
HomePosts tagged “SONET”
SONET
Showing 1 - 2 of 2 results
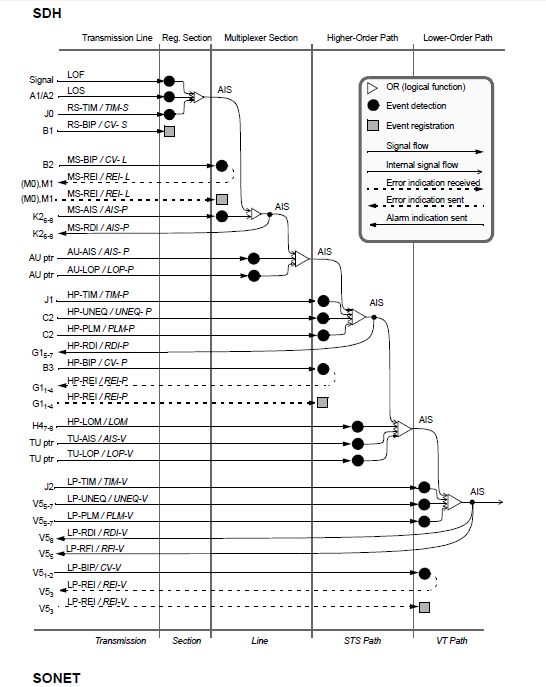
SDH/SONET:Maintenance and Performance Events We know SDH/SONET is older technology now but just have a glimpse for the revision of...
-
Free
-
March 26, 2025

Actually SPE(synchronous payload envelope) can start anywhere within the SONET payload, which necessitates the need for a pointer to point to...
-
Free
-
March 26, 2025
Explore Articles
Filter Articles
ResetExplore Courses
Tags
automation
ber
Chromatic Dispersion
coherent optical transmission
Data transmission
DWDM
edfa
EDFAs
Erbium-Doped Fiber Amplifiers
fec
Fiber optics
Fiber optic technology
Forward Error Correction
Latency
modulation
network automation
network management
Network performance
noise figure
optical
optical amplifiers
optical automation
Optical communication
Optical fiber
Optical network
optical network automation
optical networking
Optical networks
Optical performance
Optical signal-to-noise ratio
Optical transport network
OSNR
OTN
Q-factor
Raman Amplifier
SDH
Signal integrity
Signal quality
Slider
submarine
submarine cable systems
submarine communication
submarine optical networking
Telecommunications
Ticker