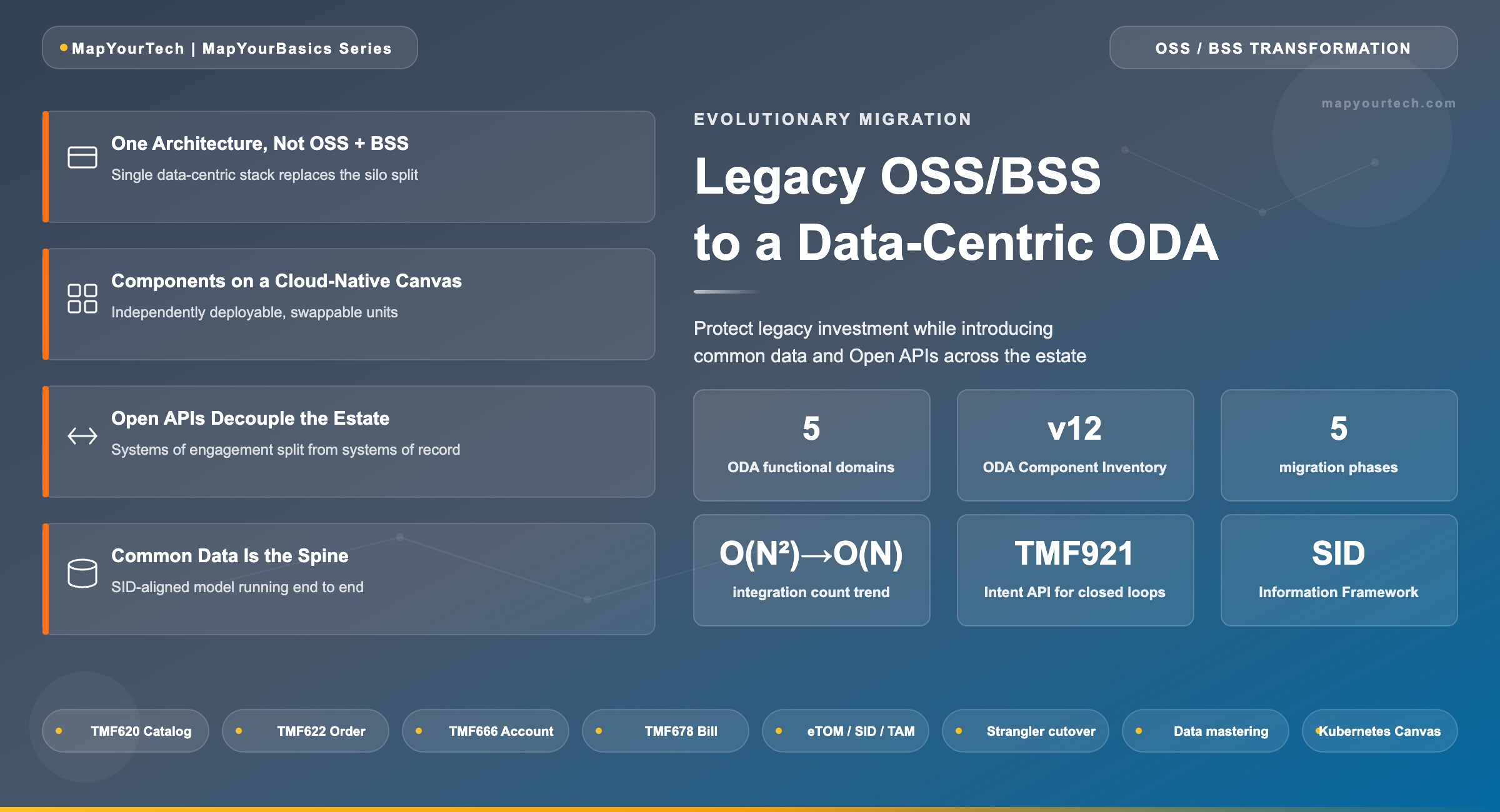
Migrating From Legacy OSS and BSS to a Data-Centric ODA
An evolutionary migration approach that protects legacy investment while introducing common data and Open APIs across the operator software estate.
1. Introduction
A large communications service provider typically runs five or more product-specific software stacks — one each for consumer wireline, consumer mobile, enterprise, IP and voice — each with its own catalog, ordering, charging and billing systems. BT described exactly this state when its chief architect found the company could bill for anything from a widget to a complex wireline service yet could not send a customer a single consolidated bill across their services. That fragmentation is the operating reality this article addresses, and the reason the term "future OSS/BSS" is a misnomer: the future is neither OSS nor BSS, because both are legacy concepts that have to be reimagined as a single architecture.
The TM Forum Open Digital Architecture (ODA) is the industry blueprint for that reimagining. ODA replaces the OSS/BSS split with one component-based, data-centric architecture in which business functions are packaged as independently deployable software components, integration is defined through standardized Open APIs, and a consistent data architecture runs end to end through the stack. The hard part is not the target picture. The hard part is reaching it without a rip-and-replace program that strands the hundreds of millions of dollars already sunk into working billing, charging and inventory systems.
This article treats migration as the central engineering problem, not ODA as an abstract reference model. It covers what specifically fails in a siloed estate, how the ODA component and canvas model is structured, why a common data architecture is the load-bearing element of the whole transition, how Open APIs let you decouple systems of engagement from systems of record in a brownfield, and the sequencing decisions — strangler patterns, data mastering, conformance gates — that determine whether the program lands. The audience is the architect or senior engineer who has to defend a migration roadmap in front of a steering committee and then make it survive contact with a live network. By the end you should be able to map your own estate against the ODA functional architecture, pick the first components to peel off, and design the data layer that makes the rest of the program possible.
Scope note: ODA spans business architecture, information systems architecture and an implementation architecture. This article concentrates on the migration mechanics — common data and Open APIs — rather than the full functional taxonomy. Where a specific Open API is named (TMF620, TMF666, TMF678, TMF921), it is the public TM Forum specification, used as the integration contract between components.
2. Why Legacy OSS/BSS Stalls a Digital Operator
Siloed stacks duplicate the same logical function across product lines, which is why a single customer can exist five times over with five different identifiers and no reconciled view. Each stack was built to bill, assure and fulfil one product family, so the customer record, the product catalog and the order model are all replicated and none of them agree. The cost surfaces the moment the business needs something cross-product: a consolidated bill, a single 360-degree customer view, or an offer that bundles mobile and broadband. None of those is a feature you can buy — each requires data that lives in one stack to be available to a component in another, which the siloed design actively prevents.
Integration burden is the second structural failure. Orange's network architecture lead put the problem plainly: operators carry enormous integration cost on the IT side and need to simplify drastically, and the only way to do that is to move to a far more plug-and-play architecture. In a siloed estate every new service triggers bespoke point-to-point integration between systems that each expose their capabilities differently. The integration count grows roughly with the square of the number of systems, so each acquisition or new product line makes the next one harder, not easier. This is the mechanism behind the 18-month concept-to-cash cycle that ODA explicitly targets reducing.
The third failure is that legacy operations cannot become autonomous. Closed-loop automation needs network and customer data captured, normalized and exposed through a consistent interface so that policy and intent can act on it. A siloed estate has no such consistent interface — the data is trapped in product-specific schemas behind product-specific integrations. Service delivery, assurance and monetization become genuinely hard when they are part of a multi-party offering, traverse multiple cloud and network domains, and must guarantee security and privacy end to end. Without a common data spine, automation stays local to each silo and never reaches the cross-domain orchestration that on-demand, programmable services require.
Takeaway: The three things that break in a siloed estate — no single customer or product view, integration cost that scales with the square of system count, and the inability to run closed-loop automation across domains — all trace back to one root cause: data trapped in product-specific schemas behind product-specific integrations. Fix the data layer and the other two become tractable.
2.1 Frameworx Is the Foundation, Not the Obstacle
TM Forum's Frameworx suite supplies the common language this migration depends on, and the migration builds on it rather than discarding it. Three Frameworx assets carry directly into ODA: the Business Process Framework (eTOM), which decomposes operator processes into fulfillment, assurance and billing alongside strategy and readiness; the Information Framework (SID), which defines a standardized information model spanning customer, product, service, resource and party domains; and the Application Framework (TAM), which maps OSS/BSS capabilities against eTOM and SID. SID matters most for migration, because a shared information language is the linchpin that makes software solutions easy to integrate — it is the model the common data architecture instantiates.
ODA reuses these directly. Its Information Systems Architecture contains the Functional Architecture, the Functional Framework and the Information Framework, and the TM Forum REST API design guidelines specify that data types in API parameters should follow the SID Information Framework reference model. The continuity is deliberate: the eTOM, SID and TAM frameworks were the functional foundation for operations at founding members like BT, and ODA was created using decades of that evolutionary best practice rather than starting from a blank sheet. For a migration team, this means the conceptual data model and process decomposition already exist and are standardized — the work is instantiating them in a common data layer and exposing them through Open APIs, not inventing them.
3. The Target: ODA Architecture and Components
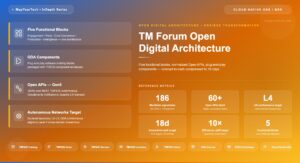
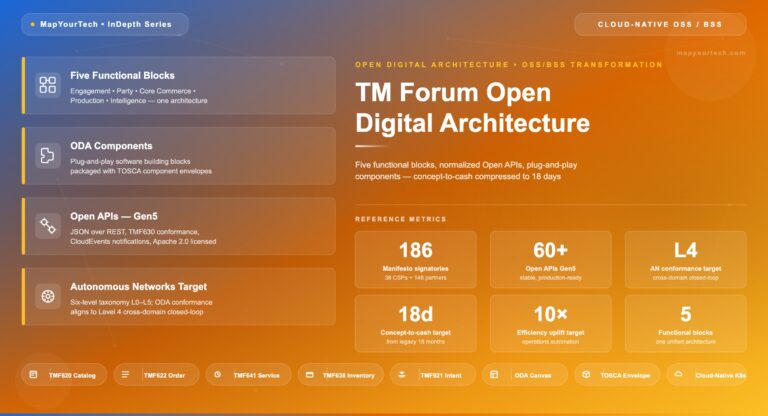
ODA is a component-based architecture in which each component exposes its business functions as a set of Open APIs, with the functionality typically implemented as services and microservices that can be independently managed on elastic, horizontally scaling infrastructure using Agile practices. That single sentence carries the entire architectural shift: function is packaged into discrete, replaceable units, and the only thing other units know about a given component is its API contract. This is what makes a component swappable without touching its neighbours, and it is the property the whole migration exploits.
The functional architecture organizes these components into a small number of top-level domains that span the enterprise rather than following the old OSS/BSS pipeline. Party management handles customers, partners and the organization itself. Core commerce management covers catalog, ordering, charging and billing. Production handles service and resource fulfilment and assurance. Intelligence management supplies analytics and closed-loop control, and engagement management owns the customer-facing experience layer. Decoupling and integration sits between every domain pair, which is the architectural statement that no domain reaches into another's internals — they interact only through defined interfaces.
3.1 Components, Canvas and the Self-Describing Envelope
An ODA component is a software component running on an open-standard cloud-native canvas, with each component carrying a self-describing envelope that holds the metadata required to fully automate its lifecycle management and operations. The envelope is the operational counterpart to the API contract: where the API says what the component does, the envelope says how to deploy, configure, scale and monitor it. This pairing is what lets a canvas treat components from different vendors as interchangeable parts rather than bespoke integrations.
The canvas itself is a software-defined blueprint for a cloud-native operating environment, and in the reference implementation it is realized on Kubernetes as a modular set of operators. As of 2026, the TM Forum ODA Canvas reference implementation defines independent operators — a Component Management operator that handles each component's lifecycle, plus operators that process the component's decomposition into ExposedAPIs, IdentityConfigs and other sub-resources. The ODA Component Directory maps commercial vendor products against the ODA Component Inventory, which reached version 12, giving operators a published catalog of conformant components to assemble. The canvas can be built on top of any cloud platform, so the choice of AWS, Azure or Google does not change the component contract.
Why this matters for migration: The component plus envelope plus canvas model means a migration does not have to be all-or-nothing. You can stand up a canvas, deploy one conformant component — say a new product catalog — and route traffic to it while the legacy catalog still runs, because the envelope automates its operations and the Open API gives every other system a stable contract. The architecture is built for incremental replacement, which is the property the evolutionary method depends on.
4. Common Data: The Spine of the Migration
Common data architecture is the foundation needed to create a single view of a customer, and it works by taking a strategic approach to unified data management that reduces the number of systems and simplifies the overall architecture. The business requirement it fulfils is precise: data generated in one part of the architecture must be available to components in any other part. That single requirement is what a siloed estate cannot satisfy, and it is why the data layer — not the component layer — is the true spine of the migration.
The reason a unified data architecture is viable now and was not a decade ago is a hardware and software story. Running one consistent, estate-wide data model end to end across every layer of the operator stack was not possible under the performance constraints of earlier database architectures. Distributed storage and processing approaches, solid-state memory and horizontally scaling data platforms removed those constraints, which is what made an end-to-end data spine technically realistic rather than aspirational. The migration team inherits that capability; the design question is how to instantiate it.
4.1 Two Routes to a Common Data Layer
The pragmatic starting point is a common data repository for each functional block of the architecture, with the recognition that other approaches exist and best practices are still being identified. This matters for sequencing. You do not need a single physical database for the whole operator on day one. You need a consistent, SID-aligned data model and a repository per functional block, so that party data, product data and service data each have one authoritative home that any component can read through an Open API. That federated-but-consistent model is achievable incrementally; a single monolithic data store is not, and attempting it stalls the program.
The second, harder route is adaptive data mastering across systems of record. In a brownfield, the authoritative copy of customer, product or asset data may live in several legacy systems at once during the transition. The migration has to master key data — product, customer, assets — across the various systems of record throughout the implementation journey, deciding for each data domain which system holds the golden copy at each phase. Oracle's brownfield approach using TM Forum Open APIs exposed the capabilities of the systems of record — catalog, sales, commerce, care, billing, order management — and adaptively mastered key data across them, which is what enabled genuine decoupling of systems of engagement from systems of record. Data mastering is the part of the migration that is invisible on an architecture diagram and yet determines whether the cutover of any given component is safe.
Takeaway: Do not start by building one giant database. Start with a SID-aligned data model and a repository per functional block, then run adaptive data mastering to decide, domain by domain and phase by phase, which system of record holds the golden copy. The mastering plan, not the database design, is what makes each component cutover safe.
4.2 SID as the Shared Schema
SID gives the common data layer a ready-made, standardized vocabulary so that the team does not design the customer, product, service and resource models from scratch. SID organizes information into domains — market and sales, product, customer, service, resource, supplier and partner, plus enterprise and common business entities such as party and location — as an information model rather than a physical schema. That distinction is the useful one for migration: SID tells you what a Product Offering, a Customer Order or a Service Specification means and how the concepts relate, and you map your physical repositories onto that model rather than negotiating semantics between every pair of legacy systems.
The payoff appears at the API boundary. Because the TM Forum REST API design guidelines specify that API data types should follow the SID reference model, a component that masters its data against SID and exposes it through a SID-aligned Open API is immediately consumable by any other conformant component. The common information language is the linchpin in creating easy-to-integrate software solutions — it converts the integration problem from N-squared bespoke mappings into N components each speaking one shared model. For deeper background on how the underlying information and process frameworks fit together, the broader optical and telecom operations standards landscape shows the same pattern of shared models reducing integration cost.
5. Open APIs as the Decoupling Contract
Open APIs provide a standard way to functionally integrate applications, but they do not by themselves solve deploying, configuring and operating a complex application landscape — that is the canvas and component-envelope job. The division of labour is worth stating precisely because teams conflate the two and then expect APIs to deliver operational automation they were never meant to provide. Open APIs define the contract between components; the canvas operates the components. Both are required, and the migration uses them for different purposes.
The decoupling pattern is the heart of the brownfield method: separate the systems of engagement from the systems of record. Engagement systems — the storefront, the care application, the self-service portal — should not know or care which legacy billing or CRM system actually holds the data. An API gateway and an orchestration layer route each request to the appropriate underlying system of record, which may sit on-premises or in any of several clouds. Once that indirection exists, you can replace a system of record behind the API without the engagement layer noticing, because the contract it depends on is the Open API, not the legacy system's native interface.
5.1 The Core Commerce Open APIs
A handful of named Open APIs carry most of the integration load in the core commerce domain, and knowing which is which lets you reason about a cutover concretely.
| Open API | Function | Decoupling role in migration |
|---|---|---|
| TMF620 Product Catalog | Exposes product offerings and specifications | Lets a new catalog component publish offers that legacy ordering and billing consume unchanged |
| TMF622 Product Ordering | Captures and tracks customer orders | Decouples order capture from the fulfilment systems that execute the order |
| TMF666 Billing Account | Manages billing account structures | Gives care and engagement a stable account contract independent of the billing engine behind it |
| TMF678 Customer Bill | Exposes customer billing information | Allows a SaaS care application to query bills from a canvas-hosted billing component directly |
| TMF921 Intent | Carries declarative intent to a domain | Feeds AI-driven intent into the architecture for closed-loop control at autonomous-network reference points |
The Business Operating System catalysts made this concrete. In one integration pattern, a SaaS care application queried a canvas-hosted billing component for customer billing information using TMF666 and TMF678 through an API gateway, with no intermediary proxy needed. In a more complex pattern, an ODA SaaS proxy represented an external SaaS product catalog's offer launch to a canvas-hosted billing component over TMF620. The two patterns map to the two situations every migration faces: sometimes the legacy or SaaS system can speak the Open API directly through a gateway, and sometimes it needs a proxy component to present an ODA-conformant face. Choosing between them per integration is a core migration decision.
5.2 Synchronous and Event-Driven Contracts
ODA uses Open APIs as the synchronous contract between components and promotes an asynchronous event-driven pattern for high-volume telco workflows. The reason is throughput: a billing run or a network assurance stream generates event volumes that a request-response model handles poorly, so the architecture pairs synchronous APIs for queries and commands with asynchronous messaging for notifications and bulk events. A migration that wires everything synchronously will hit a scaling wall when it reaches assurance or rating workloads; the event-driven path has to be designed in from the start for those domains, not retrofitted after the synchronous integration is already load-bearing.
Takeaway: Open APIs decouple systems of engagement from systems of record so you can replace what is behind the API without disturbing what is in front of it. Use a direct gateway integration where the underlying system can speak the Open API, and an ODA proxy component where it cannot. Design the event-driven path in from the start for billing, rating and assurance, because those volumes break a purely synchronous design.
6. The Evolutionary Migration Method
The Open Digital Framework exists precisely to provide a migration path from legacy IT systems and processes to modular, cloud-native software orchestrated using AI, and it does so as machine-readable assets — tools, code, knowledge and standards — not just documents. The framework wraps ODA with three migration-specific asset classes: transformation tools that guide the move from legacy architecture to ODA, including tools that work backwards from the target architecture; maturity models and readiness checks that baseline current digital capability; and benchmarking data. The method below is the engineering shape of using those assets.
The defining choice is evolutionary, not revolutionary. Operators want to apply ODA principles without having to rebuild everything, and the framework is designed around that reality. The migration reuses existing application investments by bringing them into a broader ODA ecosystem in which external and SaaS application components participate as first-class ODA citizens. This is the opposite of rip-and-replace: the legacy billing system is not deleted on day one, it is wrapped, decoupled behind an Open API, and replaced only when a conformant component is ready and its data has been mastered across.
6.1 Five Phases of the Transition
The phases below sequence the work so that each step delivers a working, decoupled increment rather than a big-bang cutover.
Phase 1 — Baseline and target mapping
Map the current estate against the ODA functional architecture and run a maturity readiness check to baseline digital capability. The transformation tools let the team work backwards from the target architecture, identifying which legacy systems map to which ODA components and where the duplication and integration cost concentrate. The output is a component map of the estate and a ranked list of the highest-cost silos — usually the duplicated catalog and customer records — which become the first migration candidates.
Phase 2 — Stand up the canvas and the data spine
Deploy an ODA canvas on the chosen cloud platform and establish the common data layer as a SID-aligned repository per functional block. Nothing customer-facing changes yet. This phase builds the foundation the rest of the program lands on: a runtime that can operate conformant components and a data architecture that lets data from one block reach any other. Skipping or shortcutting the data spine here is the single most common cause of a stalled program, because every later phase assumes it exists.
Phase 3 — Decouple engagement from record
Insert the API gateway and orchestration layer between the engagement systems and the legacy systems of record, exposing the legacy capabilities through Open APIs. At the end of this phase the storefront and care applications talk to TMF620, TMF666 and TMF678 contracts rather than to legacy native interfaces, even though legacy systems still execute behind those contracts. The estate now has the indirection that makes later replacement invisible to the front end.
Phase 4 — Replace components, master data across
Replace one system of record at a time with a conformant ODA component, mastering its data domain across the old and new systems before cutover. A new product catalog component goes live behind TMF620; once its data is mastered and traffic is validated, the legacy catalog is retired. Repeat per component. This is where the bulk of the program's elapsed time goes, and where the data-mastering plan from Phase 2 earns its keep.
Phase 5 — Add intelligence and closed loops
With a common data spine populated and components exposing consistent APIs, connect intelligence management and closed-loop control. Intent flows in through TMF921, network and customer data flows out through the data architecture, and policy-driven automation acts across domains rather than within a single silo. This phase is only reachable because the earlier ones built the consistent data and interfaces that closed-loop control requires.
Sequencing discipline: Phases 2 and 3 produce no visible business feature, which creates pressure to skip them and jump straight to replacing a billing system. That pressure is the program's main risk. Without the data spine and the decoupling layer, a component replacement is a like-for-like swap of one silo for another, and the migration delivers a new system rather than a new architecture.
7. Sequencing, Strangler Patterns and Data Mastering
The strangler pattern is the mechanism that turns the five phases into safe, reversible steps. You place the new ODA component alongside the legacy system, route a slice of traffic to it behind the Open API, and grow that slice as confidence builds — the new component gradually strangles the old one rather than replacing it in a single cutover. The Open API is what makes this possible: because the engagement layer depends only on the contract, you can shift the proportion of traffic served by the new component without any front-end change, and roll back instantly by shifting it back.
7.1 Choosing the Cutover Order
Order the components so that each cutover reduces integration cost and the data dependencies run in the right direction. Catalog and party data are usually first, because almost every other component reads them — a single SID-aligned product catalog and a single party record remove the most duplication and unblock the most downstream work. Billing tends to come later, because it depends on catalog, party and rating data being consistent first, and because billing cutovers carry the highest revenue risk. The dependency direction is the constraint: never cut over a component whose golden-copy data is still mastered in a system you have not yet decoupled.
7.2 Brownfield Reality: SaaS and Multi-Cloud Components
Real estates include components that will never run on the canvas — SaaS billing, a cloud CRM, applications under different commercial models. The ecosystem extension handles this by letting those external components participate as first-class ODA citizens, bridged into the canvas environment through one of two integration scenarios. Where the interaction is simple, the external SaaS application calls a canvas-hosted component directly through the API gateway. Where it is more complex, an ODA SaaS proxy component represents the external application to the canvas, presenting an ODA-conformant face over the proprietary SaaS interface. This is what makes the method usable in practice: you do not have to repatriate every SaaS application to the canvas to get the architectural benefits.
8. Canvas, Conformance and Procurement
Conformance testing against the ODA reference implementation changes how operators buy software, which is one of the larger second-order effects of the migration. Vodafone's architecture lead described the intent directly: future requests for proposal could require an interoperability test against the ODA reference implementation before the operator would consider a vendor solution, the same way network software is interoperability-tested before purchase. The aim is to make integration work disappear at procurement time — if a component passed conformance, it plugs into the architecture without a custom integration project.
The component marketplace is the mechanism that operationalizes this. The vision is to make the RFP procurement process largely redundant by letting operators assemble conformant components from a directory rather than running a bespoke selection-and-integration project for each one, with a stated target of a 10x improvement in operational efficiency through automated operations, standardization through machine-readable component envelopes, and faster time to market. As of 2026 the ODA Component Directory publishes commercial vendor products mapped against the ODA Component Inventory, so the marketplace is a working artifact rather than a future promise — though the operational-efficiency figures remain TM Forum's stated targets for the initiative, not independently measured outcomes.
Governance implication: Build the conformance gate into the migration governance from Phase 1. Every new component, whether built or bought, should be required to pass ODA conformance and run on the canvas before it enters the estate. This is the control that prevents the migration from accumulating a fresh generation of non-conformant silos while it retires the old ones.
9. Measuring Migration Progress
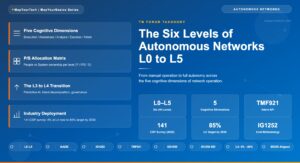
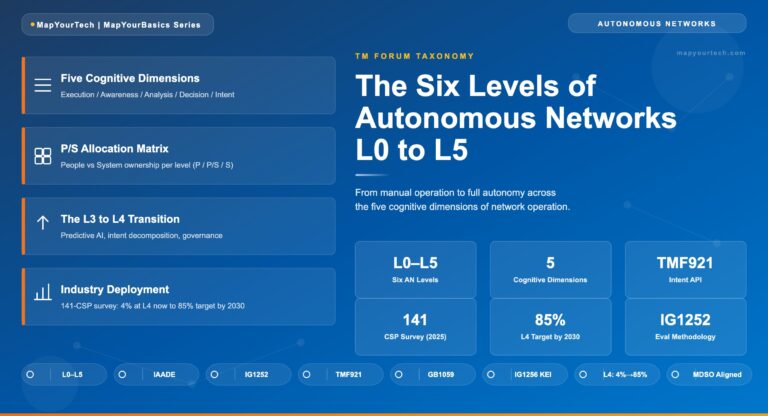
The headline business metric the Open Digital Framework targets is concept-to-cash time, with the stated goal of compressing it from 18 months to 18 days. That two-orders-of-magnitude target is the framework's own ambition rather than a measured industry average, so it functions as a direction of travel and a way to frame the business case, not as a benchmark every operator will hit. The useful engineering metrics sit underneath it and track whether the architecture is actually changing.
The diagnostic metric for the architecture itself is integration count. A siloed estate's integration count grows with the square of system count; a successful migration bends that curve downward as bespoke point-to-point links are replaced by components speaking shared Open APIs. Tracking the number of bespoke integrations retired per quarter, against the number of conformant components deployed, shows whether the program is delivering a new architecture or just new systems. The chart below contrasts the two trajectories.
Two further metrics matter for steering. Component conformance rate — the share of the estate running as conformant components on the canvas — tracks how far the structural transition has progressed. Data-mastering coverage — the share of key data domains with a single defined golden copy — tracks the health of the spine that everything else depends on. A program with rising component count but flat data-mastering coverage is replacing systems without consolidating data, which is the failure mode dressed up as progress.
Takeaway: Treat the 18-months-to-18-days figure as the business framing, not a benchmark. Steer on integration count retired per quarter, component conformance rate, and data-mastering coverage. If component count rises while data-mastering coverage stays flat, the program is swapping silos rather than building the common data spine.
10. Failure Modes and How They Break
Each failure mode below names the specific point where the migration unlocks, in the sense that a downstream step can no longer proceed safely.
Skipping the data spine
Building components before the common data layer produces conformant components that still read duplicated, non-reconciled records, so the single-customer-view benefit never materializes. The break point is Phase 4: the first component cutover that needs data from a domain with no defined golden copy cannot be validated, because there is no authoritative source to validate against. The program either stalls or proceeds on unmastered data and ships a reconciliation defect into production.
Cutting over against undecoupled data
Retiring a system of record whose golden-copy data is still mastered in an upstream system that has not been decoupled corrupts the data domain at the moment of cutover. The break point is the cutover itself: traffic shifts to the new component, but the authoritative data is still being written in the old upstream path, so the two diverge with no reconciliation. This is why cutover order must follow data-dependency direction, never convenience.
Synchronous-only integration
Wiring billing, rating and assurance through synchronous request-response APIs hits a throughput wall at production event volumes. The break point is the first high-volume run — a full billing cycle or an assurance event storm — where the synchronous path saturates and latency climbs past timeout thresholds. Retrofitting the event-driven path after the synchronous integration is load-bearing means rebuilding integrations that are already in production.
Accumulating new non-conformant silos
Deploying new components without a conformance gate lets the migration build a fresh generation of bespoke-integrated systems while retiring the old one. The break point is diffuse: there is no single failure, just a steadily rising integration count that the migration was supposed to reduce, discovered only when the program reports component progress but no integration-cost reduction. The conformance gate in governance is the control that prevents it.
11. Migration Strategies Compared
Three broad strategies appear in practice. The comparison below sets them against the criteria that decide a real program.
| Criterion | Rip-and-replace | Evolutionary (ODA) | Wrap-and-leave |
|---|---|---|---|
| Legacy investment | Written off | Protected, retired on readiness | Fully retained |
| Risk profile | High — big-bang cutover | Low — reversible per component | Low, but defers the problem |
| Time to first benefit | Long — nothing ships until done | Incremental — per-component | Immediate but shallow |
| Common data view | Achievable but late | Built progressively into the spine | Not achieved — silos persist |
| Integration cost trend | Falls only at the end | Falls progressively | Unchanged or rising |
| Closed-loop automation | Possible after completion | Reachable once spine is populated | Blocked — no common data |
The evolutionary approach is the one ODA is built for, and the table shows why: it is the only column that protects legacy investment, holds risk low, and still reaches the common data view and closed-loop automation that are the point of the exercise. Wrap-and-leave buys time but never delivers the data consolidation, so the strategic benefits stay out of reach. Rip-and-replace can reach the same end state but concentrates all the risk into a single cutover and ships no benefit until the program completes, which is why most large operators reject it. The selection guideline is straightforward: choose evolutionary unless the legacy estate is small enough and low-risk enough that a single cutover is genuinely safe.
12. Where the Architecture Is Heading
The canvas is converging on a fully operator-driven Kubernetes runtime, which narrows the gap between the architectural model and the deployment reality. As of 2026 the reference implementation defines the canvas as a modular set of operators — component management plus operators that handle the decomposition into ExposedAPIs and IdentityConfigs — with versioned component definitions and support for current and prior versions. The direction is toward a canvas where conformant components from any vendor deploy and operate through standard operators rather than bespoke runbooks, which is the operational half of the plug-and-play promise that the Open API contract addresses on the integration half.
Intent-driven and AI-augmented operation is the second trajectory. TMF921 carries declarative intent into the architecture, and at the autonomous-network reference points it lets AI-driven intent feed the closed-loop control model rather than operators issuing imperative commands. TM Forum is now extending this into AI-augmented software engineering aligned to ODA, which points at components whose lifecycle and even construction are increasingly automated. For migration teams the implication is concrete: the common data spine built in Phase 2 is not only the foundation for today's single-customer view, it is the substrate that intent-driven and AI-driven operation will act on, which raises the return on getting the data layer right rather than treating it as plumbing.
The skills the transition rewards are data modelling against SID, API contract design against the TM Forum Open API portfolio, and Kubernetes-native operations for the canvas. An architect who can map a legacy estate to ODA components, design the data-mastering plan that sequences the cutovers, and reason about synchronous-versus-event-driven integration is the one who can carry a migration from baseline to closed-loop operation. For adjacent grounding in how shared models and open interfaces reduce integration cost across telecom domains, the wider body of network operations and standards material reinforces the same architectural lesson that sits at the centre of this migration.
12.1 Quick Reference
| Element | Role in migration | Key standard / asset |
|---|---|---|
| Common data architecture | End-to-end spine; single view of customer | SID Information Framework |
| ODA component | Independently deployable, swappable unit | ODA Component Inventory v12 |
| ODA canvas | Cloud-native execution environment | Reference implementation on Kubernetes |
| Open APIs | Decoupling contract between components | TMF620, TMF622, TMF666, TMF678 |
| Intent interface | Declarative input to closed loops | TMF921 |
| Conformance gate | Procurement and governance control | ODA reference implementation test |
13. Glossary
- Canvas
- The cloud-native execution environment that operates ODA components, realized in the reference implementation as a modular set of Kubernetes operators.
- Common data architecture
- A consistent, unified data model running end to end through the stack so that data created in one functional block is available to components in any other.
- Component envelope
- The self-describing metadata accompanying an ODA component that lets the canvas automate its lifecycle, configuration, scaling and monitoring.
- Data mastering
- Deciding, per data domain and per migration phase, which system holds the authoritative golden copy of key data such as customer, product and asset records.
- eTOM (Business Process Framework)
- The Frameworx process decomposition covering fulfilment, assurance, billing, strategy and readiness.
- ODA component
- An independently deployable software unit, built from one or more microservices, exposing its functions through Open APIs.
- SID (Information Framework)
- The standardized information model spanning customer, product, service, resource and party domains that the common data layer instantiates.
- Strangler pattern
- A migration technique in which a new component runs alongside a legacy system and gradually takes over its traffic behind a stable API, allowing safe, reversible cutover.
- System of engagement / system of record
- The customer-facing experience layer versus the authoritative data-holding back end; ODA decouples the two through Open APIs.
14. References
- TM Forum, "Open Digital Architecture concepts and principles," TM Forum Open Digital Framework.
- TM Forum, "Open Digital Architecture — Components, Canvas and the ODA Technical Architecture," TM Forum.
- TM Forum, "ODA Component Directory and ODA Component Inventory," TM Forum Open Digital Architecture.
- TM Forum, "REST API Design Guidelines," TM Forum Open API Program.
- TM Forum, "Business Process Framework (eTOM), Information Framework (SID) and Application Framework (TAM)," Frameworx.
- TM Forum, "Autonomous Networks — Intent management and the TMF921 Intent API," TM Forum Autonomous Networks project.
- Sanjay Yadav, "Optical Network Communications: An Engineer's Perspective" — Bridge the Gap Between Theory and Practice in Optical Networking.

Optical Communications & Network Automation Expert | Author of 3 Books for Optical Engineers | Founder, MapYourTech
Optical networking engineer with nearly two decades of experience across DWDM, OTN, coherent optics, submarine systems, and cloud infrastructure. Founder of MapYourTech. Read full bio →
Follow on LinkedIn