
Learn, Simulate & Designthe best of optical networking.
Technical Articles to build your foundation, Courses to go deeper, Simulators and Calculators to design and practice, and Books based on industry experience — everything you need to excel at optical networking, in one place.
Pick Your Path — We'll Show You Where to Begin
Four roles, four starting points. Each path sequences the courses, tools, and references that match your work — so you begin at the right depth on day one.
If none fits exactly, start with the Student path — its opening courses are free.
What Engineers Say About MapYourTech
Real feedback from engineers using the platform for design decisions, career growth, and daily reference
"OSNR calculator saved me hours of spreadsheet work"
Used the OSNR simulator and link budget calculator for an actual network design. Got results I could present directly in our engineering proposal.
"OTN course directly accelerated my promotion"
Completed OTN and coherent optics courses, earned certificates, added to LinkedIn. Within two months, a recruiter reached out about a senior role.
"The bridge between theory and real deployments"
Unlike traditional academic texts, focuses on operational, maintenance, and development aspects engineers encounter daily.
"Unlocked automation methods I didn't know existed"
After 18 years in telecom on SDH, IP/MPLS, and DWDM, MapYourTech unlocked automation methods that helped me reduce errors and speed operations across our production network.
"Career intelligence helped me negotiate a better role"
Practical information that helps professionals learn, excel, and advance. Salary benchmarks and interview prep gave me real negotiating power.
"Straight to the point — no filler content"
Written content I can read at my own pace. Real examples with code. No hour-long videos. Perfect for busy engineers who need answers during live troubleshooting.
Optical engineering tools, in your pocket.
Native iOS apps that put the platform, calculators and trace tools you use on the bench onto your phone — built by the same engineers behind MapYourTech.
The full MapYourTech website on your phone — articles, courses and tools, all in one app.
Open any .sor trace — event classification, A/B span loss, ORL and bidirectional splice loss. PDF reports, offline.
Ask questions, share what you're learning, and connect with engineers across optical networking.
Simulators Built on Real Network Experience
Run OSNR budgets, simulate OTDR traces, model Raman tilt, design network topologies, optimize channel power — 19+ browser-based tools with validated physics.
Articles Free

-
Free
-
August 1, 2026

-
Free
-
August 1, 2026

-
Free
-
August 1, 2026

-
Free
-
July 25, 2026

-
Free
-
July 21, 2026

-
Free
-
July 20, 2026

-
Free
-
July 18, 2026
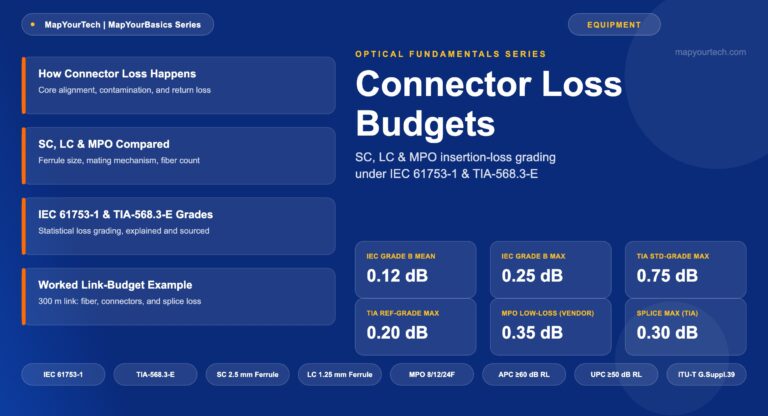
-
Free
-
July 11, 2026
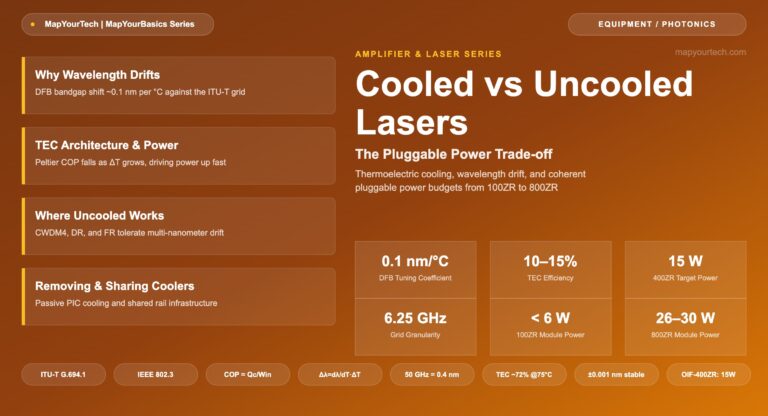
-
Free
-
July 11, 2026
Articles Premium

-
Premium
-
August 1, 2026

-
Premium
-
August 1, 2026

-
Premium
-
August 1, 2026

-
Premium
-
August 1, 2026

-
Premium
-
August 1, 2026

-
Premium
-
July 31, 2026

-
Premium
-
July 26, 2026

-
Premium
-
July 26, 2026

-
Premium
-
July 26, 2026
Courses Free
DWDM Technology
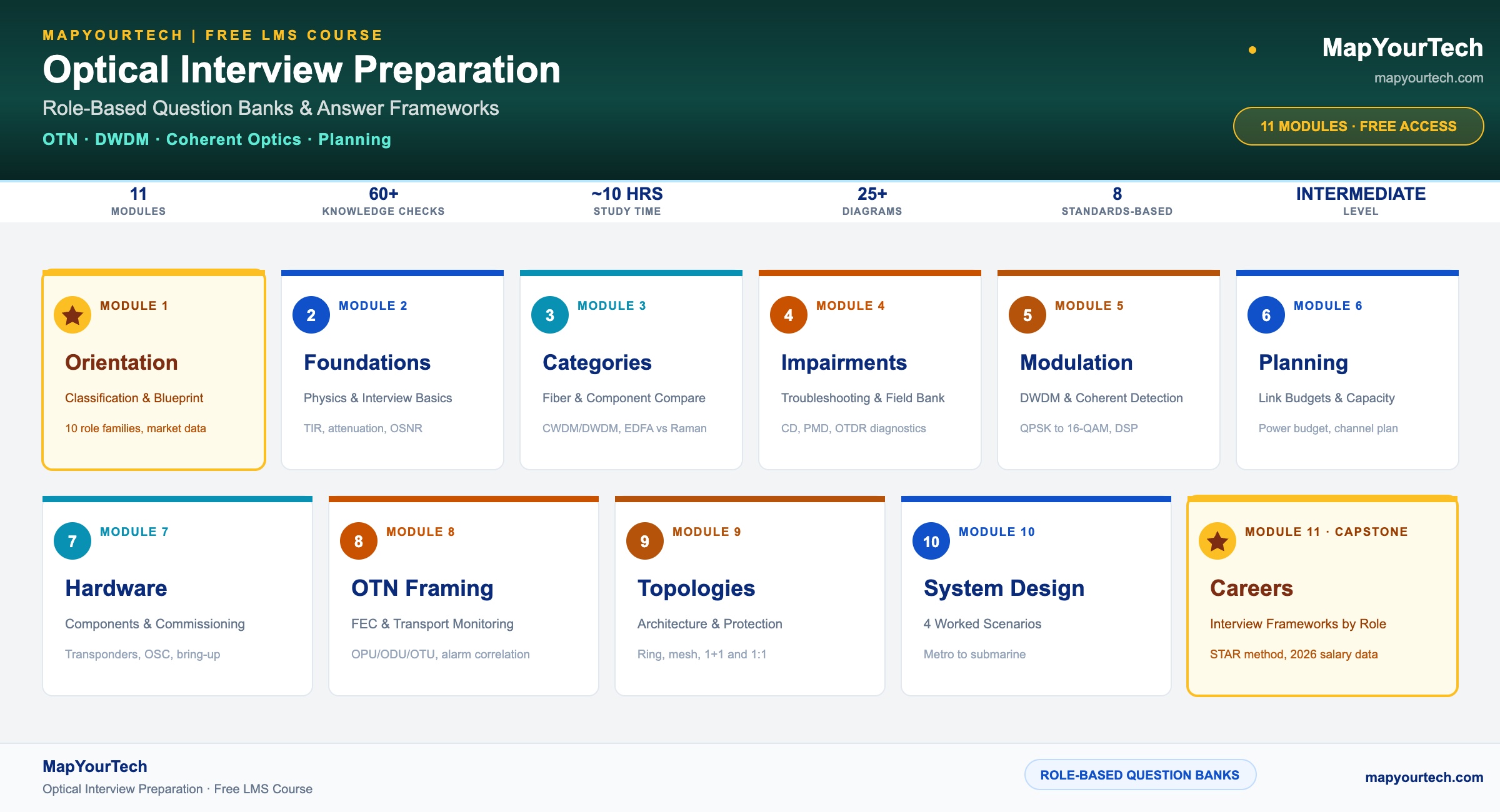
-
104 Lessons
Advanced Technologies

-
42 Lessons
Optical Network Fundamentals

-
42 Lessons
DWDM Technology
-
61 Lessons
Advanced Technologies
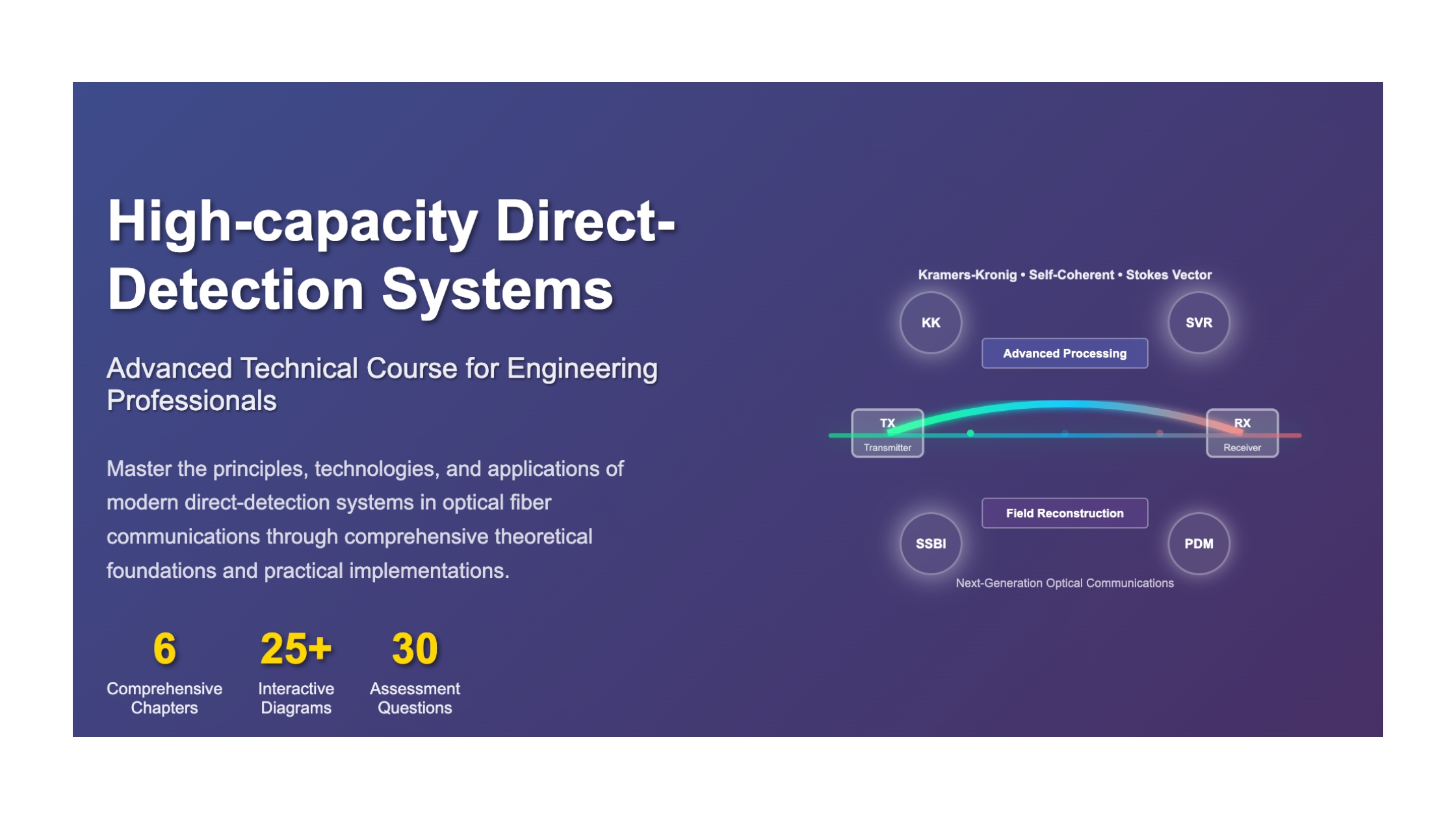
-
51 Lessons
Advanced Technologies

-
44 Lessons
Courses Premium
Advanced Technologies
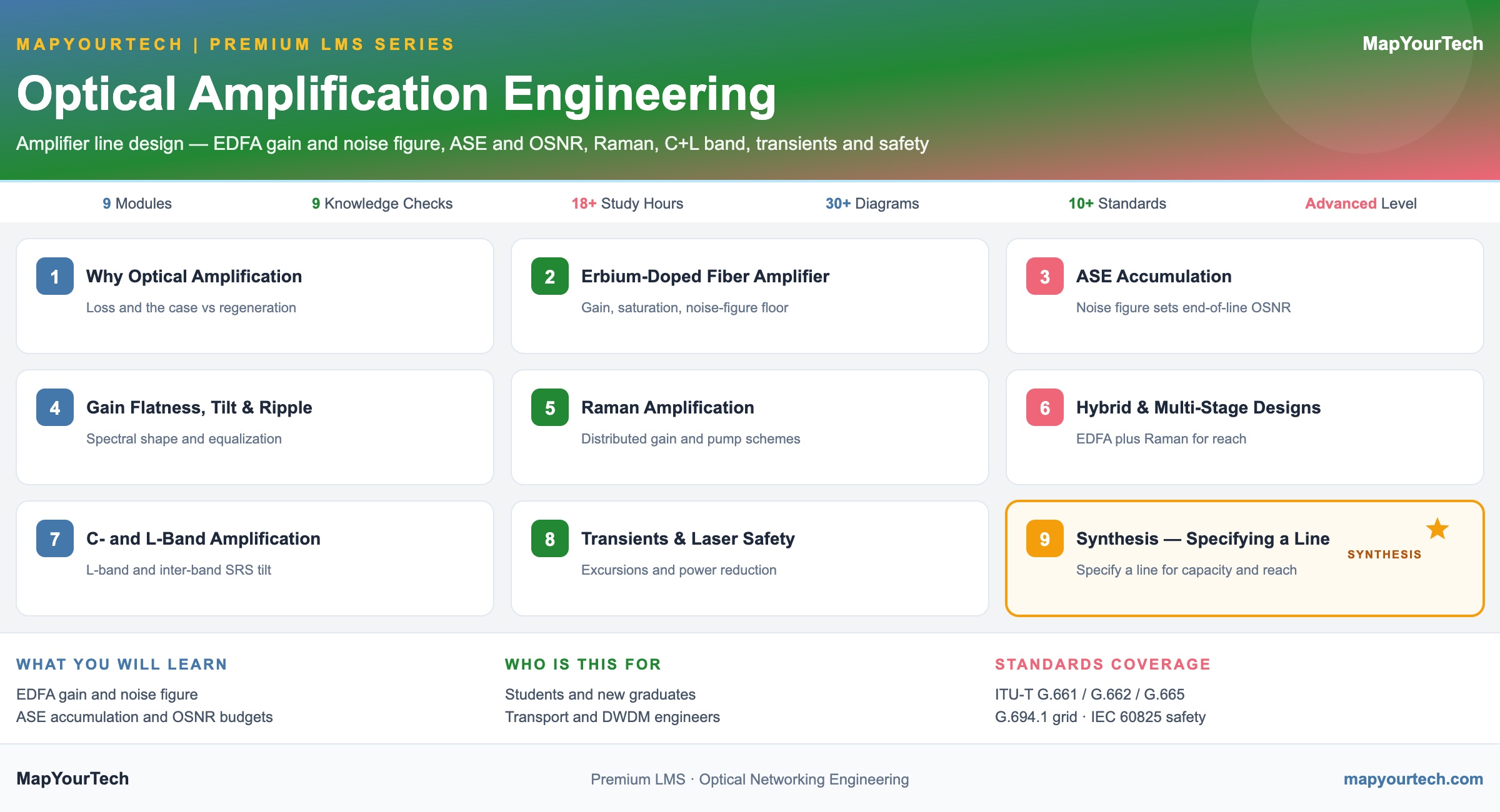
-
82 Lessons
Interview Preparation
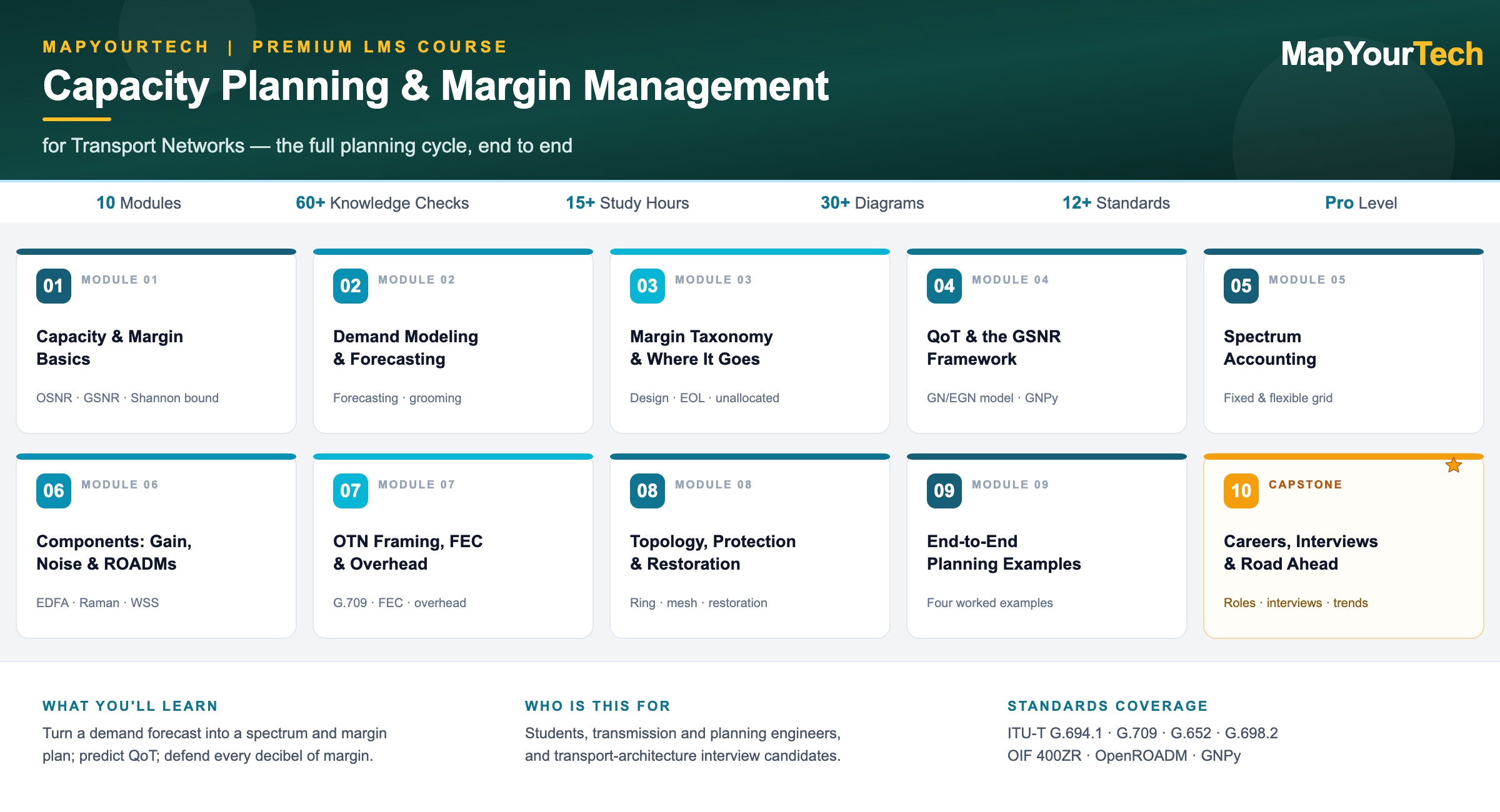
-
100 Lessons
Network Architecture & Design
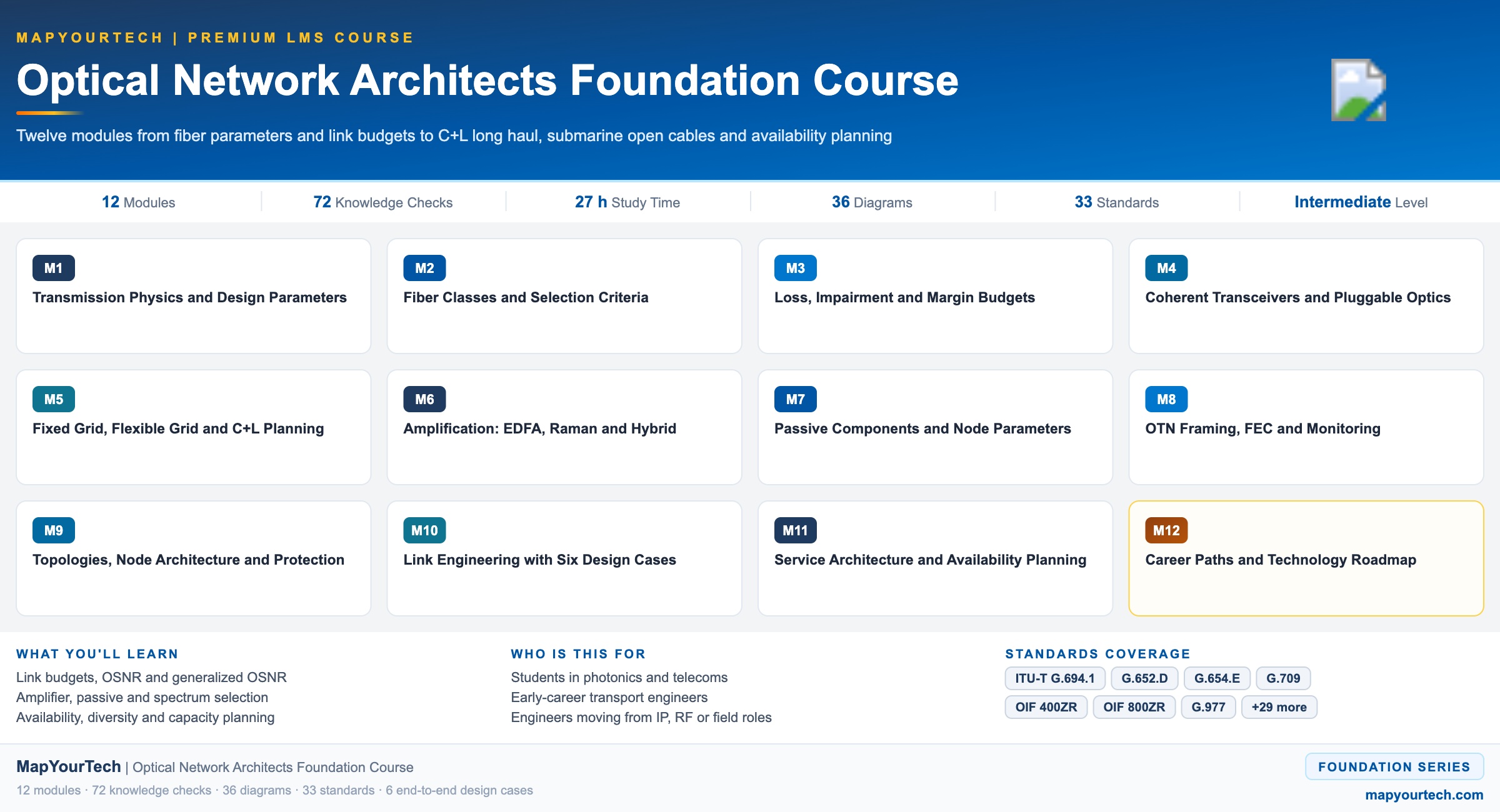
-
121 Lessons
Advanced Technologies
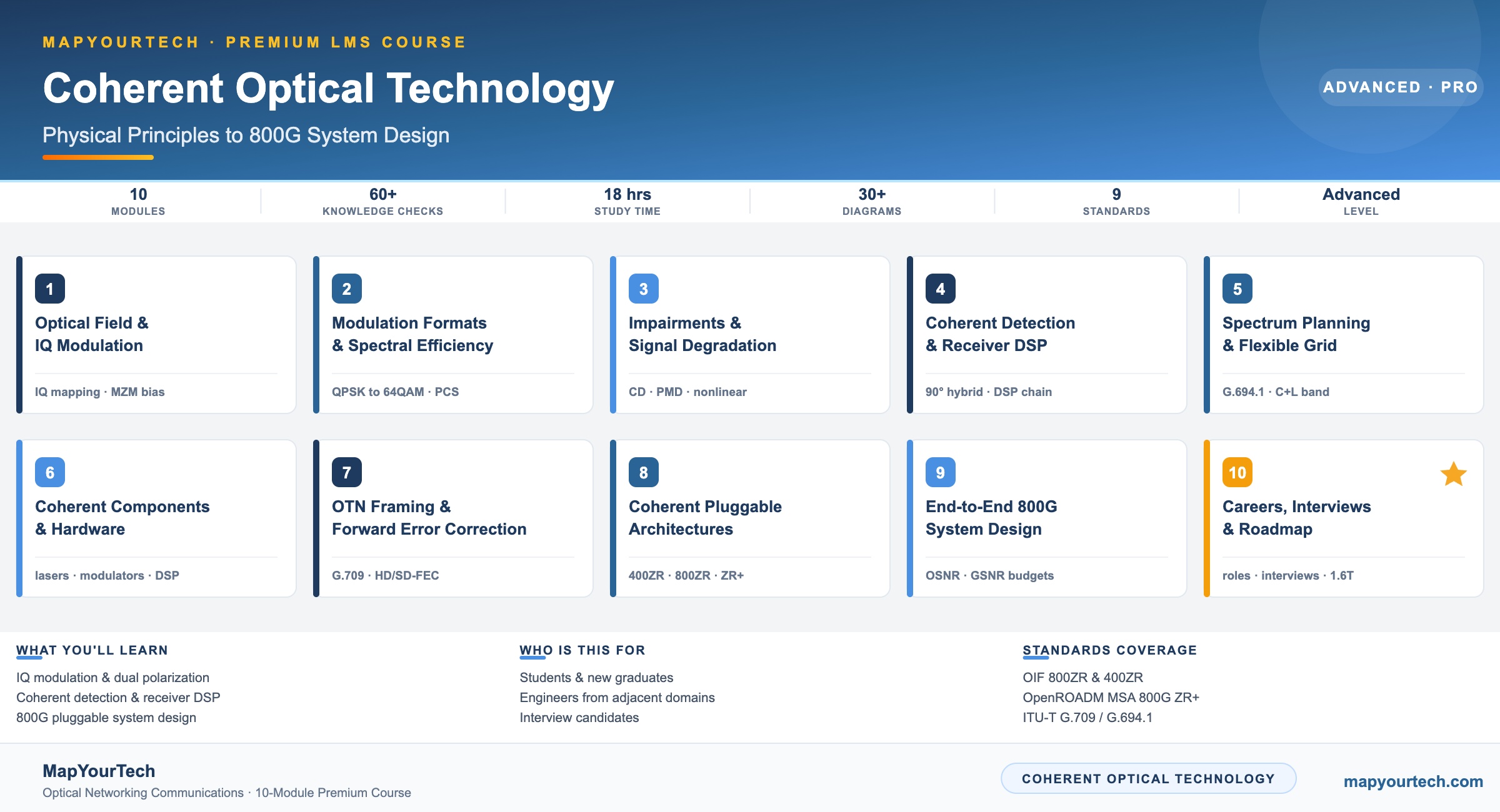
-
101 Lessons
Advanced Technologies
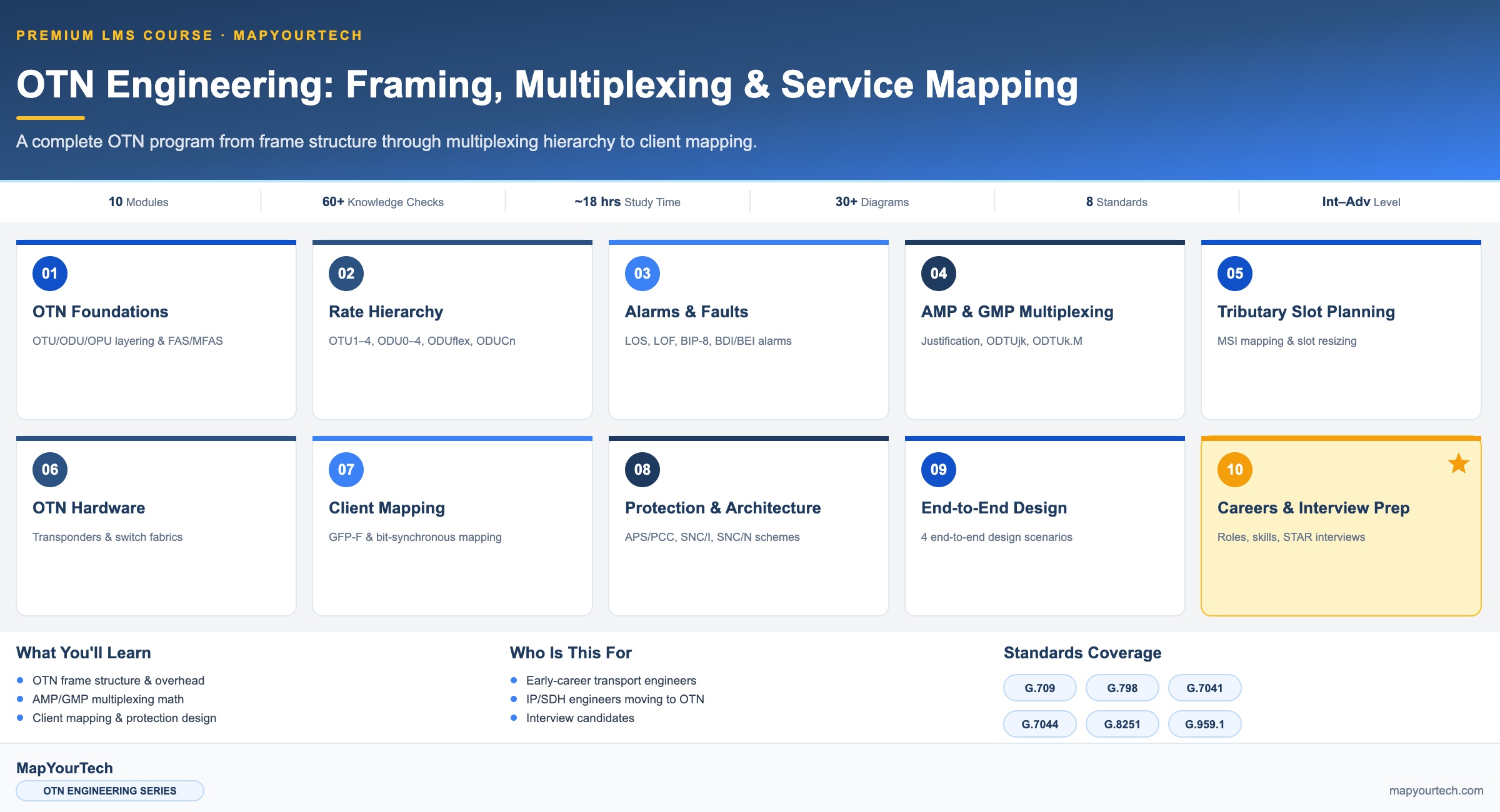
-
91 Lessons
Advanced Technologies
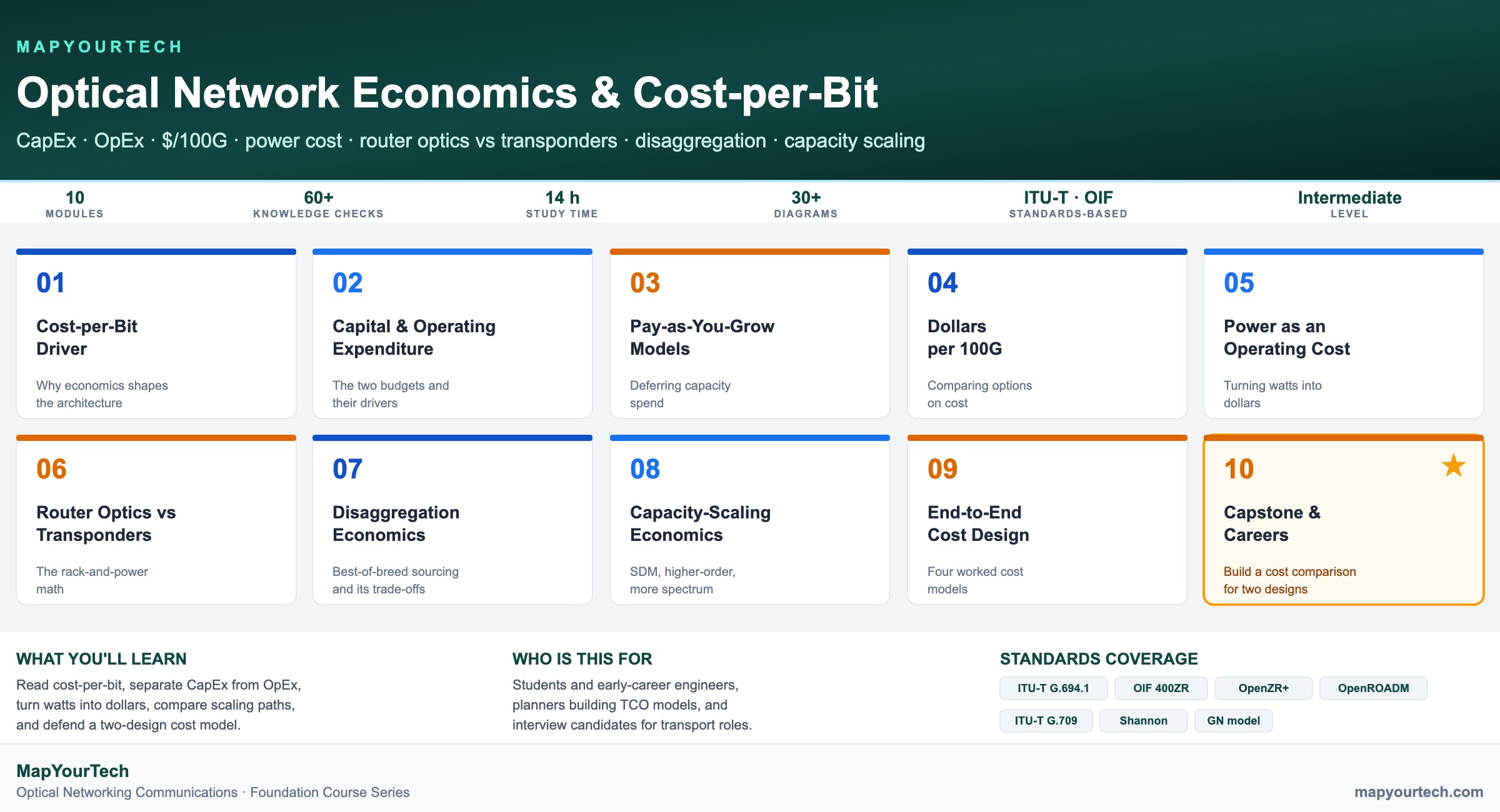
-
91 Lessons
Learning Paths Careers &
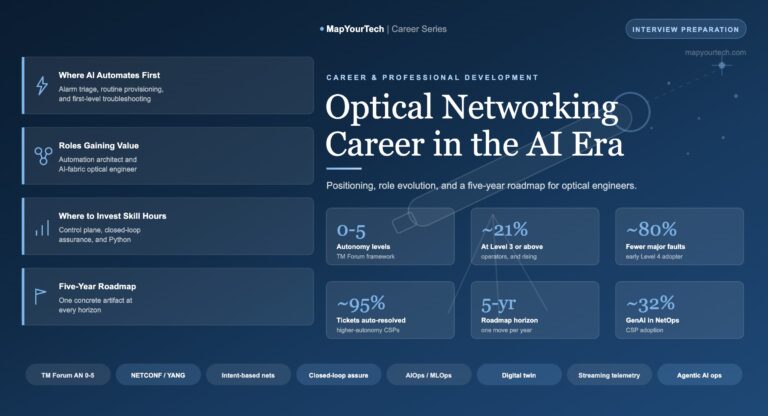
-
Premium
-
July 9, 2026

-
Premium
-
July 5, 2026
-
Premium
-
May 25, 2026
-
Premium
-
May 25, 2026
-
Premium
-
May 25, 2026

-
Premium
-
May 25, 2026
-
Premium
-
May 25, 2026
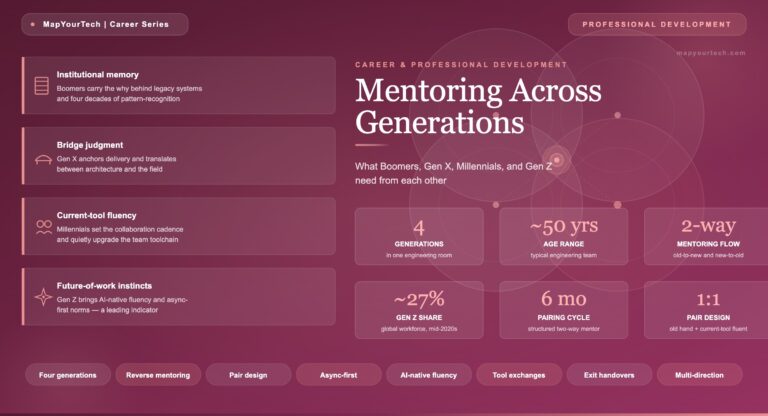
-
Premium
-
May 25, 2026
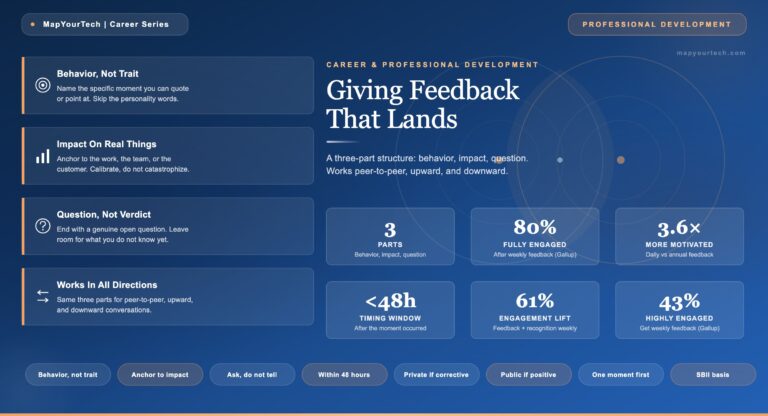
-
Premium
-
May 25, 2026
Why Engineers Choose MapYourTech
Built on 18+ years of hands-on network engineering — every tool, course, and article is grounded in practical knowledge from designing, commissioning, and operating live optical networks.
Field-Validated Accuracy
Every spec verified against ITU-T standards and real deployment data
Real Engineering Tools
19+ simulators like OSNR vs GOSNR and MapYourOTDR — not videos, not PDFs
Find Answers Fast
Searchable text-first format — 931+ articles structured as engineering references
Always Current
800G, 1.6T, C+L band, CPO — tracks latest standards as the industry moves
Certified Learning Paths
64+ courses with assessments and LinkedIn-shareable certificates — fundamentals to advanced
Vendor-Neutral Since 2011
No marketing spin — real-world experience trusted by engineers at tier-1 carriers worldwide
Books by MapYourTech
Three books, one author — founder Sanjay Yadav, 18+ years in optical networking · 800+ copies sold

Optical Network Communications: An Engineer's Perspective
View Details
Automation For Network Engineers Using Python And Jinja2
4.910 ratings · Amazon View Details
Practical Guide For Cracking Optical Interviews
View DetailsKnow Your Worth. Win Your Interview. Read the Market.
Salary benchmarks worldwide, real interview questions with expert answers, and industry adoption signals — built specifically for optical networking professionals.
The Only Optical Networking Reference You’ll Need
The decisions that set a career happen without supervision: an alarm nobody else has seen, a design you have to defend, a claim you have to reject on your own evidence.
One complete study per topic, not an introduction to five.
Every value checked against ITU-T, IEEE, IETF or OIF text.
The founder’s own 30,000+ hours designing and operating live networks.
No reference promises you a promotion or a passed design review, and nothing here replaces measuring your own fiber. What this one does promise: every value here was earned before it was written — 30,000+ hours on live networks, checked against the standards — so when it’s your call to make, you have everything you need to excel.
An engineer in design or operations spends roughly 1,800 working hours a year on decisions like those. Ten-seat team licenses run $2,250 a year; your own annual seat starts at $135 — under $0.08 per working hour.
Set this against the cost of one wrong span decision on your next project.
A simple way to choose — start Free to build fundamentals · pick Premium for the full working reference and simulators · pick Premium Pro if you design networks, prepare for interviews, or negotiate compensation.
The per-seat rate drops below the individual price as seats grow. We invoice your company and accept purchase orders.
New! 48hr Premium Pro Plan
Experience everything MapYourTech offers — full Premium Pro access for 48 hours. Try before you subscribe!
Before You Decide — Read This
Honest answers to the questions engineers ask