
SDH/SONET:Maintenance and Performance Events
We know SDH/SONET is older technology now but just have a glimpse for the revision of basic FM process:
SDH SONET MAINTENANCE
SDH and SONET transmission systems are robust and reliable; however they are vulnerable to several effects that may cause malfunction. These effects can be clas- sified as follows:
- Natural causes: This include thermal noise, always present in regeneration systems; solar radiation; humidity and Raleigh fading in radio systems; hardware aging; degraded lasers; degradation of electric connections; and electrostatic discharge.
- A network design pitfall: Bit errors due to bad synchronization in SDH. Timing loops may collapse a transmission network partially, or even completely.
- Human intervention: This includes fiber cuts, electrostatic discharges, power failure, and topology modifications.
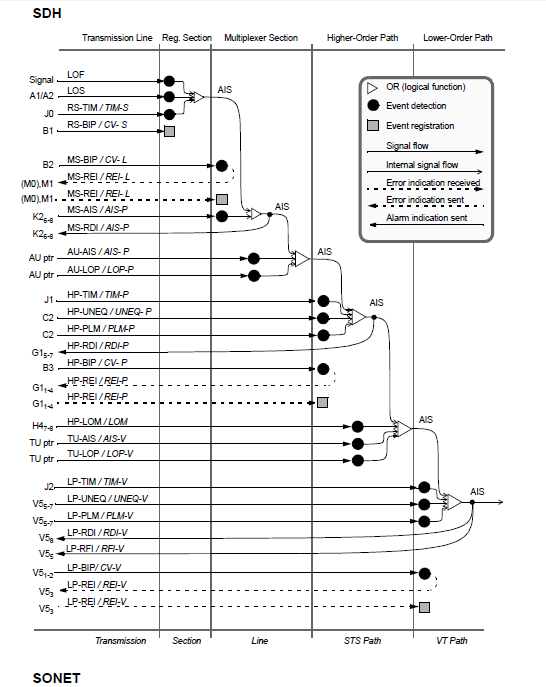
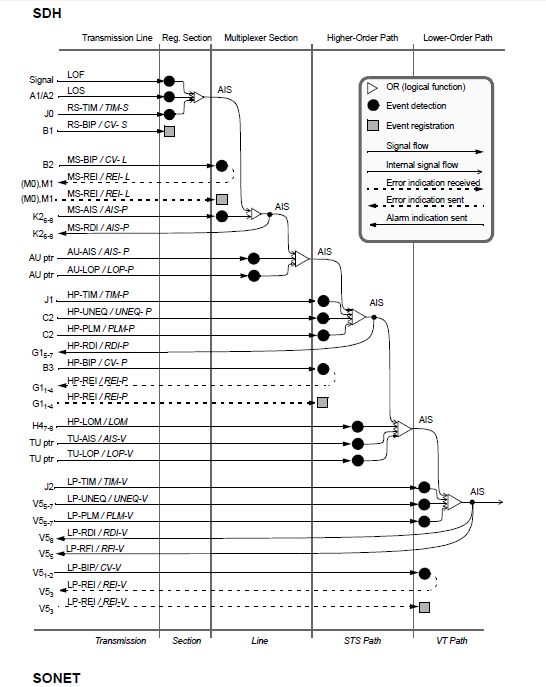
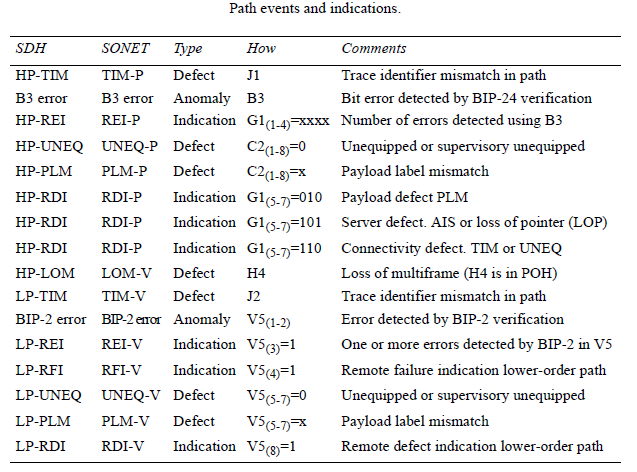
Anomalies and defects management. (In regular characters for SDH; in italic for SONET.)
All these may produce changes in performance, and eventually collapse transmission services.
SDH/SONET Events
SDH/SONET events are classified as anomalies, defects, damage, failures, and alarms depending on how they affect the service:
- Anomaly: This is the smallest disagreement that can be observed between mea- sured and expected characteristics. It could for instance be a bit error. If a single anomaly occurs, the service will not be interrupted. Anomalies are used to monitor performance and detect defects.
Defect: A defect level is reached when the density of anomalies is high enough to interrupt a function. Defects are used as input for performance monitoring, to con- trol consequent actions, and to determine fault causes.
- Damage or fault: This is produced when a function cannot finish a requested action. This situation does not comprise incapacities caused by preventive maintenance.
- Failure: Here, the fault cause has persisted long enough so that the ability of an item to perform a required function may be terminated. Protection mechanisms can now be activated.
- Alarm: This is a human-observable indication that draws attention to a failure (detected fault), usually giving an indication of the depth of the damage. For example, a light emitting diode (LED), a siren, or an e-mail.
- Indication: Here events are notified upstream to the peer layer for performance monitoring and eventually to request an action or a human intervention that can fix the situation .
Errors reflect anomalies, and alarms show defects. Terminology here is often used in a confusing way, in the sense that people may talk about errors but actually refer to anomalies, or use the word, “alarm” to refer to a defect.
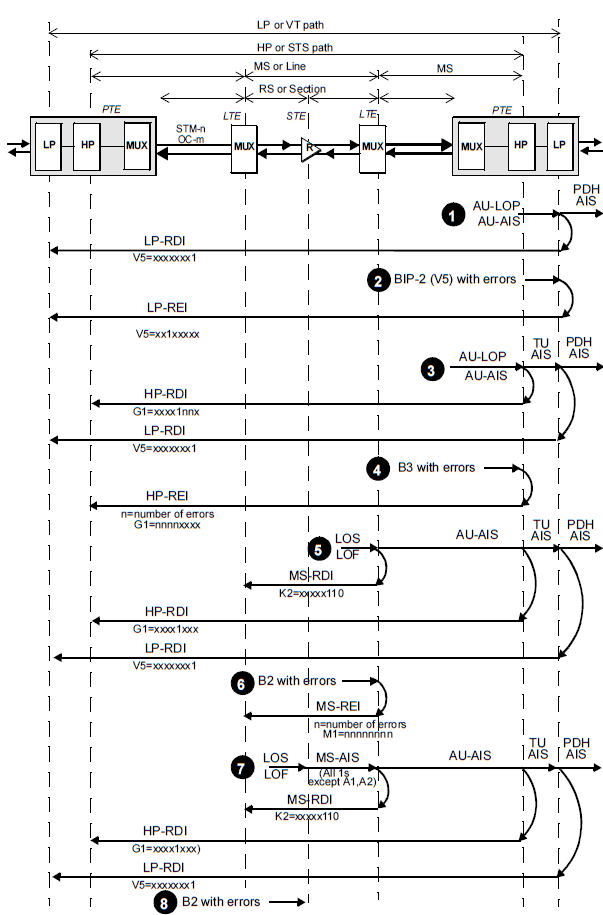
OAM management. Signals are sent downstream and upstream when events are detected at the LP edge (1, 2); HP edge (3, 4); MS edge (5, 6); and RS edge (7, 8).
In order to support a single-end operation the defect status and the number of detected bit errors are sent back to the far-end termination by means of indications such an RDI, REI, or RFI
Monitoring Events
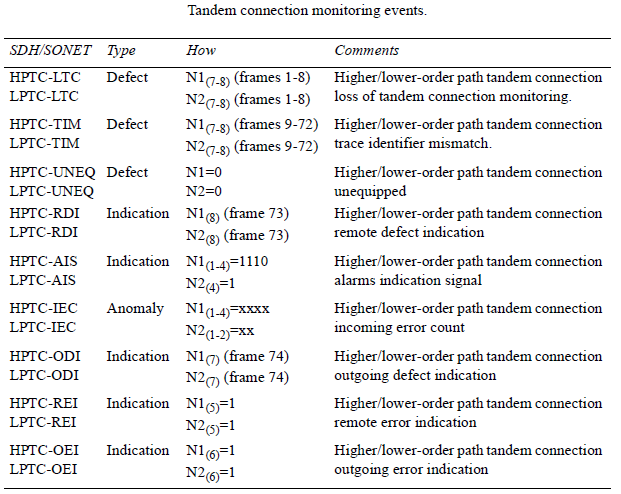
SDH frames contain a lot of overhead information to monitor and manage events When events are detected, overhead channels are used to notify peer layers to run network protection procedures or evaluate performance. Messages are also sent to higher layers to indicate the local detection of a service affecting fault to the far-end terminations.
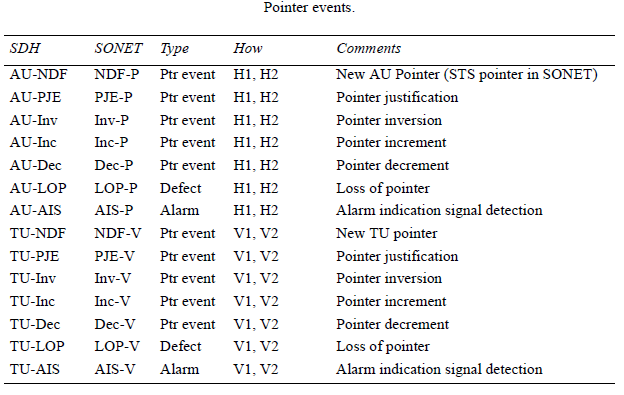
Defects trigger a sequence of upstream messages using G1 and V2 bytes. Down- stream AIS signals are sent to indicate service unavailability. When defects are detected, upstream indications are sent to register and troubleshoot causes.
Event Tables
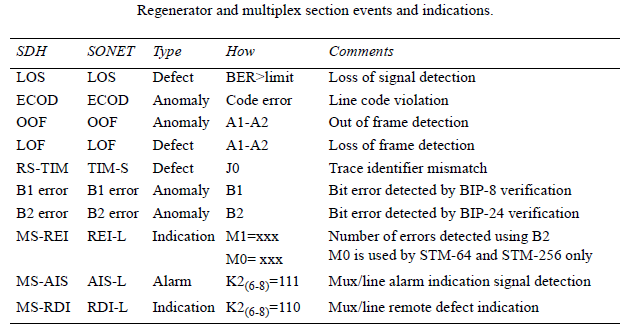
PERFORMANCE MONITORING
SDH has performance monitoring capabilities based on bit error monitoring. A bit parity is calculated for all bits of the previous frame, and the result is sent as over- head. The far-end element repeats the calculation and compares it with the received
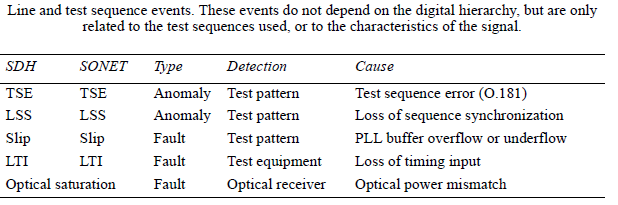
overhead. If the result is equal, there is considered to be no bit error; otherwise, a bit error indication is sent to the peer end.
Unlock Premium Content
Join over 400K+ optical network professionals worldwide. Access premium courses, advanced engineering tools, and exclusive industry insights.
Already have an account? Log in here


