBIP-8 bytes are capable of detecting fairly high bit error rates, up to 10-3. To see this, consider an STS-1 line signal (i.e., an STS-1 frame without section layer overhead). The number of bytes in this signal is 804 (9 rows × 90 columns – 6 section bytes). Each bit in the line BIP-8 code is used to cover 804 bits (which are in the corresponding bit position of the 804 bytes in the line signal). Since a BER of 10-3 means an average of one bit error every 1000 bits, there will be less than one bit error in 804 bits (on the average). This, the line BIP-8 code is sufficient for detecting these errors. Note, however, that BIP-8 (and any parity based error detection mechanism) may fail if there are multiple, simultaneous bit errors.
At the STS Path level, BIP-8 is calculated over all the bits of the previous STS SPE (before scrambling) and carried in the B3 path overhead byte. SDH uses this byte for the same purpose but excludes the fixed stuff bytes in the calculation. The path BIP-8, like the section BIP-8, covers a different number of bytes depending on the size of the STS path signal, that is, STS-3 vs. STS-12.
At the VT path level, 2 bits of the VT path level overhead byte V5 are used for carrying a BIP-2. The technique for this is illustrated in Figure 3-11. To save on overhead, the parity counts over all the odd and the even bit positions are combined and represented by the two bits of the BIP-2 code, respectively. Recall that the VTSPE is a multiframe spanning four SONET frames. The BIP-2 is calculated over all bytes in the previous VTSPE, including all overhead but the pointers (Figure 3-11).
Figure 3-11. BIP Calculation at the VT Path Level
Let us examine how effective the BIP-2 code is. The number of bits in the VT1.5 SPE is 832 ([(9 rows × 3 columns) – 1 pointer byte] × 8 bits/byte × 4 frames per SPE). Each bit of the BIP-2 code covers half the bits in the VT1.5 SPE, that is, 416 bits. Hence, BIP-2 can handle error rates of 1 in 500 bits (BER between 10-2 and 10-3). Now, a VT6 is four times the size of the VT1.5. In this case, each parity bit covers 1664 bits, handling a BER slightly worse than 10-4.
3.6.4 Remote Error Monitoring
The error monitoring capabilities provided by SONET and SDH enables the receiver to know the error count and compute the BER on the received signal at various layers. Based on this information, it is useful to let the sender learn about the quality of the signal received at the other end. The following mechanisms are used for this purpose.
The STS-1 line REI (M0 byte) is used by the receiver to return the number of errored bits detected at the line layer to the sender. The receiver arrives at this number by considering the difference between the received and the recomputed BIP-8 (B2) codes. In the case of an STS-N signal, the M1 byte is used for conveying the REI information. Clearly, up to 8 × N errors could be detected with STS-NBIP-8 codes (as each STS-1 is covered by its own BIP-8). But only a count of at most 255 can be reported in the single M1 byte. Thus, in signals of OC-48 and higher rates, the number 255 is returned when 255 or more errors are detected.
At the path layer, the receiver uses the first four bits of the G1 path overhead to return the number of errors detected (using the path BIP-8) to the sender. At the VT path layer, the receiver uses bit 3 of the V5 byte to indicate the detection of one or more errors to the sender.
3.6.5 Performance Measures
When receiving word of a problem, one is inclined to ask some general questions such as: “How bad is it? “How long has it been this way?” and “Is it getting worse or better?” The following terminology is used in the transport world. An anomaly is a condition that gives the first hint of possible trouble. A defect is an affirmation that something has indeed gone wrong. A failure is a state where something has truly gone wrong. Whether an event notification or an alarm is sent to a management system under these conditions is a separate matter. Performance parameters in SONET and SDH are used to quantify these conditions.
A SONET or an SDH network element supports performance monitoring (PM) according to the layer of functionality it provides. A SONET network element accumulates PM data based on overhead bits at the Section, Line, STS Path, and VT Path layers. In addition, PM data are available at the SONET Physical layer using physical parameters. The following is a summary of different performance parameter defined in SONET. Similar performance parameters are also monitored and measured in SDH. For a detailed treatment on PM parameters on SONET refer to [Telcordia00].
Physical Layer Performance Parameters
The physical layer performance measurement enables proactive monitoring of the physical devices to facilitate early indication of a problem before a failure occurs. Several physical parameters are measured, including laser bias current, optical power output by the transmitter, and optical power at the receiver. Another important physical layer parameter is the Loss of Signal (LOS) second, which is the count of 1-second intervals containing one or more LOS defects.
Section Layer Performance Parameters
The following section layer performance parameters are defined in SONET. Note that all section layer performance parameters are defined for the near-end. There are no far-end parameters at the Section layer.
Code Violation(CV-S): The CV-S parameter is a count of BIP errors detected at the section layer. Up to eight section BIP errors can be detected per STS-N frame.
Errored Second(ES-S): The ES-S parameter is a count of the number of 1 second intervals during which at least one section layer BIP error was detected, or an SEF (see below) or LOS defect was present.
Errored Second Type A(ESA-S) andType B(ESB-S): ESA-S is the count of 1-second intervals containing one CV-S, and no SEF or LOS defects. ESB-S is the count of 1-second intervals containing more than one but less than X CV-S errors, and no SEF or LOS defects. Here, X is a user-defined number.
Severely Errored Second(SES-S): The SES-S parameter is a count of 1-second intervals during which K or more Section layer BIP errors were detected, or an SEF or LOS defect was present. K depends on the line rate and can be set by the user.
Severely Errored Frame Second(SEFS-S): The SEFS-S parameter is a count of 1-second intervals during which an SEF defect was present. An SEF defect is detected when the incoming signal has a minimum of four consecutive errored frame patterns. An SEF defect is expected to be present when an LOS or LOF defect is present. But there may be situations when this is not the case, and the SEFS-S parameter is only incremented based on the presence of the SEF defect.
Line Layer Performance Parameters
At the SONET line layer, both near-end and far-end parameters are monitored and measured. Far-end line layer performance is conveyed back to the near-end LTE via the K2 byte (RDI-L) and the M0 or M1 byte (REI-L). Some of the important near-end performance parameters are defined below. The far-end parameters are defined in a similar fashion.
Code Violation(CV-L): The CV-L parameter is a count of BIP errors detected at the line layer. Up to 8NBIP errors can be detected per STS-N frame.
Errored Second(ES-L): The ES-L parameter is a count of 1-second intervals during which at least one line layer BIP error was detected or an AIS-L defect is present.
Errored Second Type A(ESA-L) andType B(ESB-L): ESA-L is the count of 1-second intervals containing one CV-L error and no AIS-L defects. ESB-L is the count of 1-second intervals containing X or more CV-L errors, or one or more AIS-L defects. Here, X is a user-defined number.
Severely Errored Second(SES-L): The SES-L parameter is a count of 1-second intervals during which K or more line layer BIP errors were detected, or an AIS-L defect is present. K depends on the line rate and can be set by the user.
Unavailable Second(UAS-L): Count of 1-second intervals during which the SONET line is unavailable. The line is considered unavailable after the occurrence of 10 SES-Ls.
AIS Second(AISS-L): Count of 1-second intervals containing one or more AIS-L defects.
Path Layer Performance Parameters
Both STS path and VT path performance parameters are monitored at the path layer. Also, both near-end and far-end performance parameters are measured. Far-end STS path layer performance is conveyed back to the near-end STS PTE using bits 1 through 4 (REI-P) and 5 through 7 (RDI-P) of the G1 byte. Far-end VT path layer performance is conveyed back to the near-end VTPTE using bit 3 of the V5 byte (REI-V), and either bits 5 through 7 of the Z7 byte or bit 8 of the V5 byte (RDI-V). Some of the important near-end STS path performance parameters are defined below. The far-end parameters are defined in a similar fashion.
Code Violation(CV-P): Count of BIP-8 errors that are detected at the STS-path layer.
Errored Second(ES-P): Count of 1-second intervals containing one or more CV-P errors, one or more AIS-P, LOP-P, TIM-P, or UNEQ-P defects.
Errored Second Type A(ESA-P) andType B(ESB-P): ESA-P is the count of 1-second intervals containing one CV-P error and no AIS-P, LOP-P, TIM-P, or UNEQ-P defects. ESB-P is the count of 1-second intervals containing more than one but less than X CV-P errors and no AIS-P, LOP-P, TIM-P, or UNEQ-P defects. Here, X is a user-defined number.
Severely Errored Second(SES-P): Count of 1-second intervals containing X or more CV-P errors, one or more AIS-P, LOP-P, TIM-P, or UNEQ-P defects. Here, X is a user-defined number.
Unavailable Second(UAS-P): Count of 1-second intervals during which the SONET STS-path is unavailable. A path is considered unavailable after the occurrence of 10 SESs.
Pointer Justification Counts: To monitor the adaptation of the path payloads into the SONET line, the pointer positive and negative adjustment events are counted. The number of 1-second intervals during which a pointer adjustment event occurs is also kept track of.
3.7 Summary
SONET and SDH-based optical transport networks have been deployed extensively. It is therefore important to understand the fundamentals of these technologies before delving into the details of the control plane mechanisms. After all, the optical network control plane is a relatively recent development. Its primary application in the near term will be in SONET/SDH networks. In this context, it is vital to know about the low-level control mechanisms that already exist in SONET and SDH and how they help in building advanced control plane capabilities. The next chapter continues with a description of another key topic relevant to the control plane, that is, protection and restoration mechanisms in SONET and SDH networks. Following this, the subject of modern optical control plane is dealt with in earnest.
Optical networking engineer with nearly two decades of experience across DWDM, OTN, coherent optics, submarine systems, and cloud infrastructure. Founder of MapYourTech.
Read full bio →
Everything you enjoy here — now fits right in your pocket. Whether you're on the commute, waiting at the lab, or unwinding on the couch — keep learning on the go.