It is important to understand the rules for creating Unix files:
Unix is case sensitive! For example, “fileName” is different from “filename”.
It is recommended that you limit names to the alphabetic characters, numbers, underscore (_), and dot (.). Dots (.) used in Unix filenames are simply characters and not delimiters between filename components; you may include more than one dot in a filename. Including a dot as the first character of a filename makes the file invisible (hidden) to the normal ls command; use the -a flag of the ls command to display hidden files.
Although many systems will allow more, a safe length is 14 characters per file name.
Unix shells typically include several important wildcard characters. The asterisk (*) is used to match 0 or more character (e.g., abc* will match any file beginning with the letters abc), the question mark (?) is used to match any single character, and the left ([) and right (]) square brackets are used to enclose a string of characters, any one of which is to match. Execute the following commands and observe the results:
ls m*
ls *.f
ls *.?
ls [a-d]*
Notes for PC users: Unix uses forward slashes ( / ) instead of backslashes ( \ ) for directories
Looking at the Contents of Files
You can examine the contents of files using a variety of commands. cat, more, pg, head, and tail are described here. Of course, you can always use an editor; to use vi in “read-only” mode to examine the contents of the file “argtest”, enter:
vi -R argtest
You can now use the standard vi commands to move through the file; however, you will not be able to make any changes to the contents of the file. This option is useful when you simply want to look at a file and want to guarantee that you make no changes while doing so.
Use the vi “”” command to exit from the file.
cat Command
cat is a utility used to conCATenate files. Thus it can be used to join files together, but it is perhaps more commonly used to display the contents of a file on the screen.
Observe the output produced by each of the following commands:
cd; cd xmp
cat cars
cat -vet cars
cat -n cars
The semicolon (;) in the first line of this example is a command separator which enables entry of more than one command on a line. When the <Return> key is pressed following this line, the command cd is issued which changes to your home directory. Then the command “cd xmp” is issued to change into the subdirectory “xmp.” Entering this line is equivalent to having entered these commands sequentially on separate lines. These two commands are included in the example to guarantee that you are in the subdirectory containing “cars” and the other example files. You need not enter these commands if you are already in the “xmp” directory created when you copied the example files (see Sample Files if you have not already copied these files).
The “-vet” options enable display of tab, end-of-line, and other non-printable characters within a file; the “-n” option numbers each line as it is displayed.
You can also use the cat command to join files together:
Note: If the file “document” had previously existed, it will be replaced by the contents of files “page1” and “page2”.
Cautions in using the cat command
The cat command should only be used with “text” files; it should not be used to display the contents of binary (e.g., compiled C or FORTRAN programs). Unpredictable results may occur, including the termination of your logon session, when the cat command is used on binary files. Use the command “file *” to display the characteristics of files within a directory prior to using the cat command with any unknown file. You can use the od (enter “man od” for details on use of Octal Dump) command to display the contents of non-text files. For example, to display the contents of “a.out” in both hexadecimal and character representation, enter:
od -xc a.out
Warning! cat (and other Unix commands) can destroy files if not used correctly. For example, as illustrated in the Sobell book, the cat (also cp and mv) command can overwrite and thus destroy files. Observe the results of the following command:
cat letter page1 > letter
Typically Unix does not return a message when a command executes successfully. Here the Unix operating system will attempt to complete the requested command by first initializing the file “letter” and then writing the current contents of “letter” (now nothing) and “page1” into this file. Since “letter” has been reinitialized and is also named as a source file, an error diagnostic is generated. Part of the Unix philosophy is “No news is good news”. Thus the appearance of a message is a warning that the command was not completed successfully.
Now use the “cat” command to individually examine the contents of the files “letter” and “page1”. Observe that the file “letter” does not contain the original contents of the files “letter” and “page1” as was intended.
Use the following command to restore the original file “letter”:
cp ~aixstu00/xmp/letter .
more Command
You may type or browse files using the more command. The “more” command is useful when examining a large file as it displays the file contents one page at a time, allowing each page to be examined at will. As with the man command, you must press the space bar to proceed to the next screen of the file. On many systems, pressing the <b> key will enable you to page backwards in the file. To terminate more at any time, press <q>.
To examine a file with the more command, simply enter:
more file_name
See the online manual pages for additional information.
The man command uses the more command to display the manual pages; thus the commands you are familiar with in using man will also work with more.
Not all Unix systems include the more command; some implement the pg command instead. VTAIX includes both the more and pg commands. When using the pgcommand, press <Return> to page down through a file instead of using the space bar.
Observe the results of entering the following commands:
more argtest
pg argtest
head Command
The head command is used to display the first few lines of a file. This command can be useful when you wish to look for specific information which would be found at the beginning of a file. For example, enter:
head argtest
tail Command
The tail command is used to display the last lines of a file. This command can be useful to monitor the status of a program which appends output to the end of a file. For example, enter:
tail argtest
Copying, Erasing, Renaming
Warning! The typical Unix operating system provides no ‘unerase’ or ‘undelete’ command. If you mistakenly delete a file you are dependent upon the backups you or the system administrator has maintained in order to recover the file. You need to be careful when using commands like copy and move which may result in overwriting existing files. If you are using the C or Korn Shell, you can create a command alias which will prompt you for verification before overwriting files with these commands.
Copying Files
The cp command is used to copy a file or group of files. You have already seen an example application of the cp command when you copied the sample files to your userid (see Sample Files). Now let’s make a copy of one of these files. Recall that you can obtain a listing of the files in the current directory using the lscommand. Observe the results of the following commands:
ls l*
cp letter letter.2
ls l*
Note: Unlike many other operating systems, such as PC/DOS, you must specify the target with the copy command; it does not assume the current directory if no “copy-to” target is specified.
Erasing Files
Unix uses the command rm (ReMove) to delete unwanted files. To remove the file “letter.2” which we have just created, enter:
rm letter.2
Enter the command “ls l*” to display a list of all files beginning with the letter “l”. Note that letter.2 is no longer present in the current directory.
The remove command can be used with wildcards in filenames; however, this can be dangerous as you might end up erasing files you had wanted to keep. It is recommended that you use the “-i” (interactive) option of rm for wildcard deletes — you will then be prompted to respond with a “y” or “Y” for each file you wish to delete.
Renaming a File
The typical Unix operating system utilities do not include a rename command; however, we can use the mv (MoVe) command (see for additional uses of this command) to “move” Working with Directories) a file from one name to another. Observe the results of the following commands:
ls [d,l]*
mv letter document
ls [d,l]*
mv document letter
ls [d,l]*
Note: The first mv command overwrites the file “document” which you had created in an earlier exercise by concatenating “page1” and “page2”. No warning is issued when the mv command is used to move a file into the name of an existing file. If you would like to be prompted for confirmation if the mv command were to overwrite an existing file, use the “-i” (interactive) option of the mv command, e.g.:
mv -i page1 letter
You will now be told that the file “letter” already exists and you will be asked if you wish to proceed with the mv command. Answer anything but “y” or “Y” and the file “letter” will not be overwritten. See Command Alias Applications for information on creating an alias for mv which incorporates the “-i” option to prevent accidental overwrites when renaming files.
Using the Command Line
The command interpreter (shell) provides the mechanism by which input commands are interpreted and passed to the Unix kernel or other programs for processing. Observe the results of entering the following “commands”:
./filesize
./hobbit
./add2
ls -F
Observe that “filesize” is an executable shell script which displays the size of files. Also note that “./hobbit” and “./add2” generate error diagnostics as there is no command or file with the name “hobbit” and the file “add2” lacks execute permission.
Standard Input and Standard Output
As you have seen previously, Unix expects standard input to come from the keyboard, e.g., enter:
cat
my_text
<Ctrl-D>
Standard output is typically displayed on the terminal screen, e.g., enter:
cat cars
Standard error (a listing of program execution error diagnostics) is typically displayed on the terminal screen, e.g., enter:
ls xyzpqrz
Redirection
As illustrated above, many Unix commands read from standard input (typically the keyboard) and write to standard output (typically the terminal screen). The redirection operators enable you to read input from a file (<) or write program output to a file (>). When output is redirected to a file, the program output replaces the original contents of the file if it had previously existed; to add program output to the end of an existing file, use the append redirection operator (>>).
Observe the results of the following command:
./a.out
You will be prompted to enter a Fahrenheit temperature. After entering a numeric value, a message will be displayed on the screen informing you of the equivalent Centigrade temperature. In this example, you entered a numeric value as standard input via the keyboard and the output of the program was displayed on the terminal screen.
In the next example, you will read data from a file and have the result displayed on the screen (standard output):
cat data.in
./a.out < data.in
Now you will read from standard input (keyboard) and write to a file:
./a.out > data.two
35
cat data.two
Now read from standard input and append the result to the existing file:
./a.out < data.in >> data.two
As another example of redirection, observe the result of the following two commands:
ls -la /etc > temp
more temp
Here we have redirected the output of the ls command to the file “temp” and then used the more command to display the contents of this file a page at a time. In the next section, we will see how the use of pipes could simply this operation.
A filter is a Unix program which accepts input from standard input and places its output in standard output. Filters add power to the Unix system as programs can be written to use the output of another program as input and create output which can be used by yet another program. A pipe (indicated by the symbol “|” — vertical bar) is used between Unix commands to indicate that the output from the first is to be used as input by the second. Compare the output from the following two commands:
ls -la /etc
ls -la /etc | more
The first command above results in a display of all the files in the in the “/etc” directory in long format. It is difficult to make use of this information since it scrolls rapidly across the screen. In the second line, the result of the ls command are piped into the more command. We can now examine this information one screen at a time and can even back up to a prior screen of information if we wished to do so. As you became more familiar with Unix, you will find that piping output to themore command will be very useful in a variety of applications.
The sort command can be used to sort the lines in a file in a desired order. Now enter the following commands and observe the results:
who
sort cars
who | sort
The who command displays a listing of logged on users and the sort command enables us to sort information. The second command sorts the lines in the file cars alphabetically by first field and displays the result in standard output. The third command illustrates how the result of the who command can be passed to the sort command prior to being displayed. The result is a listing of logged on users in alphabetical order.
The following example uses the “awk” and “sort” commands to select and reorganize the output generated by the “ls” command:
ls -l | awk '/:/ {print $5,$9}' | sort -nr
Note: Curly braces do not necessarily display correctly on all output devices. In the above example, there should be a left curly brace in front of the word print and a right curly brace following the number 9.
Observe that the output displays the filesize and filename in decreasing order of size. Here the ls command first generates a “long” listing of the files in the current directory which is piped to the “awk” utility, whose output is in turn piped to the “sort” command.
“awk” is a powerful utility which processes one or more program lines to find patterns within a file and perform selective actions based on what is found. Slash (/) characters are used as delimiters around the pattern which is to be matched and the action to be taken is enclosed in curly braces. If no pattern is specified, all lines in the file are processed and if no action is specified, all lines matching the specified pattern are output. Since a colon (:) is used here, all lines containing file information (the time column corresponding to each file contains a colon) are selected and the information contained in the 5th and 9th columns are output to the sort command.
Note: If the ls command on your system does not include a column listing group membership, use {print $4,$8} instead of the “print” command option of awk listed above.
Here the “sort” command options “-nr” specify that the output from “awk” is to be sorted in reverse numeric order, i.e., from largest to smallest.
For additional information on the “awk” and “sort” commands, see the online man pages or the References included as part of this documentation; the appendix of the Sobell book includes an overview of the “awk” command and several pages of examples illustrating its use.
The preceding command is somewhat complex and it is easy to make a mistake in entering it. If this were a command we would like to use frequently, we could include it in a shell scripts as has been in sample file “filesize”. To use this shell script, simply enter the command:
./filesize
or
sh filesize
If you examine the contents of this file with the cat or vi commands, you will see that it contains nothing more the piping of the ls command to awk and then piping the output to sort.
The tee utility is used to send output to a file at the same time it is displayed on the screen:
who | tee who.out | sort
cat who.out
Here you should have observed that a list of logged on users was displayed on the screen in alphabetical order and that the file “who.out” contained an unsorted listing of the same userids.
Some Additional File Handling Commands
Word Count
The command wc displays the number of lines, words, and characters in a file.
To display the number of lines, words, and characters in the file file_name, enter: wc file_name
Comparing the Contents of Two Files: the cmp and diff Commands
The cmp and diff commands are used to compare files; the “comp” command is not used to compare files, but to “compose a message”.
The cmp command can be used for both binary and text files. It indicates the location (byte and line) where the first difference between the two files appears.
The diff command can be used to compare text files and its output shows the lines which are different in the two files: a less than sign (“<“) appears in front of lines from the first file which differ from those in the second file, a greater than symbol (“>”) precedes lines from the second file. Matching lines are not displayed.
Observe the results of the following commands:
cmp page1 page2
diff page1 page2
Lines 1 and 2 of these two files are identical, lines 3 differ by one character, and page one contains a blank line following line three, while page2 does not.
Actually its no. of pairs and no. of Twist terminology…..eg.RJ-45 has 4 pairs of wire and 5 twist are there 4pair twist + 1 combine twist of all. RJ-11,one pair one twist!!! RJ is registered Jacks
Learn the advanced features of SONET and SDH; specifically, the different ways of concatenating SONET and SDH signals, different techniques for mapping packet data onto SONET and SDH connections, transparency services for carrier’s carrier applications, and fault management and performance monitoring capabilities.
3.2.1 Standard Contiguous Concatenation in SONET and SDH
3.2.2 Arbitrary Concatenation
3.2.3 Virtual Concatenation
3.2.3.1 Higher-Order Virtual Concatenation (HOVC)
3.2.3.2 Lower-Order Virtual Concatenation (LOVC)
3.3 LINK CAPACITY ADJUSTMENT SCHEME
3.4 PAYLOAD MAPPINGS
3.4.1 IP over ATM over SONET
3.4.2 Packet over SONET/SDH
3.4.3 Generic Framing Procedure (GFP)
3.4.3.1 GFPFrame Structure
3.4.3.2 GFPFunctions
3.4.4 Ethernet over SONET/SDH
3.5 SONET/SDH TRANSPARENCY SERVICES
3.5.1 Methods for Overhead Transparency
3.5.2 Transparency Service Packages
3.6 WHEN THINGS GO WRONG
3.6.1 Transport Problems and Their Detection
3.6.1.1 Continuity Supervision
3.6.1.2 Connectivity Supervision
3.6.1.3 Signal Quality Supervision
3.6.1.4 Alignment Monitoring
3.6.2 Problem Localization and Signal Maintenance
3.6.2.1 Alarm Indication Signals
3.6.2.2 Remote Defect Indication
3.6.3 Quality Monitoring
3.6.3.1 Blips and BIPs
3.6.4 Remote Error Monitoring
3.6.5 Performance Measures
3.7 SUMMARY
3.1 Introduction
In the previous chapter, we described TDM and how it has been utilized in SONET and SDH standards. We noted that when SONET and SDH were developed, they were optimized for carrying voice traffic. At that time no one anticipated the tremendous growth in data traffic that would arise due to the Internet phenomenon. Today, the volume of data traffic has surpassed voice traffic in most networks, and it is still growing at a steady pace. In order to handle data traffic efficiently, a number of new features have been added to SONET and SDH.
In this chapter, we review some of the advanced features of SONET and SDH. Specifically, we describe the different ways of concatenating SONET and SDH signals, and different techniques for mapping packet data onto SONET and SDH connections. We also address transparency services for carrier’s carrier applications, as well as fault management and performance monitoring capabilities. The subject matter covered in this chapter will be used as a reference when we discuss optical control plane issues in later chapters. A rigorous understanding of this material, however, is not a prerequisite for dealing with the control plane topics.
3.2 All about Concatenation
Three types of concatenation schemes are possible under SONET and SDH. These are:
Standard contiguous concatenation
Arbitrary contiguous concatenation
Virtual concatenation
These concatenation schemes are described in detail next.
3.2.1 Standard Contiguous Concatenation in SONET and SDH
SONET and SDH networks support contiguous concatenation whereby a few standardized “concatenated” signals are defined, and each concatenated signal is transported as a single entity across the network [ANSI95a, ITU-T00a]. This was described briefly in the previous chapter.
The concatenated signals are obtained by “gluing” together the payloads of the constituent signals, and they come in fixed sizes. In SONET, these are called STS-Nc Synchronous Payload Envelopes (SPEs), where N = 3X and X is restricted to the values 1, 4, 16, 64, or 256. In SDH, these are called VC-4 (equivalent to STS-3c SPE), and VC-4-Xc where X is restricted to 1, 4, 16, 64, or 256.
The multiplexing procedures for SONET (SDH) introduce additional constraints on the location of component STS-1 SPEs (VC-4s) that comprise the STS-NcSPE (VC-4-Xc). The rules for the placement of standard concatenated signals are [ANSI95a]:
Concatenation of three STS-1s within an STS-3c: The bytes from concatenated STS-1s shall be contiguous at the STS-3 level but shall not be contiguous when interleaved to higher-level signals. When STS-3c signals are multiplexed to a higher rate, each STS-3c shall be wholly contained within an STS-3 (i.e., occur only on tributary input boundaries 1–3, 4–6, 7–9, etc.). This rule does not apply to SDH.
Concatenation of STS-1s within an STS-Nc (N = 3X, where X = 1, 4, 16, 64, or 256). Such concatenation shall treat STS-Nc signals as a single entity. The bytes from concatenated STS-1s shall be contiguous at the STS-N level, but shall not be contiguous when multiplexed on to higher-level signals. This also applies to SDH, where the SDH term for an STS-Nc is an AU-4-Xc where X = N/3.
When the STS-Nc signals are multiplexed to a higher rate, these signals shall be wholly contained within STS-M boundaries, where M could be 3, 12, 48, 192, or 768, and its value must be the closest to, but greater than or equal to N (e.g., if N = 12, then the STS-12c must occur only on boundaries 1–12, 13–24, 25–36, etc.). In addition to being contained within STS-M boundaries, all STS-Nc signals must begin on STS-3 boundaries.
The primary purpose of these rules is to ease the development burden for hardware designers, but they can seriously affect the bandwidth efficiency of SONET/SDH links.
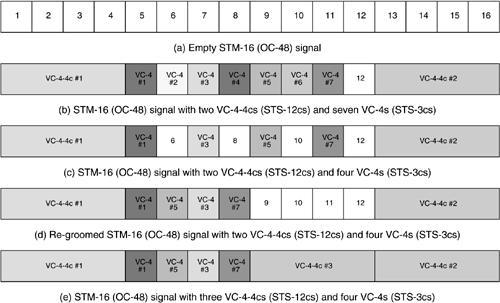
In Figure 3-1(a), an STM-16 (OC-48) signal is represented as a set of 16 time slots, each of which can contain a VC-4 (STS-3c SPE). Let us examine the placement of VC-4 and VC-4-4c (STS-3c and STS-12c SPE) signals into this structure, in line with the rules above. In particular a VC-4-4c (STS-12c SPE) must start on boundaries of 4. Figure 3-1(b) depicts how the STM-16 has been filled with two VC-4-4c (STS-12c) and seven VC-4 signals. In Figure 3-1(c), three of the VC-4s have been removed, that is, are no longer in use. Due to the placement restrictions, however, a VC 4-4c cannot be accommodated in this space. In Figure 3-1(d), the STM-16 has been “regroomed,” that is, VC-4 #5 and VC-4 #7 have been moved to new timeslots. Figure 3-1(e) shows how the third VC-4-4c is accommodated.
Figure 3-1. Timeslot Constraints and Regrooming with Contiguous (Standard) Concatenation
3.2.2 Arbitrary Concatenation
In the above example, a “regrooming” operation was performed to make room for a signal that could not be accommodated with the standard contiguous concatenation rules. The problem with regrooming is that it is service impacting, that is, service is lost while the regrooming operation is in progress. Because service impacts are extremely undesirable, regrooming is not frequently done, and the bandwidth is not utilized efficiently.
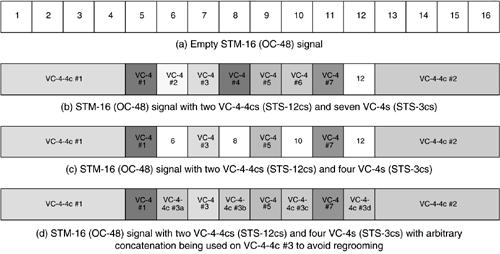
To get around these restrictions, some manufacturers of framers, that is, the hardware that processes the SDH multiplex section layer (SONET line layer), offer a capability known as “flexible” or arbitrary concatenation. With this capability, there are no restrictions on the size of an STS-Nc (VC-4-Xc) or the starting time slot used by the concatenated signal. Also, there are no constraints on adjacencies of the STS-1 (VC-4-Xc) time slots used to carry it, that is, the signals can use any combination of available time slots. Figure 3-2 depicts how the sequence of signals carried over the STM-16 of Figure 3-1 can be accommodated without any regrooming, when the arbitrary concatenation capability is available.
Figure 3-2. Timeslot Usage with Arbitrary Concatenation
3.2.3 Virtual Concatenation
As we saw earlier, arbitrary concatenation overcomes the bandwidth inefficiencies of standard contiguous concatenation by removing the restrictions on the number of components and their placement within a larger concatenated signal. Standard and arbitrary contiguous concatenation are services offered by the network, that is, the network equipment must support these capabilities. The ITU-T and the ANSI T1 committee have standardized an alternative, called virtual concatenation. With virtual concatenation, SONET and SDH PTEs can “glue” together the VCs or SPEs of separately transported fundamental signals. This is in contrast to requiring the network to carry signals as a single concatenated unit.
3.2.3.1 HIGHER-ORDER VIRTUAL CONCATENATION (HOVC)
HOVC is realized under SONET and SDH by the PTEs, which combine either multiple STS-1/STS-3c SPEs (SONET), or VC-3/VC-4 (SDH). Recall that the VC-3 and STS-1 SPE signals are nearly identical except that a VC-3 does not contain the fixed stuff bytes found in columns 30 and 59 of an STS-1 SPE. A SONET STS-3c SPE is equivalent to a SDHVC-4.
These component signals, VC-3s or VC-4s (STS-1 SPEs or STS-3c SPEs), are transported separately through the network to an end system and must be reassembled. Since these signals can take different paths through the network, they may experience different propagation delays. In addition to this fixed differential delay between the component signals, there can also be a variable delay component that arises due to the different types of equipment processing the signals and the dynamics of the fiber itself. Note that heating and cooling effects can affect the propagation speed of light in a fiber, leading to actual measurable differences in propagation delay.
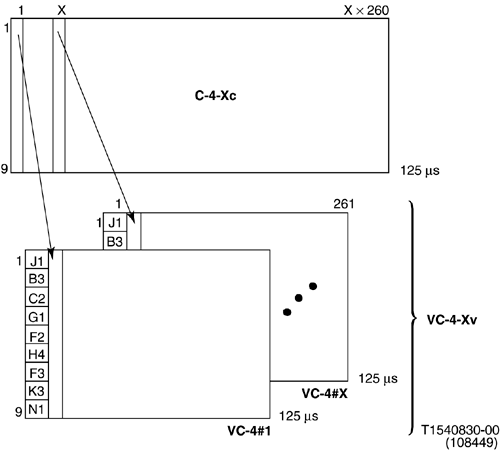
The process of mapping a concatenated container signal, that is, the raw data to be transported, into a virtually concatenated signal is shown in Figure 3-3. Specifically, at the transmitting side, the payload gets packed in XVC-4s just as if these were going to be contiguously concatenated. Now the question is, How do we identify the component signals and line them up appropriately given that delays for the components could be different?
Figure 3-3. Mapping a Higher Rate Payload in a Virtually Concatenated Signal (from [ITU-T00a])
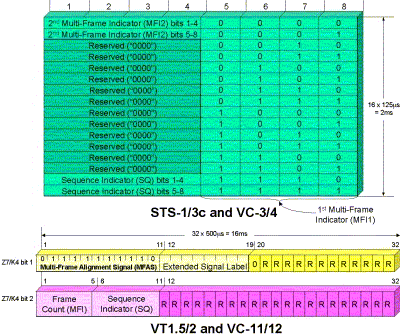
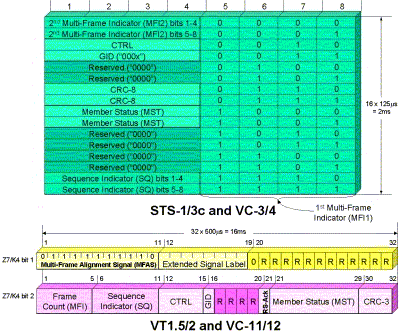
The method used to align the components is based on the multiframe techniques described in Chapter 2. A jumbo (very long) multiframe is created by overloading the multiframe byte H4 in the path overhead. Bits 5–8 of the H4 byte are incremented in each 125µs frame to produce a multiframe consisting of 16 frames. In this case, bits 5–8 of H4 are known as the multiframe indicator 1 (MFI1). This multiframe will form the first stage of a two-stage multiframe. In particular, bits 1–4 of the H4 byte are used in a way that depends on the position in the first stage of the multiframe. This is shown in Table 3-1.
Within the 16-frame first stage multiframe, a second stage multiframe indicator (MFI2) is defined utilizing bits 1–4 of H4 in frames 0 and 1, giving a total of 8 bits per frame. It is instructive to examine the following:
How long in terms of the number of 125µs frames is the complete HOVC multiframe structure? Answer: The base frame (MFI1) is 16 frames long, and the second stage is 28 = 256 frames long. Since this is a two-stage process, the lengths multiply giving a multiframe that is 16 × 256 = 4096 frames long.
What is the longest differential delay, that is, delay between components that can be compensated? Answer: The differential delay must be within the duration of the overall multiframe structure, that is, 125µS × 4096 = 512mS, that is, a little over half a second.
Suppose that an STS-1-2v is set up for carrying Ethernet traffic between San Francisco and New York such that one STS-1 goes via a satellite link and the other via conventional terrestrial fiber. Will this work? Answer: Assuming that a geo-synchronous satellite is used, then the satellite’s altitude would be about 35775 km. Given that the speed of light is 2.99792 × 108 m/sec, this leads to a round trip delay of about 239 ms. If the delay for the fiber route is 20 ms, then the differential delay is 209 ms, which is within the virtual concatenation range. Also, since the average circumference of the earth is only 40,000 km, this frame length should be adequate for the longest fiber routes.
Table 3-1. Use of Bits 1–4 in H4 Byte for First Stage Multiframe Indication (MFI1)
Multi-Frame Indicator 1 (MFI1)
Meaning of Bits 1–4 in H4
0
2nd multiframe indicator MFI2 MSB (bits 1–4)
1
2nd multiframe indicator MFI2 LSB (bits 5–8)
2–13
Reserved (0000)
14
Sequence indicator SQ MSB (bits 1–4)
15
Sequence indicator SQ LSB (bits 5–8)
Now, the receiver must be able to distinguish the different components of a virtually concatenated signal. This is accomplished as follows. In frames 14 and 15 of the first stage multiframe, bits 1–4 of H4 are used to give a sequence indicator (SQ). This is used to indicate the components (and not the position in the multiframe). Due to this 8-bit sequence indicator, up to 256 components can be accommodated in HOVC. Note that it is the receiver’s job to compensate for the differential delay and to put the pieces back together in the proper order. The details of how this is done are dependent on the specific implementation.
3.2.3.2 LOWER-ORDER VIRTUAL CONCATENATION (LOVC)
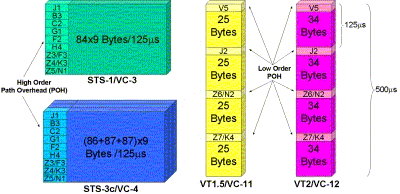
The virtual concatenation of lower-order signals such as VT1.5s (VC-11), VT2 (VC-12), and so on are based on the same principles as described earlier. That is, a sequence number is needed to label the various components that make up the virtually concatenated signal, and a large multiframe structure is required for differential delay compensation. In the lower-order case, however, there are fewer overhead bits and bytes to spare so the implementation may seem a bit complex. Let us therefore start with the capabilities obtained.
LOVC Capabilities and Limitations
Table 3-2 lists the LOVC signals for SONET/SDH, the signals they can be contained in and the limits on the number of components that can be concatenated. The last two columns are really the most interesting since they show the range of capacities and the incremental steps of bandwidth.
LOVC Implementation
Let us first examine how the differential delay compensating multiframe is put together. This is done in three stages. Recall that the SONETVT overhead (lower-order SDHVC overhead) is defined in a 500 µs multiframe, as indicated in the path layer multiframe indicator H4. This makes available the four VT overhead bytes V5, J2, Z6, and Z7, from one SONET/SDH frame byte. Since a number of bits in these bytes are used for other purposes, an additional second stage of multiframe structure is used to define extended VT signal labels.
This works as follows (note that SDH calls the Z7 byte as K4 but uses it the same way): First of all, the V5 byte indicates if the extended signal label is being used. Bits 5 through 7 of V5 provide a VT signal label. The signal label value of 101 indicates that a VT mapping is given by the extended signal label in the Z7 byte. If this is the case, then a 1-bit frame alignment signal “0111 1111 110” is sent in bit 1 of Z7, called the extended signal label bit. The length of this second stage VT level multiframe (which is inside the 500 µs VT multiframe) is 32 frames. The extended signal label is contained in bits 12–19 of the multiframe. Multiframe position 20 contains “0.” The remaining 12 bits are reserved for future standardization.
Table 3-2. Standardized LOVC Combinations and Limits
Signal SONET/SDH
Carried in SONET/SDH
X
Capacity (kbit/s)
In steps of (kbit/s)
VT1.5-Xv SPE/VC-11-Xv
STS-1/VC-3
1 to 28
1600 to 44800
1600
VT2-Xv SPE/VC-12-Xv
STS-1/VC-3
1 to 21
2176 to 45696
2176
VT3-Xv SPE
STS-1
1 to 14
3328 to 46592
3328
VT6-Xv SPE/VC-2-Xv
STS-1/VC-3
1 to 7
6784 to 47448
6784
VT1.5/VC-11-Xv
STS-3c
1 to 64
1600 to 102400
1600
VT2/VC-12-Xv
STS-3c
1 to 63
2176 to 137088
2176
VT3-Xv SPE
STS-3c
1 to 42
3328 to 139776
3328
VT6-Xv SPE/VC-2-Xv
STS-3c
1 to 21
6784 to 142464
6784
VT1.5/VC-11-Xv
unspecified
1 to 64
1600 to 102400
1600
VT2/VC-12-Xv
unspecified
1 to 64
2176 to 139264
2176
VT3-Xv SPE
unspecified
1 to 64
3328 to 212992
3328
VT6-Xv SPE
unspecified
1 to 64
6784 to 434176
6784
Note: X is limited to 64 due the sequence indicator having 6 bits.
Bit 2 of the Z7 byte is used to convey the third stage of the multistage multiframe in the form of a serial string of 32 bits (over 32 four-frame multi-frames and defined by the extended signal label). This is shown in Figure 3-4. This string is repeated every 16 ms (32 bits × 500 µs/bit) or every 128 frames.
Figure 3-4. Third Stage of LOVC Multiframe Defined by Bit 2 of the Z7 Byte over the 32 Frame Second Stage Multiframe
The third stage string consists of the following fields: The third stage virtual concatenation frame count is contained in bits 1 to 5. The LOVC sequence indicator is contained in bits 6 to 11. The remaining 21 bits are reserved for future standardization.
Let us now consider a concrete example. Suppose that there are three stages of multiframes with the last stage having 5 bits dedicated to frame counting. What is the longest differential delay that can be compensated and in what increments? The first stage was given by the H4 byte and is of length 4, resulting in 4 × 125 µs = 500 µs. The second stage was given by the extended signal label (bit 1 of Z7) and it is of length 32. Since this is inside the first stage, the lengths multiply, resulting in 32 × 500 µs = 16 ms. The third stage, which is within the 32-bit Z7 string, has a length of 25 = 32 and is contained inside the second stage. Hence, the lengths multiply, resulting in 32 × 16 ms = 512 ms. This is the same compensation we showed with HOVC. Since the sequence indicator of the third stage is used to line up the components, the delay compensation is in 16 ms increments.
3.3 Link Capacity Adjustment Scheme
Virtual concatenation allows the flexibility of creating SONET/SDH pipes of different sizes. The Link Capacity Adjustment Scheme or LCAS [ITU-T01a] is a relatively new addition to the SONET/SDH standard. It is designed to increase or decrease the capacity of a Virtually Concatenated Group (VCG) in a hitless fashion. This capability is particularly useful in environments where dynamic adjustment of capacity is important. The LCAS mechanism can also automatically decrease the capacity if a member in a VCG experiences a failure in the network, and increase the capacity when the fault is repaired. Although autonomous addition after a failure is repaired is hitless, removal of a member due to path layer failures is not hitless. Note that a “member” here refers to a VC (SDH) or an SPE (SONET). In the descriptions below, we use the term member to denote a VC.
Note that virtual concatenation can be used without LCAS, but LCAS requires virtual concatenation. LCAS is resident in the H4 byte of the path overhead, the same byte as virtual concatenation. The H4 bytes from a 16-frame sequence make up a message for both virtual concatenation and LCAS. Virtual concatenation uses 4 of the 16 bytes for its MFI and sequence numbers. LCAS uses 7 others for its purposes, leaving 5 reserved for future development. While virtual concatenation is a simple labeling of individual STS-1s within a channel, LCAS is a two-way handshake protocol. Status messages are continuously exchanged and consequent actions taken.
From the perspective of dynamic provisioning enabled by LCAS, each VCG can be characterized by two parameters:
XMAX, which indicates the maximum size of the VCG and it is usually dictated by hardware and/or standardization limits
XPROV, which indicates the number of provisioned members in the VCG
With each completed ADD command, XPROV increases by 1, and with each completed REMOVE command XPROV decreases by 1. The relationship 0 ≤ XPROV ≤ XMAX always holds. The operation of LCAS is unidirectional. This means that in order to bidirectionally add or remove members to or from a VCG, the LCAS procedure has to be repeated twice, once in each direction. These actions are independent of each other, and they are not required to be synchronized.
The protocols behind LCAS are relatively simple. For each member in the VCG (total of XMAX), there is a state machine at the transmitter and a state machine at the receiver. The state machine at the transmitter can be in one of the following five states:
IDLE: This member is not provisioned to participate in the VCG.
NORM: This member is provisioned to participate in the VCG and has a good path to the receiver.
DNU: This member is provisioned to participate in the VCG and has a failed path to the receiver.
ADD: This member is in the process of being added to the VCG.
REMOVE: This member is in the process of being deleted from the VCG.
The state machine at the receiver can be in one of the following three states:
IDLE: This member is not provisioned to participate in the VCG.
OK: The incoming signal for this member experiences no failure condition. Or, the receiver has received and acknowledged a request for addition of this member.
FAIL: The incoming signal for this member experiences some failure condition, or an incoming request for removal of a member has been received and acknowledged.
The transmitter and the receiver communicate using control packets to ensure smooth transition from one state to another. The control packets consist of XMAX control words, one for each member of the VCG. The following control words are sent from source to the receiver in order to carry out dynamic provisioning functions. Each word is associated with a specific member (i.e., VC) in the VCG.
FADD: Add this member to the group.
FDNU: Delete this member from the group.
FIDLE: Indicate that this VC is currently not a member of the group.
FEOS: Indicate that this member has the highest sequence number in the group (EOS denotes End of Sequence).
FNORM: Indicate that this member is normal part of the group and does not have the highest sequence number.
The following control words are sent from the receiver to the transmitter. Each word is associated with a specific VC in the VCG.
RFAIL and ROK: These messages capture the status of all the VCG members at the receiver. The status of all the members is returned to the transmitter in the control packets of each member. The transmitter can, for example, read the information from member No. 1 and, if that is unavailable, the same information from member No. 2, and so on. As long as no return bandwidth is available, the transmitter uses the last received valid status.
RRS_ACK: This is a bit used to acknowledge the detection of renumbering of the sequence or a change in the number of VCG members. This acknowledgment is used to synchronize the transmitter and the receiver.
The following is a typical sequence for adding a member to the group. Multiple members can be added simultaneously for fast resizing.
The network management system orders the source to add a new member (e.g., a VC) to the existing VCG.
The source node starts sending FADD control commands in the selected member. The destination notices the FADD command and returns an ROK in the link status for the new member.
The source sees the ROK, assigns the member a sequence number that is one higher than the number currently in use.
At a frame boundary, the source includes the VC in the byte interleaving and sets the control command to FEOS, indicating that this VC is in use and it is the last in the sequence.
The VC that previously was “EOS ” now becomes “NORM” (normal) as it is no longer the one with the highest sequence number.
The following is a typical sequence for deleting the VC with the highest sequence number (EOS) from a VCG:
The network management system orders the source to delete a member from the existing VCG.
The source node starts sending FIDLE control commands in the selected VC. It also sets the member with the next highest sequence number as the EOS and sends FEOS in the corresponding control word.
The destination notices the FIDLE command and immediately drops the channel from the reassembly process. It also responds with RFAIL and inverts the RRS_ACK bit.
In this example, the deleted member has the highest sequence number. If this is not the case, then the other members with sequence numbers between the newly deleted member and the highest sequence number are renumbered.
LCAS and virtual concatenation add tremendous amount of flexibility to SONET and SDH. Although SONET and SDH were originally designed to transport voice traffic, advent of these new mechanisms has made it perfectly suitable for carrying more dynamic and bursty data traffic. In the next section, we discuss mechanisms for mapping packet payloads into SONET and SDH SPEs.
3.4 Payload Mappings
So far, the multiplexing structure of SONET and SDH has been described in detail. To get useful work out of these different sized containers, a payload mapping is needed, that is, a systematic method for inserting and removing the payload from a SONET/SDH container. Although it is preferable to use standardized mappings for interoperability, a variety of proprietary mappings may exist for various purposes.
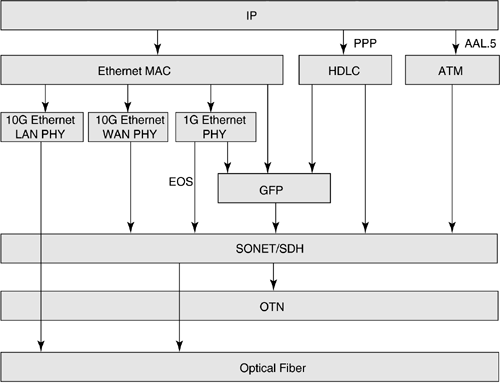
In this regard, one of the most important payloads carried over SONET/SDH is IP. Much of the bandwidth explosion that set the wheels in motion for this book came from the growth in IP services. Hence, our focus is mainly on IP in the rest of this chapter. Figure 3-5 shows different ways of mapping IP packets into SONET/SDH frames. In the following, we discuss some of these mechanisms.
Figure 3-5. Different Alternatives for Carrying IP Packets over SONET
3.4.1 IP over ATM over SONET
The “Classical IP over ATM” solution supports robust transmission of IP packets over SONET/SDH using ATM encapsulation. Under this solution, each IP packet is encapsulated into an ATM Adaptation Layer Type 5 (AAL5) frame using multiprotocol LLC/SNAP encapsulation [Perez+95]. The resulting AAL5 Protocol Data Unit (PDU) is segmented into 48-byte payloads for ATM cells. ATM cells are then mapped into a SONET/SDH frame.
One of the problems with IP-over-ATM transport is that the protocol stack may introduce a bandwidth overhead as high as 18 percent to 25 percent. This is in addition to the approximately 4 percent overhead needed for SONET. On the positive side, ATM permits sophisticated traffic engineering, flexible routing, and better partitioning of the SONET/SDH bandwidth. Despite the arguments on the pros and cons of the method, IP-over-ATM encapsulation continues to be one of the main mechanisms for transporting IP over SONET/SDH transport networks.
3.4.2 Packet over SONET/SDH
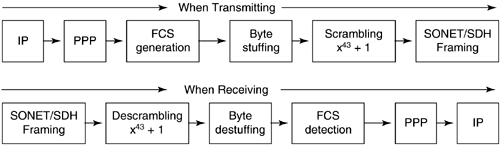
ATM encapsulation of IP packets for transport over SONET/SDH can be quite inefficient from the perspective of bandwidth utilization. Packet over SONET/SDH (or POS) addresses this problem by eliminating the ATM encapsulation, and using the Point-to-Point Protocol (PPP) defined by the IETF [Simpson94]. PPP provides a general mechanism for dealing with point-to-point links and includes a method for mapping user data, a Link Control Protocol (LCP), and assorted Network Control Protocols (NCPs). Under POS, PPP encapsulated IP packets are framed using high-Level Data Link Control (HDLC) protocol and mapped into the SONETSPE or SDHVC [Malis+99]. The main function of HDLC is to provide framing, that is, delineation of the PPP encapsulated IP packets across the synchronous transport link. Standardized mappings for IP into SONET using PPP/HDLC have been defined in IETF RFC 2615 [Malis+99] and ITU-T Recommendation G.707 [ITU-T00a].
Elimination of the ATM layer under POS results in more efficient bandwidth utilization. However, it also eliminates the flexibility of link bandwidth management offered by ATM. POS is most popular in backbone links between core IP routers running at 2.5 Gbps and 10 Gbps speeds. IP over ATM is still popular in lower-speed access networks, where bandwidth management is essential.
During the initial deployment of POS, it was noticed that the insertion of packets containing certain bit patterns could lead to the generation of the Loss of Frame (LOF) condition. The problem was attributed to the relatively short period of the SONET section (SDH regenerator section) scrambler, which is only 127 bits and synchronized to the beginning of the frame. In order to alleviate the problem, an additional scrambling operation is performed on the HDLC frames before they are placed into the SONET/SDH SPEs. This procedure is depicted in Figure 3-6.
Figure 3-6. Packet Flow for Transmission and Reception of IP over PPP over SONET/SDH
3.4.3 Generic Framing Procedure (GFP)
GFP [ITU-T01b] was initially proposed as a solution for transporting data directly over dark fibers and WDM links. But due to the huge installed base of SONET/SDH networks, GFP soon found applications in SONET/SDH networks. The basic appeal of GFP is that it provides a flexible encapsulation framework for both block-coded [Gorsche+02] and packet oriented [Bonenfant+02] data streams. It has the potential of replacing a plethora of proprietary framing procedures for carrying data over existing SONET/SDH and emerging WDM/OTN transport.
GFP supports all the basic functions of a framing procedure including frame delineation, frame/client multiplexing, and client data mapping [ITU-T01b]. GFP uses a frame delineation mechanism similar to ATM, but generalizes it for both fixed and variable size packets. As a result, under GFP, it is not necessary to search for special control characters in the client data stream as required in 8B/10B encoding,1 or for frame delineators as with HDLC framing. GFP allows flexible multiplexing whereby data emanating from multiple clients or multiple client sessions can be sent over the same link in a point-to-point or ring configuration. GFP supports transport of both packet-oriented (e.g., Ethernet, IP, etc.) and character-oriented (e.g., Fiber Channel) data. Since GFP supports the encapsulation and transport of variable-length user PDUs, it does not need complex segmentation/reassembly functions or frame padding to fill unused payload space. These careful design choices have substantially reduced the complexity of GFP hardware, making it particularly suitable for high-speed transmissions.
In the following section, we briefly discuss the GFP frame structure and basic GFP functions.
3.4.3.1 GFP FRAME STRUCTURE
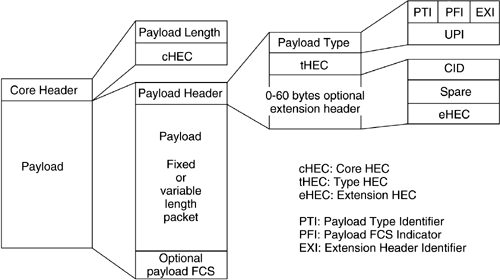
A GFP frame consists of a core header and a payload area, as shown in Figure 3-7. The GFP core header is intended to support GFP-specific data link management functions. The core header also allows GFP frame delineation independent of the content of the payload. The GFP core header is 4 bytes long and consists of two fields:
A 2-byte field indicating the size of the GFP payload area in bytes.
Core Header Error Correction (cHEC) Field
A 2-octet field containing a cyclic redundancy check (CRC) sequence that protects the integrity of the core header.
The payload area is of variable length (0–65,535 octets) and carries client data such as client PDUs, client management information, and so on. Structurally, the payload area consists of a payload header and a payload information field, and an optional payload Frame Check Sequence (FCS) field. The FCS information is used to detect the corruption of the payload.
Payload Header
The variable length payload header consists of a payload type field and a type Header Error Correction (tHEC) field that protects the integrity of the payload type field. Optionally, the payload header may include an extension header. The payload type field consists of the following subfields:
Payload Type Identifier (PTI): This subfield identifies the type of frame. Two values are currently defined: user data frames and client management frames.
Payload FCS Indicator (PFI): This subfield indicates the presence or absence of the payload FCS field.
Extension Header Identifier (EXI): This subfield identifies the type of extension header in the GFP frame. Extension headers facilitate the adoption of GFP for different client-specific protocols and networks. Three kinds of extension headers are currently defined: a null extension header, a linear extension header for point-to-point networks, and a ring extension header for ring networks.
User Payload Identifier (UPI): This subfield identifies the type of payload in the GFP frame. The UPI is set according to the transported client signal type. Currently defined UPI values include Ethernet, PPP (including IP and MPLS), Fiber Channel [Benner01], FICON [Benner01], ESCON [Benner01], and Gigabit Ethernet. Mappings for 10/100 Mb/s Ethernet and digital video broadcast, among others, are under consideration.
Payload Information Field
This field contains the client data. There are two modes of client signal payload adaptation defined for GFP: frame-mapped GFP (GFP-F) applicable to most packet data types, and transparent-mapped GFP (GFP-T) applicable to 8B/10B coded signals. Frame-mapped GFP payloads consist of variable length packets. In this mode, client frame is mapped in its entirety into one GFP frame. Examples of such client signals include Gigabit Ethernet and IP/PPP. With transparent-mapped GFP, a number of client data characters, mapped into efficient block codes, are carried within a GFP frame.
3.4.3.2 GFP FUNCTIONS
The GFP frame structure was designed to support the basic functions provided by GFP, namely, frame delineation, client/frame multiplexing, header/payload scrambling, and client payload mapping. In the following, we discuss each of these functions.
Frame Delineation
The GFP transmitter and receiver operate asynchro nously. The transmitter inserts GFP frames on the physical link according to the bit/byte alignment requirements of the specific physical interface (e.g., SONET/SDH, OTN, or dark fiber). The GFP receiver is responsible for identifying the correct GFP frame boundary at the time of link initialization, and after link failures or loss of frame events. The receiver “hunts” for the start of the GFP frame using the last received four octets of data. The receiver first computes the cHEC value based on these four octets. If the computed cHEC matches the value in the (presumed) cHEC field of the received data, the receiver tentatively assumes that it has identified the frame boundary. Otherwise, it shifts forward by 1 bit and checks again. After a candidate GFP frame has been identified, the receiver waits for the next candidate GFP frame based on the PLI field value. If a certain number of consecutive GFP frames are detected, the receiver transitions into a regular operational state. In this state, the receiver examines the PLI field, validates the incoming cHEC field, and extracts the framed PDU.
Client/Frame Multiplexing
GFP supports both frame and client multiplexing. Frames from multiple GFP processes, such as idle frames, client data frames, and client management frames, can be multiplexed on the same link. Client data frames get priority over management frames. Idle frames are inserted when neither data nor management frames are available for transmission.
GFP supports client-multiplexing capabilities via the GFP linear and ring extension headers. For example, linear extension headers (see Figure 3-7) contain an 8-bit channel ID (CID) field that can be used to multiplex data from up to 256 client sessions on a point-to-point link. An 8-bit spare field is available for future use. Various proposals for ring extension headers are currently being considered for sharing GFP payload across multiple clients in a ring environment.
Header/Payload Scrambling
Under GFP, both the core header and the payload area are scrambled. Core header scrambling ensures that an adequate number of 0-1 transitions occur during idle data conditions (thus allowing the receiver to stay synchronized with the transmitter). Scrambling of the GFP payload area ensures correct operation even when the payload information is coincidentally the same as the scrambling word (or its inverse) from frame-synchronous scramblers such as those used in the SONET line layer (SDHRS layer).
Client Payload Mapping
As mentioned earlier, GFP supports two types of client payload mapping: frame-mapped and transparent-mapped. Frame mapping of native client payloads into GFP is intended to facilitate packet-level handling of incoming PDUs. Examples of such client signals include IEEE 802.3 Ethernet MAC frames, PPP/IP packets, or any HDLC framed PDU. Here, the transmitter encapsulates an entire frame of the client data into a GFP frame. Frame multiplexing is supported with frame-mapped GFP. Frame-mapped GFP uses the basic frame structure of a GFP client frame, including the required payload header.
Transparent mapping is intended to facilitate the transport of 8B/10B block-coded client data streams with low transmission latency. Transparent mapping is particularly applicable to Fiber Channel, ESCON, FICON, and Gigabit Ethernet. Instead of buffering an entire client frame and then encapsulating it into a GFP frame, the individual characters of the client data stream are extracted, and a fixed number of them are mapped into periodic fixed-length GFP frames. The mapping occurs regardless of whether the client character is a data or control character, which thus preserves the client 8B/10B control codes. Frame multiplexing is not precluded with transparent GFP. The transparent GFP client frame uses the same structure as the frame-mapped GFP, including the required payload header.
3.4.4 Ethernet over SONET/SDH
As shown in Figure 3-5, there are different ways of carrying Ethernet frames over SONET/SDH, OTN, and optical fiber. Ethernet MAC frames can be encapsulated in GFP frames and carried over SONET/SDH. Also shown in the figure are the different physical layer encoding schemes, including Gigabit Ethernet physical layer, and 10Gigabit Ethernet physical (PHY) layer optimized for LAN and WAN. Gigabit Ethernet physical layer is 8B/10B coded data stream, and it can be encapsulated into GFP frames and carried over SONET/SDH. 10-Gigabit Ethernet WAN PHY is SONET/SDH encoded, and hence it can be directly mapped into STS-192/STM-16 frames.
3.5 SONET/SDH Transparency Services
SONET and SDH have the following notions of transparency built-in, as described in Chapter 2:
Path transparency, as provided by the SONET line and SDH multiplex section layers. This was the original intent of SONET and SDH, that is, transport of path layer signals transparently between PTEs.
SONET line and SDH multiplex section transparency, as provided by the SONET section and SDH regenerator section layers, respectively.
SONET section and SDH regenerator section transparency, as provided by the physical layer.
Of these, only (1) was considered a “user service” within SONET and SDH. There are reasons now to consider (2) and (3) as services, in addition to newer transparency services.
Figure 3-8 shows a typical scenario where transparency services may be desired. Here, two SONET networks (labeled “Domain 1”) are separated by an intervening optical transport network of some type (labeled “Domain 2”). For instance, Domain 1 could consist of two metro networks under a single administration, separated by a core network (Domain 2) under a different administration. The two disjoint parts of Domain 1 are interconnected by provisioning a “link” between network elements NE1 and NE2, as shown. The characteristics of this link depend on the type of transparency desired. In general, transparency allows NE1 and NE2 to use the functionality provided by SONET overhead bytes in various layers. For instance, section transparency allows the signal from NE1 to NE2 to pass through Domain 2 without any overhead information being modified in transit. An all-optical network or a network with transparent regenerators can provide section layer transparency. This service is equivalent to having a dedicated wavelength (lambda) between NE1 and NE2. Thus, the service is often referred to as a lambda service, even if the signal is electrically regenerated within the network. Section transparency allows NE1 and NE2 to terminate the section layer and use the section (and higher layer) overhead bytes for their own purposes.
Figure 3-8. Networking Scenario Used to Define SONET/SDH Transparency Services
If the OC-N to be transported between NE1 and NE2 is the same size (in terms of capacity) as those used within the optical network, then the section transparency service is a reasonable approach. If the optical network, however, deals with signals much larger than these OC-N signals, then there is the potential for inefficient resource utilization. For example, suppose the optical network is composed of DWDM links and switches that can effectively deal with OC-192 signals. A “lambda” in this network could indeed accommodate an OC-12 signal, but only 1/16th of the capacity of that lambda will be used. In such a case, the OC-12 signal has to be multiplexed in some way into an OC-192 signal. But SONET (SDH) multiplexing takes place at the line (multiplex section) layer. Hence, there is no standard way to convey the OC-12 overhead when multiplexing the constituent path signals into an OC-192 signal. This means that section and line overhead bytes presented by NE1 will be modified within Domain 2. How then to transfer the overhead bytes transparently across Domain 2? Before we examine the methods for accomplishing this, it is instructive to look at the functionality provided by overhead bytes and what it means to support transparency.
Tables 3-3 and 3-4 list the overhead bytes available at different layers, the functionality provided and when the bytes are updated (refer to Figures 2-4 and 2-5).
These are repeated in all STS-1 signals within an OC-N. No impact on transparency.
J0 (Trace)
Only conveyed in the 1st STS-1, and covers entire frame. J0 bytes in signals 2–N are reserved for growth, i.e., Z0. Used to identify entire section layer signal.
B1 (Section BIP-8)
Only conveyed in the 1st STS-1, and covers entire frame. B1 bytes in signals 2–N are undefined. B1 byte must be updated if section, line or path layer content changes.
E1 (Orderwire)
F1 (User)
Only conveyed in the 1st STS-1, and covers for entire frame. E1 and F1 in signals 2–N are undefined.
D1-D3 (Section DCC)
Only conveyed in the 1st STS-1, and covers the entire frame. D1-D3 bytes in signals 2–N are undefined.
Table 3-4. SONET Line (SDH Multiplex Section) Overhead Bytes and Functionality
Overhead Bytes
Comments
H1, H2, H3 (Pointer bytes)
These are repeated in all STS-1s within an STS-N.
B2 (Line BIP-8)
This is used for all STS-1s within an STS-N. Must be updated if line or path layer content changes. Used to determine signal degrade conditions.
K1, K2 (APS bytes)
Only conveyed in the 1st STS-1 signal, and covers entire line. This space in signals 2 – N are undefined. This is the line APS functionality.
D4-D12 (Line DCC)
Only conveyed in the 1st STS-1 for the entire line. D4–D12 bytes in signals 2 – N are undefined.
S1 (Synchronization byte)
Only conveyed in the 1st STS-1, and carries the synchronization status message for the entire line. S1 bytes in STS-1 signals 2 – N are reserved for growth (Z1 byte). Note that if a re-multiplexing operation were to take place, this byte cannot be carried through.
M0, M1, (Line, Remote Error indication)
M0 or M1 is conveyed in the Nth STS of the STS-N signal. If N > 1, this byte is called M1. If N = 1, this byte is called M0. When N > 1, the corresponding bytes in signals 1 to N – 1 are reserved for growth (Z2 byte).
E2 (Line order wire)
Only conveyed in the 1st STS-1, and covers the entire line. The E2 bytes in signals 2 – N are undefined.
With standard SONET/SDH path layer multiplexing, the H1–H3 (pointer) bytes must be modified when the clocks are different for the streams to be multiplexed. The B2 byte must be updated when any of the line layer bytes are changed. Also related to timing is the S1 byte, which reports on the synchronization status of the line. This byte has to be regenerated if multiplexing is performed. Thus, it is not possible to preserve all the overhead bytes when the signal from NE1 is multiplexed with other signals within Domain 2. The additional procedures that must be performed to achieve transparency are discussed next.
3.5.1 Methods for Overhead Transparency
We can group the transport overhead bytes into five categories as follows:
Framing bytes A1 and A2, which are always terminated and regenerated
Pointer bytes H1, H2 and H3, which must be adjusted for multiplexing, and the S1 byte
With regard to the network shown in Figure 3-8, the following are different strategies for transparently transporting the general overhead bytes:
Information forwarding: The overhead bytes originating from NE1 are placed into the OC-N signal and remain unmodified in Domain 2.
Information tunneling: Tunneling generally refers to the encapsulation of information to be transported at the ingress of a network in some manner and restoring it at the egress. With respect to Figure 3-8, the overhead bytes originating from NE1 are placed in unused overhead byte locations of the signal transported within Domain 2. These overhead bytes are restored before the signal is delivered to NE2.
As an example of forwarding and tunneling, consider Figure 3-9, which depicts four STS-12 signals being multiplexed into an STS-48 signal within Domain 2. Suppose that the J0 byte of each of these four signals has to be transported transparently. Referring to Table 3-1, it can be noted that the J0 space in signals 2–4 of the STS-48 are reserved, that is, no specific purpose for these bytes is defined within Domain 2. Thus, referring to the structure of the multiplexed overhead information shown in Figure 2-5, the J0 bytes from the second, third, and fourth STS-12 signals can be forwarded unmodified through the intermediate network. This is not true for the J0 byte of the first STS-12, however, since the intermediate network uses the J0 byte in the first STS-1 to cover the entire STS-48 signal (Table 3-1). Hence, the J0 byte of the first STS-12 has to be tunneled by placing it in some unused overhead byte in the STS-48 signal at the ingress and recovering it at the egress.
Figure 3-9. Transparency Example to lllustrate Forwarding and Tunneling
Now, consider the error monitoring bytes, B1 and B2. Their usage is described in detail in section 3.6. Briefly, taking SONET as an example, B1 and B2 bytes contain the parity codes for the section and line portion of the frame, respectively. A node receiving these bytes in a frame uses them to detect errors in the appropriate portions of the frame. According to the SONET specification, B1 and B2 are terminated and regenerated by each STE or LTE, respectively. With regard to the network of Figure 3-8, the following options may be considered for their transport across Domain 2:
Error regeneration: B1 and B2 are simply regenerated at every network hop.
Error forwarding: As before, the B1 and B2 bytes are regenerated at each hop. But instead of simply sending these regenerated bytes in the transmitted frame (as in the previous case), the bytes are XOR’d (i.e., bit wise summed) with the corresponding bytes received. With this process, the B1 or B2 bytes will accumulate all the errors (at the appropriate layer) for the transparently transported signal. The only drawback of this method is that the error counts within Domain 2 would appear artificially high, and to sort out the true error counts, correlation of the errors reported along the transparent signal’s path would be required.
Error tunneling: In this case, the incoming parity bytes (B1 and/or B2) are carried in unused overhead locations within the transport signal in Domain 2. In addition, at each network hop where the bytes are required to be regenerated, the tunneled parity bytes are regenerated and then XOR’d (bit wise binary summation) with the error result that was obtained (by comparing the difference between the received and calculated BIP-8s). In this way, the tunneled parity bytes are kept up to date with respect to errors, and the standard SONET/SDH B1 and B2 bytes are used within Domain 2 without any special error correlation/compensation being performed.
3.5.2 Transparency Service Packages
We have so far looked at the mechanisms for providing transparent transport. From the perspective of a network operator, a more important issue is the determination of the types of transparency services that may be offered. A transparency service package defines which overhead functionality will be transparently carried across the network offering the service. As an example, let us consider the network shown in Figure 3-9 again. The following is a list of individual services that could be offered by Domain 2. These may be grouped in various combinations to create different transparency service packages:
J0 transparency: Allows signal identification across Domain 2.
Section DCC (D1–D3) transparency: Allows STE to STE data communication across Domain 2.
B2 and M0/M1 transparency: Allows line layer error monitoring and indication across Domain 2.
K1 and K2 byte transparency: Allow line layer APS across Domain 2. This service will most likely be used with (3) so that signal degrade conditions can be accurately detected and acted upon.
Line DCC (D4-D12) transparency: Allows LTE to LTE data communication across Domain 2.
E2 transparency: Allows LTE to LTE order wire communication across Domain 2.
Miscellaneous section overhead transparency, that is, E1 and F1.
Whether overhead/error forwarding or tunneling is used is an internal decision made by the domain offering the transparency service, based on equipment capabilities and overhead usage. Note that to make use of equipment capable of transparent services, a service provider must know the overhead usage, termination, and forwarding capabilities of equipment used in the network. For example, the latest release of G.707 [ITU-T00a] allows the use of some of the unused overhead bytes for physical layer forward error correction (FEC). Hence, a link utilizing such a “feature” would have additional restrictions on which bytes could be used for forwarding or tunneling.
3.6 When Things Go Wrong
One of the most important aspects built into optical transport systems is their “self-diagnosis” capability. That is, the ability to detect a problem (i.e., observe a symptom), localize the problem (i.e., find where it originated), and discover the root cause of the problem. In fact, SONET and SDH include many mechanisms to almost immediately classify the root cause of problem. This is done by monitoring the signal integrity between peers at a given layer, and also when transferring a signal from a client (higher) layer into a server (lower) layer (Figure 2-17).
In the following, we first consider the various causes of transport problems. Next, we examine how problems are localized and how signal quality is monitored. Finally, we review the methods and terminology for characterizing problems and their duration.
3.6.1 Transport Problems and Their Detection
Signal monitoring functionality includes the following: continuity supervision, connectivity supervision, and signal quality supervision. These are described next.
3.6.1.1 CONTINUITY SUPERVISION
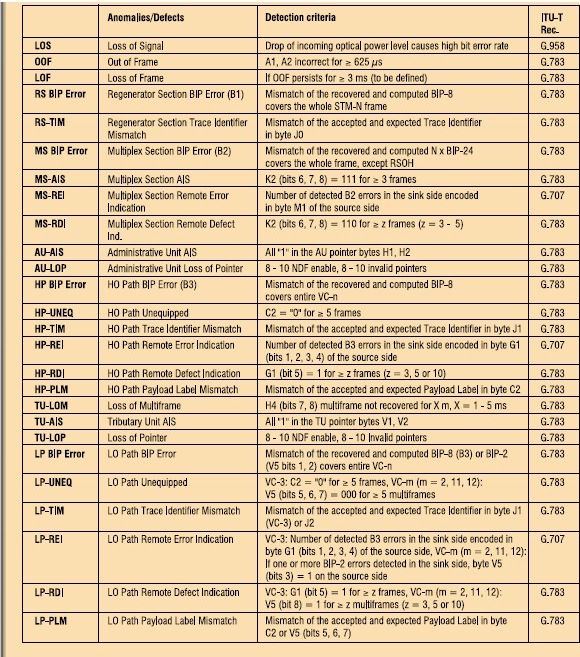
A fundamental issue in telecommunication is ascertaining whether a signal being transmitted is successfully received. Lack of continuity at the optical or electrical layers in SONET/SDH is indicated by the Loss of Signal (LOS) condition. This may arise from either the failure of a transmitter (e.g., laser, line card, etc.) or break in the line (e.g., fiber cut, WDM failure, etc.). The exact criteria for when the LOS condition is declared and when it is cleared are described in reference [ITU-T00b]. For optical SDH signals, a typical criterion is the detection of no transitions on the incoming signal (before unscrambling) for time T, where 2.3 µs ≤ T ≤ 100 µs. An LOS defect is cleared if there are signal transitions within 125 µs. When dealing with other layers, the loss of continuity is discovered using a maintenance signal known as the Alarm Indication Signal (AIS). AIS indicates that there is a failure further upstream in the lower layer signal. This is described further in section 3.6.2.1.
3.6.1.2 CONNECTIVITY SUPERVISION
Connectivity supervision deals with the determination of whether a SONET/SDH connection at a certain layer has been established between the intended pair of peers. This is particularly of interest if there has been an outage and some type of protection or restoration action has been taken. A trail trace identifier is used for connection supervision. Specifically,
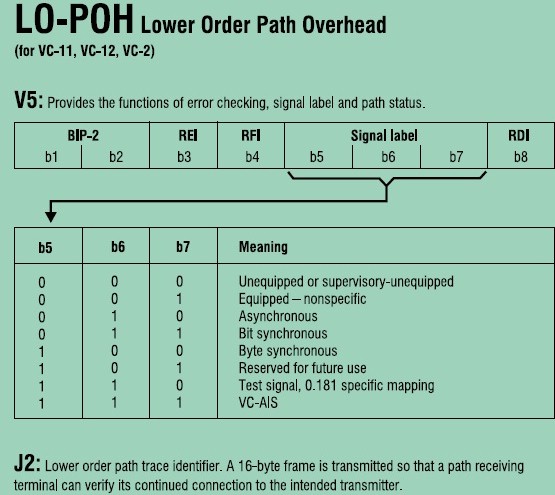
The J0 byte is used in the SONET section (SDH regenerator section) layer. The section trace string is 16 bytes long (carried in successive J0 bytes) as per recommendation G.707 [ITU-T00a].
The J1 byte is used in the SONET/SDH higher-order path layer (e.g., SONET STS-1 and above). The higher-order path trace string could be 16 or 64 bytes long as per recommendation G.707 [ITU-T00a].
The J2 byte is used in the SONET/SDH lower-order path layer (e.g., SONETVT signals). The lower-order path trace string is 16 bytes long as per recommendation G.707 [ITU-T00a].
For details of trail trace identifiers used for tandem connection monitoring (TCM), see recommendations G.707 [ITU-T00a] and G.806 [ITU-T00c]. The usage of this string is typically controlled from the management system. Specifically, a trace string is configured in the equipment at the originating end. An “expected string” is configured at the receiving end. The transmitter keeps sending the trace string in the appropriate overhead byte. If the receiver does not receive the expected string, it raises an alarm, and further troubleshooting is initiated.
3.6.1.3 SIGNAL QUALITY SUPERVISION
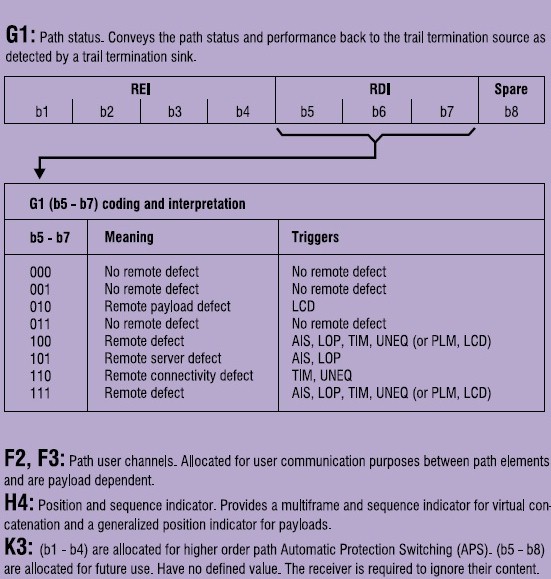
Signal quality supervision determines whether a received signal contains too many errors and whether the trend in errors is getting worse. In SONET and SDH, parity bits called Bit Interleaved Parity (BIP) are added to the signal in various layers. This allows the receiving end, known as the near-end, to obtain error statistics as described in section 3.6.3. To give a complete view of the quality of the signal in both directions of a bidirectional line, the number of detected errors at the far-end (transmitting end) may be sent back to the near-end via a Remote Error Indicator (REI) signal.
The following bits and bytes are used for near-end signal quality monitoring under SONET and SDH:
SONET section (SDH regenerator section) layer: The B1 byte is used to implement a BIP-8 error detecting code that covers the previous frame.
SONET line (SDH multiplex section) layer: In the case of SDHSTM-N signals, a BIPN × 24 composed of the 3 STM-1 B2 bytes is used. In the case of SONET STS-N, a BIP N × 8 composed of the N B2 bytes is used. These cover the entire contents of the frame excluding the regenerator section overhead.
SONET path (SDH HOVC) layer: The B3 byte is used to implement a BIP-8 code covering all the bits in the previous VC-3, VC-4, and VC-4-Xc.
SONET VT path (SDH LOVC) layer. Bits 1 and 2 of the V5 byte are used to implement a BIP-2 code covering all the bits in the previous VC-1/2.
SONET/SDH provides the following mechanisms for carrying the REI information. For precise usage, see either T1.105 [ANSI-95a] or G.707 [ITU-T00a].
Multiplex section layer REI: For STM-N (N = 0, 1, 4, 16), 1 byte (M1) is allocated for use as Multiplex Section REI. For STM-N (N = 64 and 256), 2 bytes (M0, M1) are allocated for use as a multiplex section REI. Note that this is in line with the most recent version of G.707 [ITU-T00a].
Path layer REI: For STS (VC-3/4) path status, the first 4 bits of the G1 path overhead are used to return the count of errors detected via the path BIP-8, B3. Bit 3 of V5 is the VT Path (VC-1/2) REI that is sent back to the originating VTPTE, if one or more errors were detected by the BIP-2.
3.6.1.4 ALIGNMENT MONITORING
When receiving a time division multiplexed (TDM) signal, whether it is electrical or optical, a critically important stage of processing is to find the start of the TDM frame and to maintain frame alignment. In addition, when signals are multiplexed together under SONET/SDH, the pointer mechanism needs to be monitored.
Frame Alignment and Loss of Frame (LOF)
The start of an STM-N (OC-3N) frame is found by searching for the A1 and A2 bytes contained in the STM-N (OC-3N) signal. Recall that the A1 and A2 bytes form a particular pattern and that the rest of the frame is scrambled. This framing pattern is continuously monitored against the assumed start of the frame. Generally, the receiver has 625 µs to detect an out-of-frame (OOF) condition. If the OOF state exits for 3 ms or more then a loss of frame (LOF) state will be declared. To exit the LOF state, the start of the frame must be found and remain valid for 3 ms.
Loss of Multiframe
SDH LOVCs and SONET VTs use the multi-frame structure described earlier. The 500 µs multiframe start phase is recovered by performing multiframe alignment on bits 7 and 8 of byte H4. Out-of-multiframe (OOM) is assumed once when an error is detected in the H4 bit 7 and 8 sequence. Multiframe alignment is considered recovered when an error-free H4 sequence is found in four consecutive VC-n (VT) frames.
Pointer Processing and Loss of Pointer (LOP)
Pointer processing in SONET/SDH is used in both the HOVC (STS path) and LOVC (VT path) layers. This processing is important in aligning payload signals (SDHVC or SONET paths) into their containing signals (STM-N/OC-3N). Without correct pointer processing, essentially one per payload signal, the payload signal is essentially “lost.” Hence, pointer values are closely monitored as part of pointer processing [ITU-T00a, ITU-T00b]. A loss of pointer state is declared under severe error conditions.
3.6.2 Problem Localization and Signal Maintenance
Once a problem has been detected, its exact location has to be identified for the purposes of debugging and repair. SONET/SDH provides sophisticated mechanisms to this in the form of Alarm Indication Signals (AIS) and the Remote Defect Indication (RDI). These are described below.
3.6.2.1 ALARM INDICATION SIGNALS
Suppose that there is a major problem with the signal received by an intermediate point in a SONET network. In this case, a special Alarm Indication Signal is transmitted in lieu of the normal signal to maintain transmission continuity. An AIS indicates to the receiving equipment that there is a transmission interruption located at, or upstream, of the equipment originating the AIS. Note that if the AIS is followed upstream starting from the receiver, it will lead to the location of the error. In other words, the AIS signal is an important aid in fault localization. It is also used to deliver news of defects or faults across layers.
A SONETSTE will originate an Alarm Indication Signal-Line (AIS-L) (MSAIS in SDH) upon detection of an LOS or LOF defect. There are two variants of the AIS-L signal. The simplest is a valid section overhead followed by “all ones” pattern in the rest of the frame bytes (before scrambling). To detect AIS-L, it is sufficient to look at bits 6, 7, and 8 of the K2 byte and check for the “111” pattern. A second function of the AIS-L is to provide a signal suitable for normal clock recovery at downstream STEs and LTEs. See [ANSI95a] for the details of the application, removal, and detection of AIS-L.
A SONETLTE will generate an Alarm Indication signal-Path (AIS-P) upon detection of an LOS, LOF, AIS-L, or LOP-P defect. AIS-P (AU AIS in SDH) is specified as “all ones” in the STS SPE as well as the H1, H2, and H3 bytes. STS pointer processors detect AIS-P as “111…” in bytes H1 and H2 in three consecutive frames.
A SONET STS PTE will generate an Alarm Indication signal-VT (AIS-V) for VTs of the affected STS path upon detection of an LOS, LOF, AIS-L, LOP-P, AIS-P, or LOP-V defect. The AIS-V signal is specified as “all ones” in the entire VT, including the V1-V4 bytes. VT pointer processors detect AIS-V as “111…” in bytes V1 and V2 in three consecutive VT superframes.
The SDHAIS signals for its various layers are nearly identical as those of SONET in definition and use as shown in Table 3-5.
3.6.2.2 REMOTE DEFECT INDICATION
Through the AIS mechanism, SONET allows the downstream entities to be informed about problems upstream in a timely fashion (in the order of milliseconds). The AIS signal is good for triggering downstream protection or restoration actions. For quick recovery from faults, it is also important to let the upstream node know that there is a reception problem downstream. The Remote Defect Indication (RDI) signal is used for this purpose. The precise definition of RDI, as per [ANSI95a], is
Table 3-5. SDH AIS Signals by Layer
Layer
Type
AIS Overhead
AIS Activation Pattern
AIS Deactivation Pattern
MSn
MS–AIS
K2, bits 6 to 8
“111”
≠ “111”
VC-3/4
AU-AIS
H1, H2
See Annex A/G.783 [ITU-T00b]
VC-3/4 TCM
IncAIS
N1, bits 1 to 4
“1110”
≠ “1110”
VC-11/12/2
TU–AIS
V1, V2
S11/12/2 (VC-11/12/2)
VC-11/12/2
TU–AIS
V1, V2
See Annex A/G.783 [ITU-T00b]
VC-11/12/2 TCM
IncAIS
N2, bit 4
“1”
“0”
A signal transmitted at the first opportunity in the outgoing direction when a terminal detects specific defects in the incoming signal.
At the line level, the RDI-L code is returned to the transmitting LTE when the receiving LTE has detected an incoming line defect. RDI-L is generated within 100 ms by an LTE upon detection of an LOS, LOF, or AIS-L defect. RDI-L is indicated by a 110 code in bits 6,7,8 of the K2 byte (after unscrambling).
At the STS path level, the RDI-P code is returned to the transmitting PTE when the receiving PTE has detected an incoming STS path defect. There are three classes of defects that trigger RDI-P:
Payload defects: These generally indicate problems detected in adapting the payload being extracted from the STS path layer.
Server defects: These indicate problems in one of the layers responsible for transporting the STS path.
Connectivity defects: This only includes the trace identifier mismatch (TIM) or unequipped conditions.
Table 3-6 shows current use of the G1 byte for RDI-P purposes (consult [ANSI95a] for details).
The remote defect indication for the VT path layer, RDI-V, is similar to RDI-P. It is used to return an indication to the transmitting VTPTE that the receiving VTPTE has detected an incoming VT Path defect. There are three classes of defects that trigger RDI-V:
Table 3-6. Remote Defect Indicator—Path (RDI-P) via the G1 Byte
G1, bit 5
G1, bit 6
G1, bit 7
Meaning
0
1
0
Remote payload defect
0
1
1
No remote defect
1
0
1
Server defect
1
1
0
Remote connectivity defect
Payload defects: These generally indicate problems detected in adapting the payload being extracted from the VT path layer.
Server defects: These generally indicate problems in the server layers to the VT path layer.
Connectivity defects: These generally indicate that there is a connectivity problem within the VT path layer.
For more information, see [ANSI95a] for details. RDI-V uses the Z7 bytes (bits 6 and 7).
One thing to note about RDI signals is that they are “peer to peer” indications, that is, they stay within the layer that they are generated. The AIS and RDI signals form the “fast” notification mechanisms for protection and restoration, that is, these are the primary triggers. Examples of their usage are given in the next chapter. The RDI signals in various SDH layers are nearly identical to those of SONET and they are summarized in Table 3-7.
Table 3-7. RDI Signals for Various SDH Layers
Layer
Type
RDI/ODI Overhead
RDI/ODI Activation Pattern
RDI/ODI Deactivation Pattern
MSn
RDI
K2, bits 6 to 8
“110”
≠ “110”
S3D/4D (VC-3/4 TCM option 2)
RDI
N1, bit 8, frame 73
“1”
“0”
S11/12/2 (VC-11/12/2)
RDI
V5, bit 8
“1”
“0”
S11D/12D/2D (VC-11/12/2 TCM)
RDI
N2, bit 8, frame 73
“1”
“0”
3.6.3 Quality Monitoring
3.6.3.1 BLIPS AND BIPS
The bit error rates are typically extremely low in optical networks. For example, in 1995, the assumed worst-case bit error rate (BER) for SONET regenerator section engineering was 10-10, or one error per 10 billion bits. Today, that would be considered quite high. Hence, for error detection in a SONET frame, we can assume very few bit errors per frame.
As an example, the number of bits in an STS-192 frame is 1,244,160 (9 rows × 90 columns per STS-1 x 8 bits/byte × 192 STS-1). With a BER of 10-10, it can be expected that there will be one bit error in every 8038 frames. The probability of two errors in the same frame is fairly low. Since the bit rate of an STS-192 signal is 10 Gbps (or 1010 bits per second), a BER of 10-10 gives rise to one bit error every second on the average. This is why a BER of 10-10 is considered quite high today.
Figure 3-10 shows the general technique used in SONET and SDH for monitoring bit errors “in-service” over various portions of the signal. This method is known as the Bit Interleaved Parity 8 Bits, or BIP-8 for short. Although the name sounds complex, the idea and calculation are rather simple. In Figure 3-10, X1-X5 represents a set of bytes that are being checked for transmission errors. For every bit position in these bytes, a separate running tally of the parity (i.e., the number of 1s that occur) is kept track of. The corresponding bit position of the BIP-8 byte is set to “1” if the parity is currently odd and a zero if the parity is even. The BIP-8 byte is sent, typically in the following frame, to the destination. The destination recomputes the BIP-8 code based on the contents of the received frame and compares it with the BIP-8 received. If there are no bit errors, then these two codes should match. Figure 3-10(b) depicts the case where one of the bytes, X2, encounters a single bit error during transmission, that is, bit 2 changes from 1 to 0. In this case, the received BIP-8 and the recomputed BIP-8 differ by a single bit and, in fact, the number of differing bits can be used as an estimate of the number of bit errors.
Figure 3-10. Example of BIP-8 Calculation and Error Detection
Note that the BIP-8 technique works well under the assumption of low bit error rates. The study of general mechanisms for error detection and correction using redundant information bits is known as algebraic coding theory (see [Lin+83]).
BIP-8 is used for error monitoring in different SONET/SDH layers. At the SONET section layer, the B1 byte contains the BIP-8 calculated over all the bits of the previous STS-N frame (after scrambling). The computed BIP-8 is placed in the B1 byte of the first STS-1 (before scrambling). This byte is defined only for the first STS-1 of an STS-N signal. SDH uses this byte for the same purpose. Hence, the BIP-8 in this case is calculated over the entire SONET frame and covers a different number of bytes for different signals, for example, STS-12 vs. STS-192.
At the SONET line layer, BIP-8 is calculated over all the bits of the line overhead and the STS-1 SPE (before scrambling). The computed BIP-8 is placed in the B2 byte of the next STS-1 frame (before scrambling). This byte is separately computed for all the STS-1 signals within an STS-N signal. These NBIP-8 bytes are capable of detecting fairly high bit error rates, up to 10-3. To see this, consider an STS-1 line signal (i.e., an STS-1 frame without section layer overhead). The number of bytes in this signal is 804 (9 rows × 90 columns – 6 section bytes). Each bit in the line BIP-8 code is used to cover 804 bits (which are in the corresponding bit position of the 804 bytes in the line signal). Since a BER of 10-3 means an average of one bit error every 1000 bits, there will be less than one bit error in 804 bits (on the average). This, the line BIP-8 code is sufficient for detecting these errors. Note, however, that BIP-8 (and any parity based error detection mechanism) may fail if there are multiple, simultaneous bit errors.
At the STS Path level, BIP-8 is calculated over all the bits of the previous STS SPE (before scrambling) and carried in the B3 path overhead byte. SDH uses this byte for the same purpose but excludes the fixed stuff bytes in the calculation. The path BIP-8, like the section BIP-8, covers a different number of bytes depending on the size of the STS path signal, that is, STS-3 vs. STS-12.
At the VT path level, 2 bits of the VT path level overhead byte V5 are used for carrying a BIP-2. The technique for this is illustrated in Figure 3-11. To save on overhead, the parity counts over all the odd and the even bit positions are combined and represented by the two bits of the BIP-2 code, respectively. Recall that the VTSPE is a multiframe spanning four SONET frames. The BIP-2 is calculated over all bytes in the previous VTSPE, including all overhead but the pointers (Figure 3-11).
Figure 3-11. BIP Calculation at the VT Path Level
Let us examine how effective the BIP-2 code is. The number of bits in the VT1.5 SPE is 832 ([(9 rows × 3 columns) – 1 pointer byte] × 8 bits/byte × 4 frames per SPE). Each bit of the BIP-2 code covers half the bits in the VT1.5 SPE, that is, 416 bits. Hence, BIP-2 can handle error rates of 1 in 500 bits (BER between 10-2 and 10-3). Now, a VT6 is four times the size of the VT1.5. In this case, each parity bit covers 1664 bits, handling a BER slightly worse than 10-4.
3.6.4 Remote Error Monitoring
The error monitoring capabilities provided by SONET and SDH enables the receiver to know the error count and compute the BER on the received signal at various layers. Based on this information, it is useful to let the sender learn about the quality of the signal received at the other end. The following mechanisms are used for this purpose.
The STS-1 line REI (M0 byte) is used by the receiver to return the number of errored bits detected at the line layer to the sender. The receiver arrives at this number by considering the difference between the received and the recomputed BIP-8 (B2) codes. In the case of an STS-N signal, the M1 byte is used for conveying the REI information. Clearly, up to 8 × N errors could be detected with STS-NBIP-8 codes (as each STS-1 is covered by its own BIP-8). But only a count of at most 255 can be reported in the single M1 byte. Thus, in signals of OC-48 and higher rates, the number 255 is returned when 255 or more errors are detected.
At the path layer, the receiver uses the first four bits of the G1 path overhead to return the number of errors detected (using the path BIP-8) to the sender. At the VT path layer, the receiver uses bit 3 of the V5 byte to indicate the detection of one or more errors to the sender.
3.6.5 Performance Measures
When receiving word of a problem, one is inclined to ask some general questions such as: “How bad is it? “How long has it been this way?” and “Is it getting worse or better?” The following terminology is used in the transport world. An anomaly is a condition that gives the first hint of possible trouble. A defect is an affirmation that something has indeed gone wrong. A failure is a state where something has truly gone wrong. Whether an event notification or an alarm is sent to a management system under these conditions is a separate matter. Performance parameters in SONET and SDH are used to quantify these conditions.
A SONET or an SDH network element supports performance monitoring (PM) according to the layer of functionality it provides. A SONET network element accumulates PM data based on overhead bits at the Section, Line, STS Path, and VT Path layers. In addition, PM data are available at the SONET Physical layer using physical parameters. The following is a summary of different performance parameter defined in SONET. Similar performance parameters are also monitored and measured in SDH. For a detailed treatment on PM parameters on SONET refer to [Telcordia00].
Physical Layer Performance Parameters
The physical layer performance measurement enables proactive monitoring of the physical devices to facilitate early indication of a problem before a failure occurs. Several physical parameters are measured, including laser bias current, optical power output by the transmitter, and optical power at the receiver. Another important physical layer parameter is the Loss of Signal (LOS) second, which is the count of 1-second intervals containing one or more LOS defects.
Section Layer Performance Parameters
The following section layer performance parameters are defined in SONET. Note that all section layer performance parameters are defined for the near-end. There are no far-end parameters at the Section layer.
Code Violation(CV-S): The CV-S parameter is a count of BIP errors detected at the section layer. Up to eight section BIP errors can be detected per STS-N frame.
Errored Second(ES-S): The ES-S parameter is a count of the number of 1 second intervals during which at least one section layer BIP error was detected, or an SEF (see below) or LOS defect was present.
Errored Second Type A(ESA-S) andType B(ESB-S): ESA-S is the count of 1-second intervals containing one CV-S, and no SEF or LOS defects. ESB-S is the count of 1-second intervals containing more than one but less than X CV-S errors, and no SEF or LOS defects. Here, X is a user-defined number.
Severely Errored Second(SES-S): The SES-S parameter is a count of 1-second intervals during which K or more Section layer BIP errors were detected, or an SEF or LOS defect was present. K depends on the line rate and can be set by the user.
Severely Errored Frame Second(SEFS-S): The SEFS-S parameter is a count of 1-second intervals during which an SEF defect was present. An SEF defect is detected when the incoming signal has a minimum of four consecutive errored frame patterns. An SEF defect is expected to be present when an LOS or LOF defect is present. But there may be situations when this is not the case, and the SEFS-S parameter is only incremented based on the presence of the SEF defect.
Line Layer Performance Parameters
At the SONET line layer, both near-end and far-end parameters are monitored and measured. Far-end line layer performance is conveyed back to the near-end LTE via the K2 byte (RDI-L) and the M0 or M1 byte (REI-L). Some of the important near-end performance parameters are defined below. The far-end parameters are defined in a similar fashion.
Code Violation(CV-L): The CV-L parameter is a count of BIP errors detected at the line layer. Up to 8NBIP errors can be detected per STS-N frame.
Errored Second(ES-L): The ES-L parameter is a count of 1-second intervals during which at least one line layer BIP error was detected or an AIS-L defect is present.
Errored Second Type A(ESA-L) andType B(ESB-L): ESA-L is the count of 1-second intervals containing one CV-L error and no AIS-L defects. ESB-L is the count of 1-second intervals containing X or more CV-L errors, or one or more AIS-L defects. Here, X is a user-defined number.
Severely Errored Second(SES-L): The SES-L parameter is a count of 1-second intervals during which K or more line layer BIP errors were detected, or an AIS-L defect is present. K depends on the line rate and can be set by the user.
Unavailable Second(UAS-L): Count of 1-second intervals during which the SONET line is unavailable. The line is considered unavailable after the occurrence of 10 SES-Ls.
AIS Second(AISS-L): Count of 1-second intervals containing one or more AIS-L defects.
Path Layer Performance Parameters
Both STS path and VT path performance parameters are monitored at the path layer. Also, both near-end and far-end performance parameters are measured. Far-end STS path layer performance is conveyed back to the near-end STS PTE using bits 1 through 4 (REI-P) and 5 through 7 (RDI-P) of the G1 byte. Far-end VT path layer performance is conveyed back to the near-end VTPTE using bit 3 of the V5 byte (REI-V), and either bits 5 through 7 of the Z7 byte or bit 8 of the V5 byte (RDI-V). Some of the important near-end STS path performance parameters are defined below. The far-end parameters are defined in a similar fashion.
Code Violation(CV-P): Count of BIP-8 errors that are detected at the STS-path layer.
Errored Second(ES-P): Count of 1-second intervals containing one or more CV-P errors, one or more AIS-P, LOP-P, TIM-P, or UNEQ-P defects.
Errored Second Type A(ESA-P) andType B(ESB-P): ESA-P is the count of 1-second intervals containing one CV-P error and no AIS-P, LOP-P, TIM-P, or UNEQ-P defects. ESB-P is the count of 1-second intervals containing more than one but less than X CV-P errors and no AIS-P, LOP-P, TIM-P, or UNEQ-P defects. Here, X is a user-defined number.
Severely Errored Second(SES-P): Count of 1-second intervals containing X or more CV-P errors, one or more AIS-P, LOP-P, TIM-P, or UNEQ-P defects. Here, X is a user-defined number.
Unavailable Second(UAS-P): Count of 1-second intervals during which the SONET STS-path is unavailable. A path is considered unavailable after the occurrence of 10 SESs.
Pointer Justification Counts: To monitor the adaptation of the path payloads into the SONET line, the pointer positive and negative adjustment events are counted. The number of 1-second intervals during which a pointer adjustment event occurs is also kept track of.
3.7 Summary
SONET and SDH-based optical transport networks have been deployed extensively. It is therefore important to understand the fundamentals of these technologies before delving into the details of the control plane mechanisms. After all, the optical network control plane is a relatively recent development. Its primary application in the near term will be in SONET/SDH networks. In this context, it is vital to know about the low-level control mechanisms that already exist in SONET and SDH and how they help in building advanced control plane capabilities. The next chapter continues with a description of another key topic relevant to the control plane, that is, protection and restoration mechanisms in SONET and SDH networks. Following this, the subject of modern optical control plane is dealt with in earnest.
Virtual Concatenation: Knowing the Details .
They say the devil is in the details. That’s certainly the case when dealing with virtual concatenation. Clearly, designers at the chip, equipment, and carrier level have touted the wonders that virtual concatenation delivers. But, what often gets lost in these discussions are the real challenges that chip and equipment developers will face when implementing virtual concatenation in a real-world design.
In this two-part series, we’ll examine the design issues that developers will encounter when implementing virtual concatenation in a system level design. In Part 1, we’ll examine the basic benefits of virtual concatenation, the difference between high- and low-order virtual concatenation pipes, and differential delay issues. In Part 2, we’ll take a detailed look at the link capacity adjustment scheme (LCAS).
Why VC is So hot
Much has already been said and written about the benefits of virtual concatenation over current payload mapping capabilities of Sonet and SDH. Table 1 summarizes the individual payload capacities of different commonly used Sonet or SDH paths. The table includes both high- and low-order paths with and without standard contiguous concatenation (denoted by the “c”).
While allowing a range of bandwidths to be provisioned, these current mappings do not have the granularity required to make efficient use of the existing network infrastructure. One other important point to note is that contiguous concatenation of VT1.5/VC-11s or VT2/VC-12s is not supported.
Table 1: Current Sonet and SDH Payload Capacities
Container (Sonet/SDH)
Type
Payload Capacity (Mbit/s)
VT1.5/VC 11
Low Order
1.600
VT2/VC 12
Low Order
2.176
STS-1/VC 3
High Order
48.384
STS-3c/VC 4
High Order
149.76
STS-12c/VC 4-4c
High Order
599.04
STS-24c/VC 4-8c
High Order
1198.08
STS-48c/VC 4-16c
High Order
2396.16
STS-192c/VC 4-64c
High Order
9584.64
Table 2 lists the payload capacities possible with virtual concatenation. As is shown, concatenation of VT1.5/VC-11s or VT2/VC-12s is supported and the concatenation of high-order paths is much more granular.
Table 2: Virtual Concatenation Payload Capacities
Container (Sonet/SDH)
Type
Payload Capacity (Mbit/s)
VT1.5 Xv/VC 11 Xv
Low Order
X x 1.600 (X=1.64)
VT2 Xv/VC 12 Xv
Low Order
X x 2.176 (X = 1.64)
STS-1-Xv/VC 3-Xv
High Order
X x 48.384 (X = 1.256)
STS-3-Xv/VC 4-Xv
High Order
X x 149.76 (X = 1.256)
Making Use of Unused Overhead
In addition to allowing more flexible mapping, virtual concatenation also releases two of the restrictions upon which contiguous concatenation relies to reconstruct the signal being carried. These are phase alignment of the members of the concatenation and an inherent sequence order of the members. Consequently, in order to reconstruct the original signal from a virtually concatenated group (VCG), it is necessary to determine the phase alignment and sequence of the received members. The information required to support this is carried in previously unused Sonet/SDH path overhead, which is overhead that is generated by a payload mapper and effectively stays intact regardless of how the payload makes its way through the network to its destination. Note: In SDH, tandem connection monitoring involves the modification of some Path Overhead at an intermediate point.
To put this in context, Figure 1 illustrates the high- and low-order paths and their path overhead. For high-order paths, virtual concatenation uses the H4 byte while for low-order paths, virtual concatenation uses bit 2 of the Z7/K4 byte.
Figure 1: High- and low-order paths and overhead.
For both high- and low-order paths, the information required is structured in a multi frame format as shown in Figure 2. For high-order paths, the multi frame structure is defined by the virtual concatenation overhead carried in the H4 byte. For the low-order paths, on the other hand, the multi frame structure is phase aligned with the multi frame alignment signal (MFAS) of bit 1 of the Z7/K4 byte that carries the extended signal label.
Figure 2: Virtual concatenation multi frame formats.
High-Order Overhead
In high-order paths, the H4 multi frame structure is 16 frames long for a total of 2 ms. Within this structure, there are two multi frame indicators—MFI1 and MFI2. MFI1 is a 4-bit field which increments every frame while MFI2 is an 8-bit field which increments every multi frame.
The most significant and least significant nibbles of MFI2 are sent over the first two frames of a multi frame. Together with MFI1, they form a 12-bit field that rolls over every 512 ms (4096 x 125 μs). This allows for a maximum differential path delay of less than 256 ms to ensure that it is always possible to determine which members of a VCG arrive earliest (shortest network delay) and which members arrive latest (longest network delay).
If the differential delay were 256 ms or more, it would not be possible to know if a member with an {MFI2,MFI1}=0 is 256 ms behind or 256 ms ahead of a member with an {MFI2,MFI1}=2048.
The second piece of information conveyed in the H4 byte is the sequence indicator (SQ). This is an 8-bit field that, like the MFI2, is sent a nibble at a time over two frames in the multi frame. In this case if SQ, it is sent over the last two frames. Consequently, a high-order VCG can contain up to 256 members.
The number of members is obviously limited by the number of paths available in the transport signal. Thus, a 40-Gbit pipe would have to be a reality to have 256 STS 1 or VC 3 members. Referring back to the payload capacities of Table 1, for STS 1 256v/VC 3 256vs, the payload capacity is 256 x 48.384 Mbit/s = 12,386.304 Mbit/s. For STS 3c 256v/VC 4 256v, the payload capacity would be close to 50 Gbit/s.
Low-Order Overhead
Figure 1 above shows that low-order paths have an inherent multi frame structure of 4 Sonet/SDH frames (or 500 μs). As illustrated in Figure 2, the virtual concatenation multi frame structure, delineated by the MFAS pattern in the extended signal label bit (bit 1 of K4), is 32 of these 500 μs multi frames for a total VC multi frame (or should we say multi multi frame) duration of 16 ms.
Within the virtual concatenation multi-frame structure of bit 2 of the K4 byte, again, there is a multi frame indicator (MFI) and an SQ. In this case, the MFI is a 5-bit field sent over the first five 500 μs multi frames of the VC multi frame that rolls over every 512 ms (32 x 16ms). Again, this permits a maximum differential delay across all members of a low-order VCG of less than 256 ms.
The SQ for LO paths is a 6-bit field which is transmitted over virtual concatenation multi frames 6 through 11 allowing for up to 64 members on a low-order VCG. Again, using the values in Table 2, for VT1.5 64v/VC 11 64v, the payload capacity is 102.4 Mbit/s and the payload capacity of a VT2 64v/VC 12 64v is 139.264 Mbit/s.
Differential Delay alignment
When data is mapped into a VCG, it is essentially ‘demultiplexed’, on a byte by byte basis, across the members of the VCG in the sequence provisioned (reflected by the SQ bytes of each member). At the destination, these discrete paths must be ‘remultiplexed’ to form the original signal. Allowance for differential delay across the members of a VCG implies that all members must be delayed to that of the maximum member such that the ‘remultiplexing’ can be performed correctly.
As a concept, differential delay alignment is not particularly complex. Each member has its data written into a buffer upon reception along with some kind of indication as to where the MFI boundaries are. Data for a given MFI is then read out of each buffer, thus creating phase alignment of the members. The depth of each buffer (the difference between the read and write pointers) is a measure of the difference in delay between that member and the member that has the most network delay.
The main issue with differential delay is the amount of buffer space required. Designers can calculate the amount of buffer space required using the maximum number of members supported. For example, each VT1.5/VC 11 has a payload capacity of 1.6Mbit/s. The worst case is that a member would have to be delayed by just under 256 ms which represents 1.6 Mbit/s x 0.256 s = 400 kbit. Similarly, an STS 1/VC 3 requires a maximum payload capacity of 1.48 Mbit.
These numbers may not seem significant until one considers the number of paths in a given transport signal. Table 3 shows the memory requirements for some potential combinations of virtual concatenation path types and the transport signals that may carry them. Note: the calculations in Table 3 reflect maximum buffer sizes on all paths assuming only payload data is buffered. At least one member of each VCG, by definition, will have minimal buffering so the actual requirements will be slightly lower. If any Path Overhead is also buffered, then the requirements may rise.
Table 3: Virtual Concatenation Delay Buffer Requirements for Various Transport Signals
Virtual Concatenation Path Type
Transport Signal
Number of Paths
total Delay Buffer Size
VT1.5/VC 11
STS-3/STM-1
84
33 Mbit
VT1.5/VC 11
STS-12/STM-4
336
131 Mbit
VT2/VC 12
STS-3/STM-1
63
33.5 Mbit
VT2/VC 12
STS-3/STM-4
252
134 Mbit
STS-1/VC-3
STS-12/STM-4
12
142 Mbit
STS-1/VC-3
STS-48/STM-16
48
567 Mbit
STS-3c/VC-4
STS-12/STM-4
4
146 Mbit
STS-3c/VC-4
STS-48/STM-16
12
585 Mbit
It is clear from Table 3 that, even for low bandwidth mapping/demapping devices (STS-3/STM-1) that support virtual concatenation, it is impractical to provide on-board buffers allowing for 256 ms of differential delay.
The obvious way to solve this problem is to equip mapping/demapping devices with interfaces to external memory that is large enough to hold the amounts of data listed above. Again this sounds straightforward but there is another consideration that complicates the solution. The data transfer rate between the mapper/demapper and the external buffer memory is twice that of the transport signal rate. This is because the data must be both written to and read from the buffers at the transport signal rate. For an OC 48/STM 16 this amounts to close to 5 Gbit/s. Even with 32-bit wide memory, this results in approximately 150 Mtransfers/s.
The memory options that support these rates are not plentiful. Essentially, these devices must support external SDRAM or SRAM. SDRAM may seem like a good solution due to the large capacities available and the apparent speed that DDR and QDR SDRAMs can support. These speeds can only be achieved, however, if access to the memory involves sustained bursts to sequential memory blocks where successive blocks sit in different pages within the SDRAM structure. This can’t easily be guaranteed, as the allocation of memory is entirely dependent on the type, number and delay supported of the members all VCGs being terminated by the device.
SRAMs, on the other hand, can easily keep up with the transfer rates required with no restriction on the order that data is either written or read but capacities of 500 Mbit can be prohibitive in cost and real estate. Consequently, component vendors must choose carefully how much differential delay and what type of external memory their mapper/demapper devices will support.
Virtual Concatenation: Knowing the Details continues
The hype behind virtual concatenation has been growing for more than a year now. And the link capacity adjustment scheme is one of the reasons why. LCAS enhances the capabilities provided by virtual concatenation, allowing operators to adjust virtually concatenated groups (VCGs) on the fly, thus improving network utilization even further.
But, like virtual concatenation, LCAS implementation can be quite challenging for today’s chip and equipment designers. In Part 1, we looked at virtual concatenation and the implementation issues designers will face using this technology. Now, in Part 2, we’ll focus our attention on describing how LCAS works and the design issues engineers will face when using this technology in a chip or system design.
Understanding LCAS
The link capacity adjustment scheme (LCAS) mainly attempts to address two of the tricky issues associated with virtual concatenation: ability to increase or decrease the capacity of a VCG and the ability to deal gracefully with member failures.
With LCAS, not all members of a VCG need to be active in order to pass data from the source (So), to the Sink (Sk). Once a VCG is defined, the So and Sk equipment are responsible for agreeing which members will carry traffic. There are also procedures that allow them to agree to remove or add members at any time. To achieve this, signaling between the source and sink is required and some of the reserved fields in the virtual concatenation overhead are used for this purpose.
Within LCAS, a control packet is defined that carries the following fields:
Member status (MST)
Re-sequence acknowledge (RS-Ack)
Control (CTRL)
Group ID (GID)
CRC-3/CRC-8 (3 for LO, 8 for HO)
The position of these fields within the VC multi-frames for high- and low-order paths are shown in Figure 3. Note that, for high-order paths, the control packet begins with the MST field in MFI n and ends with the CRC-8 field in MFI n+1.
Figure 3: Signaling overhead associated with LCAS.
The MST field provides a means of communicating, from the Sk to the So, the state of all received VCG members. The state for each member is either OK or FAIL (1 bit). Since there are potentially more members than bits in the field in a given VC multi-frame, it takes 32 high-order virtual concatenation multi-frames and 8 low-order virtual-concatenation multi-frames to signal the status of all members. This signaling allows the Sk to indicate to the So that a given member has failed and may need be removed from the list of active members of the VCG.
The RS-Ack field is a bit that is toggled by the Sk to indicate to the So that changes in the sequence numbers for that VCG have been evaluated. It also signals to the So that the MST information in the previous multi-frame is valid. With this signaling, the So can be informed that the changes it has requested (either member addition or removal) have been accepted by the Sk.
The MST and RS-Ack fields are identical in all members of the VCG upon transmission from the Sk.
The Control Field
The control field allows the So to send information to the Sk describing the state of the link during the next control packet. Using this field, the So can signal that the particular path should be added (ADD) to the active members, be deleted (or remain deleted) from the active members (IDLE) or should not be used due to a failure detected at the Sk (DNU). It can also indicate that the particular path is an active member (NORM) or the active member with the highest SQ (EOS). Finally, for compatibility with non-LCAS VCAT the CTRL field can indicate that fixed bandwidth is used (FIXED).
The Group ID field provides a means for the receiver to determine that all members of a received VCG come from the same transmitter. The field contains a portion of a pseudo-random bit sequence (215–1). This value is the same for all members of a VCG at any given MFI.
Finally, the CRC field provides a means to validate the control packet received before acting on it. In this way, the signaling link is tolerant of bit errors.
Basic LCAS Operation
When a VCG is initiated, all MSTs generated by the Sk are set to FAIL. It is then the responsibility of the So to add members to the VCG to establish data continuity. The So can set the initial SQ numbers of multiple members and set their CTRL fields to ADD. The Sk will then set all the corresponding MSTs to OK.
The first MST recognized by the So has its SQ renumbered to the lowest value and this re-sequence will be transmitted to the Sk. Multiple members can be recognized at the same time by the So and the re-sequence may involve more than one member.
The Sk acknowledges the re-sequence by toggling the RS-Ack in all members. After the RS-Ack is received by the So, it will set CTRL field for the corresponding members to NORM with highest SQ member being set to EOS. This process continues until all members have been added to the active group. At this point, the CTRL field for all but one added members will be NORM. The member with the highest SQ will have its CTRL field set to EOS.
Adding, Deleting Members
When members are to be added or deleted, the sequence is similar. The CTRL field for the member or members in question will be set by the So to either ADD or IDLE depending on the operation requested. The Sk will then respond with MST values of either OK or FAIL respectively. Again, the order that the updated MST values are seen and confirmed by the So will determine how the SQ values are updated.
In the event of a network failure resulting in a member failure, the Sk will set the corresponding MST (or MSTs) to FAIL. The So, upon seeing and confirming the status of this member (or members), will set the CTRL field for that member (or those members) to DNU.
If the last member has an MST of FAIL, then the next previous member that remains active will have its CTRL field changed from NORM to EOS. In the event that the failure is repaired, the MST (or MSTs) will be updated by the Sk to OK. At this point, the So can update the CTRL value (or values) to NORM to indicate that the member (or members) will again carry traffic at the next boundary.
In all cases, bandwidth changes take place on the high-order frame or low-order multi-frame following the reception of the CRC of the control packet where the CTRL fields change to or from NORM. Specifically, this is synchronized with the first payload byte after the J1 or J2 following the end of the control packet. This byte will be the first one either filled with data in the case of an added member or the first one left empty in the case of a deleted member.
LCAS Design Considerations
One of the most attractive features of LCAS is the fact that it provides a mechanism to map around VCG member failures by allowing them to be temporarily removed from a VCG without user intervention. Typically, however, paths will be protected in some fashion whether it is 1:N span protections or, more likely unidirectional path switched/subnetwork connection protection (UPSR/SNCP)-type protection within the network. If this is the case, then, on a network failure, it would easily be possible for an Sk to lose a member and signal that condition via the MST field and then regain that member after the So has already initiated temporary removal from the group. Without the ability to allow existing network APS schemes to settle before acting at the LCAS level, this kind of scenario can lead to a considerable amount of thrashing in the reestablishment of data continuity for the VCG after a network failure.
Similarly, while the flexibility of SQ assignment can allow for graceful inclusion or exclusion of VCG members, it can also create significant complication in managing the members. When an So chooses to add multiple members, it must arbitrarily set the SQ values for each member that it wishes to add to something greater than the maximum existing SQ value.
Once an MST=OK is received for any of those members, the So then sets that member’s SQ value to one greater than the highest active member. This means that the all the ‘new’ SQ values of the other members waiting to be added may need to be rearranged.
The RS-Ack is defined specifically so that the Sk can evaluate the new SQ information and acknowledge it before data is placed on the new member, but any table driven alignment scheme based on received SQ values must be tolerant of these changes. Also, software must be able to manage the changes in correlation between Sonet/SDH paths and their SQ values over time.
Additionally, when members are deleted from a VCG, their new SQ values can be any value greater than the highest active member. There is no restriction that these values be unique so many inactive members can share the same SQ. Again, context-switched state machines that run through the SQ values ensuring that all members are processed properly must handle this condition.
Other potential problems can arise from how unused members are handled. If unused paths are received with AIS or unequipped, then the path overhead will contain no virtual concatenation signaling of any kind. There is then no way to determine any kind of virtual concatenation multi-frame alignment of these members. So it must be possible to achieve alignment on the working members of a VCG regardless of the state of all other members.
Moving Processing to Software
As seen above, complications can arise in how different information is interpreted when using LCAS. Due to this complexity and the signaling durations involved (e.g. 64 or 128 ms required to update all MST), it is attractive to move some of the processing to software where more variables can, more easily, be considered. In fact some functions, such as waiting for APS to settle, can be better handled in software.
Care must be taken in establishing the hardware/software partition, however. For example, if a system needs to support hitless addition or deletion of members, the time between the reception of a control packet and when the data multiplexing configuration changes is just 55.6 μs for high-order paths and 250 μs for low-order paths. Software will typically not be able to reconfigure the data multiplexing quickly enough once it has determined what changes are about to occur. It is possible, depending on how many VCGs have changes going on at the same time, that software implementation will not even sort out the changes before they happen.
Wrap Up
Access equipment that supports both high- and low-order mapping allows the service provider to tailor the connectivity granularity and cost based on the requirements of the customers at each installation while only needing to worry about a limited product inventory. With virtual concatenation, the service provider can efficiently provide this appropriate level of connectivity without having to resort to statistical multiplexing techniques that complicate service level agreements (SLAs). With LCAS, bandwidth flexibility and fault tolerance are added.
Designing the systems and components to support virtual-concatenation-enabled Sonet and SDH infrastructures is not trivial, however. Designers have to draw on their experience with legacy equipment and the problems found in the network today to ensure a robust implementation of tomorrow’s network.
Sometime we require something that help us to understand SDH in quick mode.For this I have collected some snapshots that will help you crack your interviews as well as make you loaded with the know hows of the same..
1.SDH frame:-
2.Mapping structure:-
3.Overheads:-
4.Path Overheads:-
5.Concatenation:-
6.Alarms:-
7.Alarm Flow:-
Your concerns and queries will be highly appreciated……….
Fiber Optic Communication System Design Considerations
When designing a fiber optic communication system some of the following factors must be taken into consideration:
Which modulation and multiplexing technique is best suited for the particular application?
Is enough power available at the receiver (power budget)?
Rise-time and bandwidth characteristics
Noise effects on system bandwidth, data rate, and bit error rate
Are erbium-doped fiber amplifiers required?
What type of fiber is best suited for the application?
Cost
Power Budget
The power arriving at the detector must be sufficient to allow clean detection with few errors. Clearly, the signal at the receiver must be larger than the noise. The power at the detector, Pr, must be above the threshold level or receiver sensitivity Ps.
Pr >= Ps
The receiver sensitivity Ps is the signal power, in dBm, at the receiver that results in a particular bit error rate (BER). Typically the BER is chosen to be one error in 109 bits or 10–9.
The received power at the detector is a function of:
Power emanating from the light source (laser diode or LED)—(PL)
Source to fiber loss (Lsf)
Fiber loss per km (FL) for a length of fiber (L)
Connector or splice losses (Lconn)
Fiber to detector loss (Lfd)
The allocation of power loss among system components is the power budget. The power margin is the difference between the received power Pr and the receiver sensitivity Ps by some margin Lm.
Lm = Pr – Ps
where Lm is the loss margin in dB, Pr is the received power, Ps is the receiver sensitivity in dBm.
If all of the loss mechanisms in the system are taken into consideration, the loss margin can be expressed as the following equation. All units are dB and dBm.
Lm = PL – Lsf – (FL × L) – Lconn – Lfd – Ps
Bandwidth and Riser Time Budgets
The transmission data rate of a digital fiber optic communication system is limited by the rise time of the various components, such as amplifiers and LEDs, and the dispersion of the fiber. The cumulative effect of all the components should not limit the bandwidth of the system. The rise time tr and bandwidth BW are related by
BW = 0.35/tr
This equation is used to determine the required system rise time. The appropriate components are then selected to meet the system rise time requirements. The relationship between total system rise time and component rise time is given by the following equation
where ts is the total system rise time and tr1, tr2, … are the rise times associated with the various components.
To simplify matters, divide the system into five groups:
Transmitting circuits (ttc)
LED or laser (tL)
Fiber dispersion (tf)
Photodiode (tph)
Receiver circuits (trc)
The system rise time can then be expressed as
The system bandwidth can then be calculated using the following equation from the total rise time ts as given in the above equation
BW = 0.35/ts
Electrical and Optical Bandwidth
Electrical bandwidth (BWel) is defined as the frequency at which the ratio current out/current in (Iout/Iin) drops to 0.707. (Analog systems are usually specified in terms of electrical bandwidth.)
Optical bandwidth (BWopt) is the frequency at which the ratio power out/power in (Pout/Pin) drops to 0.5.
Because Pin and Pout are directly proportional to Iin and Iout (not I2in and I2out), the half-power point is equivalent to the half-current point. This results in a BWopt that is larger than the BWel as given in the following equation
BWel = 0.707 × BWopt
Fiber Connectors
Many types of connectors are available for fiber optics, depending on the application. The most popular are:
SC—snap-in single-fiber connector
ST and FC—twist-on single-fiber connector
FDDI—fiber distributed data interface connector
In the 1980s, there were many different types and manufacturers of connectors. Today, the industry has shifted to standardized connector types, with details specified by organizations such as the Telecommunications Industry Association(TIA), the International Electrotechnical Commission, and the Electronic Industry Association (EIA).
Snap-in connector (SC)—developed by Nippon Telegraph and Telephone of Japan. Like most fiber connectors, it is built around a cylindrical ferrule that holds the fiber, and it mates with an interconnection adapter or coupling receptacle. A push on the connector latches it into place, with no need to turn it in a tight space, so a simple tug will not unplug it. It has a square cross section that allows high packing density on patch panels and makes it easy to package in a polarized duplex form that ensures the fibers are matched to the proper fibers in the mated connector.
Twist-on single-fiber connectors (ST and FC)—long used in data communication; one of several fiber connectors that evolved from designs originally used for copper coaxial cables.
Duplex connectors—A duplex connector includes a pair of fibers and generally has an internal key so it can be mated in only one orientation. Polarizing the connector in this way is important because most systems use separate fibers to carry signals in each direction, so it matters which fibers are connected. One simple type of duplex connector is a pair of SC connectors, mounted side by side in a single case. This takes advantage of their plug-in-lock design.
Other duplex connectors have been developed for specific types of networks, as part of comprehensive standards. One example is the fixed-shroud duplex (FSD) connector specified by the fiber distributed data interface (FDDI) standard.
Fiber Optic Couplers
A fiber optic coupler is a device used to connect a single (or multiple) fiber to many other separate fibers. There are two general categories of couplers:
Star couplers
T-couplers
Star Couplers
Transmissive type
Optical signals sent into a mixing block are available at all output fibers. Power is distributed evenly. For an n × n star coupler (n-inputs and n-outputs), the power available at each output fiber is 1/n the power of any input fiber.
The output power from a star coupler is simply
Po = Pin/n
where n = number of output fibers.
An important characteristic of transmissive star couplers is cross talk or the amount of input information coupled into another input. Cross coupling is given in decibels and is typically greater than 40 dB.
The reflective star coupler has the same power division as the transmissive type, but cross talk is not an issue because power from any fiber is distributed to all others.
T-Couplers
In the following figure, power is launched into port 1 and is split between ports 2 and 3. The power split does not have to be equal. The power division is given in decibels or in percent. For example, and 80/20 split means 80% to port 2, 20% to port 3. In decibels, this corresponds to 0.97 dB for port 2 and 6.9 dB for port 3.
Directivity describes the transmission between the ports. For example, if P3/P1 = 0.5, P3/P2 does not necessarily equal 0.5. For a highly directive T-coupler, P3/P2 is very small. Typically, no power is expected to be transferred between any two ports on the same side of the coupler.
Another type of T-coupler uses a graded-index (GRIN) lens and a partially reflective surface to accomplish the coupling. The power division is a function of the reflecting mirror. This coupler is often used to monitor optical power in a fiber optic line.
Wavelength-Division Multiplexers (WDM)
The couplers used for wavelength-division multiplexing (WDM) are designed specifically to make the coupling between ports a function of wavelength. The purpose of these couplers is to separate (or combine) signals transmitted at different wavelengths. Essentially, the transmitting coupler is a mixer and the receiving coupler is a wavelength filter. Wavelength-division multiplexers use several methods to separate different wavelengths depending on the spacing between the wavelengths. Separation of 1310 nm and 1550 nm is a simple operation and can be achieved with WDMs using bulk optical diffraction gratings. Wavelengths in the 1550-nm range that are spaced at greater than 1 to 2 nm can be resolved using WDMs that incorporate interference filters. An example of an 8-channel WDM using interference filters is given in the following figure. Fiber Bragg gratings are typically used to separate very closely spaced wavelengths in a DWDM system (< 0.8 nm).
Erbium-Doped Fiber Amplifiers (EDFA)
Erbium-doped fiber amplifiers (EDFA)—The EDFA is an optical amplifier used to boost the signal level in the 1530-nm to 1570-nm region of the spectrum. When it is pumped by an external laser source of either 980 nm or 1480 nm, signal gain can be as high as 30 dB (1000 times). Because EDFAs allow signals to be regenerated without having to be converted back to electrical signals, systems are faster and more reliable. When used in conjunction with wavelength-division multiplexing, fiber optic systems can transmit enormous amounts of information over long distances with very high reliability.
Fiber Bragg Gratings (FBG)
Fiber Bragg gratings—Fiber Bragg gratings are devices that are used for separating wavelengths through diffraction, similar to a diffraction grating (see the following figure). They are of critical importance in DWDM systems in which multiple closely spaced wavelengths require separation. Light entering the fiber Bragg grating is diffracted by the induced period variations in the index of refraction. By spacing the periodic variations at multiples of the half-wavelength of the desired signal, each variation reflects light with a 360° phase shift causing a constructive interference of a very specific wavelength while allowing others to pass. Fiber Bragg gratings are available with bandwidths ranging from 0.05 nm to >20 nm.
Fiber Bragg grating are typically used in conjunction with circulators, which are used to drop single or multiple narrowband WDM channels and to pass other “express” channels. Fiber Bragg
gratings have emerged as a major factor, along with EDFAs, in increasing the capacity of next generation high-bandwidth fiber optic systems.
The following figure depicts a typical scenario in which DWDM and EDFA technology is used to transmit a number of different channels of high-bandwidth information over a single fiber. As shown, n-individual wavelengths of light operating in accordance with the ITU grid are multiplexed together using a multichannel coupler/splitter or wavelength-division multiplexer. An optical isolator is used with each optical source to minimize troublesome back reflections. A tap coupler then removes 3% of the transmitted signal for wavelength and power monitoring. Upon traveling through a substantial length of fiber (50-100 Km), an EDFA is used to boost the signal strength. After a couple of stages of amplifications, an add/drop channel consisting of a fiber Bragg grating and circulator is introduced to extract and then reinject the signal operating at the λ3 wavelength. After another stage of amplification via EDFA, a broadband WDM is used to combine a 1310-nm signal with the 1550-nm window signals. At the receiver end, another broadband WDM extracts the 1310-nm signal, leaving the 1550-nm window signals. The 1550-nm window signals are finally separated using a DWDM that employs an array of fiber Bragg gratings, each tuned to the specific transmission wavelength. This system represents the current state of the art in high-bandwidth fiber optic data transmission.
Hackers a group that consists of skilled computer enthusiasts. A black hat is a person who compromises the security of a computer system without permission from an authorized party, typically with malicious intent. The term white hat is used for a person who is ethically opposed to the abuse of computer systems, but is frequently no less skilled. The term cracker was coined by Richard Stallman to provide an alternative to using the existing word hacker for this meaning.
These are the top 10 Hackers in the world till date, Few has become famous by their Black hat work and few of them are famous by their Ethical Hacking. Below is separate list of World’s All Time Best Hackers and Crackers. Although I represent them by Hackers only because what every they did, was wrong but one thing is sure they were Brilliant. Hacking is not a work of simple mind, only Intelligent Mind can do that.
1. Gary McKinnon
Gary McKinnon, 40, accused of mounting the largest ever hack of United States government computer networks — including Army, Air Force, Navy and NASA systems The court has recommended that McKinnon be extradited to the United States to face charges of illegally accessing 97 computers, causing US$700,000 (400,000 pounds; euro 588,000) in damage.
2. Jonathan James
The youth, known as “cOmrade” on the Internet, pleaded guilty to intercepting 3,300 email messages at one of the Defense Department’s most sensitive operations and stealing data from 13 NASA computers, including some devoted to the new International Space Station. James gained notoriety when he became the first juvenile to be sent to prison for hacking. He was sentenced at 16 years old. He installed a backdoor into a Defense Threat Reduction Agency server. The DTRA is an agency of the Department of Defense charged with reducing the threat to the U.S. and its allies from nuclear, biological, chemical, conventional and special weapons. The backdoor he created enabled him to view sensitive e-mails and capture employee usernames and passwords.James also cracked into NASA computers, stealing software worth approximately $1.7 million. According to the Department of Justice, “The software supported the International Space Station’s physical environment, including control of the temperature and humidity within the living space.” NASA was forced to shut down its computer systems, ultimately racking up a $41,000 cost.
3. Adrian Lamo
Dubbed the “homeless hacker,” he used Internet connections at Kinko’s, coffee shops and libraries to do his intrusions. In a profile article, “He Hacks by Day, Squats by Night,” Lamo reflects, “I have a laptop in Pittsburgh, a change of clothes in D.C. It kind of redefines the term multi-jurisdictional.”Dubbed the “homeless hacker,” he used Internet connections at Kinko’s, coffee shops and libraries to do his intrusions. For his intrusion at The New York Times, Lamo was ordered to pay approximately $65,000 in restitution. He was also sentenced to six months of home confinement and two years of probation, which expired January 16, 2007. Lamo is currently working as an award-winning journalist and public speaker.
4. Kevin Mitnick
The Department of Justice describes him as “the most wanted computer criminal in United States history.” His exploits were detailed in two movies: Freedom Downtime and Takedown. He started out exploiting the Los Angeles bus punch card system to get free rides. Then, like Apple co-founder Steve Wozniak, dabbled in phone phreaking. Although there were numerous offenses, Mitnick was ultimately convicted for breaking into the Digital Equipment Corporation’s computer network and stealing software.Today, Mitnick has been able to move past his role as a black hat hacker and become a productive member of society. He served five years, about 8 months of it in solitary confinement, and is now a computer security consultant, author and speaker.
5. Kevin Poulsen
Also known as Dark Dante, Poulsen gained recognition for his hack of LA radio’s KIIS-FM phone lines, (taing over all of the station’s phone lines) which earned him a brand new Porsche, among other items. Law enforcement dubbed him “the Hannibal Lecter of computer crime.”Authorities began to pursue Poulsen after he hacked into a federal investigation database. During this pursuit, he further drew the ire of the FBI by hacking into federal computers for wiretap information.His hacking specialty, however, revolved around telephones. Poulsen’s most famous hack, In a related feat, Poulsen also “reactivated old Yellow Page escort telephone numbers for an acquaintance who then ran a virtual escort agency.” Later, when his photo came up on the show Unsolved Mysteries, 1-800 phone lines for the program crashed. Ultimately, Poulsen was captured in a supermarket and served a sentence of five years.Since serving time, Poulsen has worked as a journalist. He is now a senior editor for Wired News. His most prominent article details his work on identifying 744 sex offenders with MySpace profiles.
6.Robert Tappan Morris
Morris, son of former National Security Agency scientist Robert Morris, is known as the creator of the Morris Worm, the first computer worm to be unleashed on the Internet. As a result of this crime, he was the first person prosecuted under the 1986 Computer Fraud and Abuse Act.
Morris wrote the code for the worm while he was a student at Cornell. He asserts that he intended to use it to see how large the Internet was. The worm, however, replicated itself excessively, slowing computers down so that they were no longer usable. It is not possible to know exactly how many computers were affected, but experts estimate an impact of 6,000 machines. He was sentenced to three years’ probation, 400 hours of community service and a fined $10,500.Morris is currently working as a tenured professor at the MIT Computer Science and Artificial Intelligence Laboratory. He principally researches computer network architectures including distributed hash tables such as Chord and wireless mesh networks such as Roofnet.
7. Vladimir Levin
Levin accessed the accounts of several large corporate customers of Citibank via their dial-up wire transfer service (Financial Institutions Citibank Cash Manager) and transferred funds to accounts set up by accomplices in Finland, the United States, the Netherlands, Germany and Israel.In 2005 an alleged member of the former St. Petersburg hacker group, claiming to be one of the original Citibank penetrators, published under the name ArkanoiD a memorandum on popular Provider.net.ru website dedicated to telecom market.According to him, Levin was not actually a scientist (mathematician, biologist or the like) but a kind of ordinary system administrator who managed to get hands on the ready data about how to penetrate in Citibank machines and then exploit them.ArkanoiD emphasized all the communications were carried over X.25 network and the Internet was not involved. ArkanoiD’s group in 1994 found out Citibank systems were unprotected and it spent several weeks examining the structure of the bank’s USA-based networks remotely. Members of the group played around with systems’ tools (e.g. were installing and running games) and were unnoticed by the bank’s staff. Penetrators did not plan to conduct a robbery for their personal safety and stopped their activities at some time. Someone of them later handed over the crucial access data to Levin (reportedly for the stated $100).
8. David Smith
David Smith, the author of the e-mail virus known as Melissa, which swamped computers around the world, spreading like a malicious chain letter. He was facing nearly 40 years in jail . About 63,000 viruses have rolled through the Internet, causing an estimated $65 billion in damage, but Smith is the only person to go to federal prison in the United States for sending one.
9. Mark Abene
Abene (born 1972), better known by his pseudonym Phiber Optik, is a computer security hacker from New York City. Phiber Optik was once a member of the Hacker Groups Legion of Doom and Masters of Deception. In 1994, he served a one-year prison sentence for conspiracy and unauthorized access to computer and telephone systems.
Phiber Optik was a high-profile hacker in the early 1990s, appearing in The New York Times, Harper’s, Esquire, in debates and on television. Phiber Optik is an important figure in the 1995 non-fiction book Masters of Deception — The Gang that Ruled Cyberspace.
10. Onel A. de Guzman
el A. de Guzman, a Filipino computer student, Greatest Hacker of all time. He was creator of “Love Bug” virus that crippled computer e-mail systems worldwide.
SDH stands for Synchronous Digital Hierarchy & is an international Standard for a high capacity optical telecommunications network.It is a synchronous digital transport system aimed at providing a more simple,economical,& flexible teleccommunication infrastructure.
Q. What is the difference between SONET and SDH?
A. To begin with there is no STS-1. The first level in the SDH hierarchy is STM-1 (Synchronous Transport Mode 1) is has a line rate of 155.52 Mb/s. This is equivalent to SONET’s STS-3c. Then would come STM-4 at 622.08 Mb/s and STM-16 at 2488.32 Mb/s. The other difference is in the overhead bytes which are defined slightly differently for SDH. A common misconception is that STM-Ns are formed by multiplexing STM-1s. STM-1s, STM-4s and STM-16s that terminate on a network node are broken down to recover the VCs which they contain. The outbound STM-Ns are then reconstructed with new overheads.
Q. What are the advantages of SDH over PDH ?
The increased configuration flexibility and bandwidth availability of SDH provides significant advantages over the older telecommunications system.
These advantages include:
A reduction in the amount of equipment and an increase in network reliability.
The provision of overhead and payload bytes – the overhead bytes permitting management of the payload bytes on an individual basis and facilitating centralized Fault sectionalisation.-nearly 5% of signal structure allocated for this purpose.
The definition of a synchronous multiplexing format for carrying lower-level digital signals (such as 2 Mbit/s, 34 Mbit/s, 140 Mbit/s) which greatly simplifies the interface to digital switches, digital cross-connects, and add-drop multiplexers.
The availability of a set of generic standards, which enable multi-vendor interoperability.
The definition of a flexible architecture capable of accommodating future applications, with a variety of transmission rates.Existing & future signals can be accomodated.
Q. What are the main limitations of PDH ?
The main limitations of PDH are:
Inability to identify individual channels in a higher-order bit stream.
Insufficient capacity for network management
Most PDH network management is proprietary
There’s no standardised definition of PDH bit rates greater than 140 Mbit/s
There are different hierarchies in use around the world. Specialized interface equipment is required to interwork the two hierarchies
Q. What are some timing/sync defining rules of thumb?
A.
1. A node can only receive the synchronization referencesignal from another node that contains a clock ofequivalent or superior quality (Stratum level).
2. The facilities with the greatest availability (absence of outages) should be selected forsynchronization facilities.
3. Where possible, all primary and secondary synchronization facilities should be diverse, and synchronization facilities within the same cable should be minimized.
4. The total number of nodes in series from the stratum 1 source should be minimized. For example, the primary synchronization network would ideally look like a star configuration with the stratum 1 source at the center. The nodes connected to the star would branch out in decreasing stratum level from the center
5. No timing loops may be formed in any combination of primary
Q. What is meant by “Plesiochronous” ?
If two digital signals are Plesiochronous, their transitions occur at “almost” the same rate, with any variation being constrained within tight limits. These limits are set down in ITU-T recommendation G.811. For example, if two networks need to interwork, their clocks may be derived from two different PRCs. Although these clocks are extremely accurate, there’s a small frequency difference between one clock and the other. This is known as a plesiochronous difference.
Q. What is meant by “Synchronous” ?
In a set of Synchronous signals, the digital transitions in the signals occur at exactly the same rate. There may however be a phase difference between the transitions of the two signals, and this would lie within specified limits. These phase differences may be due to propagation time delays, or low-frequency wander introduced in the transmission network. In a synchronous network, all the clocks are traceable to one Stratum 1 Primary Reference Clock (PRC).
Q. What is meant by “Asynchronous” ?
In the case of Asynchronous signals, the transitions of the signals don’t necessarily occur at the same nominal rate. Asynchronous, in this case, means that the difference between two clocks is much greater than a plesiochronous difference. For example, if two clocks are derived from free-running quartz oscillators, they could be described as asynchronous.
Q. What are the various steps in multiplexing ?
The multiplexing principles of SDH follow, using these terms and definitions:
Mapping: A process used when tributaries are adapted into Virtual Containers (VCs) by adding justification bits and Path Overhead (POH) information.
Aligning: This process takes place when a pointer is included in a Tributary Unit (TU) or an Administrative Unit (AU), to allow the first byte of the Virtual Container to be located.
Multiplexing: This process is used when multiple lower-order path layer signals are adapted into a higher-order path signal, or when the higher-order path signals are adapted into a Multiplex Section.
Stuffing: As the tributary signals are multiplexed and aligned, some spare capacity has been designed into the SDH frame to provide enough space for all the various tributary rates. Therefore, at certain points in the multiplexing hierarchy, this space capacity is filled with “fixed stuffing” bits that carry no information, but are required to fill up the particular frame.
Explain 1+1 protection. In 1+1 protection switching, there is a protection facility (backup line) for each working facility At the near end the optical signal is bridged permanently (split into two signals) and sent over both the working and the protection facilities simultaneously, producing a working signal and a protection signal that are identical.At the Far End of the section, both signalsare monitored independently for failures. The receiving equipment selects either the working or the protection signal. This selection is based on the switch initiation criteria which are either a signal fail (hard failure such as the loss of frame (LOF) within an optical signal), or a signal degrade (soft failure caused by the error rate exceeding some pre-defined value).
Explain 1:N protection. In 1:N protection switching, there is one protection facility for several working facilities (the range is from 1 to 14). In 1:N protection architecture, all communication from the Near End to the Far End is carried out over the APS channel, using the K1 and K2 bytes. All switching is revertive; that is, the traffic reverts to the working facility as soon as the failure has been corrected.
In 1:N protection switching, optical signals are normally sent only over the working facilities, with the protection facility being kept free until a working facility fails.
Q. If voice traffic is still intelligible to the listener in a relatively poor communication channel, why isn’t it easy to pass it across a network optimized for data?
A. Data communication requires very low Bit-error Ratio (BER) for high throughput but does not require constrained propagation, processing, or storage delay. Voice calls, on the other hand, are insensitive to relatively high BER, but very sensitive to delay over a threshold of a few tens of milliseconds. This insensitivity to BER is a function of the human brain’s ability to interpolate the message content, while sensitivity to delay stems from the interactive nature (full-duplex) of voice calls. Data networks are optimized for bit integrity, but end-to-end delay and delay variation are not directly controlled. Delay variation can vary widely for a given connection, since the dynamic path routing schemes typical of some data networks may involve varying numbers of nodes (for example, routers). In addition, the echo-cancellers deployed to handle known excess delay on a long voice path are automatically disabled when the path is used for data. These factors tend to disqualify data networks for voice transport if traditional public switched telephone network (PSTN) quality is desired.
Q. How does synchronization differ from timing?
A. These terms are commonly used interchangeably to refer to the process of providing suitable accurate clocking frequencies to the components of the synchronous network. The terms are sometimes used differently. In cellular wireless systems, for example, “timing” is often applied to ensure close alignment (in real time) of control pulses from different transmitters; “synchronization” refers to the control of clocking frequencies.
Q. If I adopt sync status messages in my sync distribution plan, do I have to worry about timing loops?
A. Yes. Source Specific Multicasts (SSMs) are certainly a very useful tool for minimizing the occurrence of timing loops, but in some complex connectivities they are not able to absolutely preclude timing loop conditions. In a site with multiple Synchronous Optical Network (SONET) rings, for example, there are not enough capabilities for communicating all the necessary SSM information between the SONET network elements and the Timing Signal Generator (TSG) to cover the potential timing paths under all fault conditions. Thus, a comprehensive fault analysis is still required when SSMs are deployed to ensure that a timing loop does not develop.
Q. If ATM is asynchronous by definition, why is synchronization even mentioned in the same sentence?
A. The term Asynchronous Transfer Mode applies to layer 2 of the OSI 7-layer model (the data link layer), whereas the term synchronous network applies to layer 1 (the physical layer). Layers 2, 3, and so on, always require a physical layer which, for ATM, is typically SONET or Synchronous Digital Hierarchy (SDH); thus the “asynchronous” ATM system is often associated with a “synchronous” layer 1. In addition, if the ATM network offers circuit emulation service (CES), also referred to as constant bit-rate (CBR), then synchronous operation (that is, traceability to a primary reference source) is required to support the preferred timing transport mechanism, Synchronous Residual Time Stamp (SRTS).
Q. Most network elements have internal stratum 3 clocks with 4.6ppm accuracy, so why does the network master clock need to be as accurate as one part in 10^11?
A. Although the requirements for a stratum 3 clock specify a free-run accuracy (also pull-in range) of 4.6ppm, a network element (NE) operating in a synchronous environment is never in free-run mode. Under normal conditions, the NE internal clock tracks (and is described as being a traceable to) a Primary Reference Source that meets stratum 1 long-term accuracy of one part in 10^11.
This accuracy was originally chosen because it was available as a national primary reference source from a cesium-beam oscillator, and it ensured adequately low slip-rate at international gateways.
Note: If primary reference source (PRS) traceability is lost by the NE, it enters holdover mode. In this mode, the NE clock’s tracking phase lock loop (PLL) does not revert to its free-run state, it freezes its control point at the last valid tracking value. The clock accuracy then drifts elegantly away from the desired traceable value, until the fault is repaired and traceability is restored.
Q. What are the acceptable limits for slip and/or pointer adjustment rates when designing a sync network?
A. When designing a network’s synchronization distribution sub-system, the targets for sync performance are zero slips and zero pointer adjustments during normal conditions. In a real-world network, there are enough uncontrolled variables that these targets will not be met over any reasonable time, but it is not acceptable practice to design for a given level of degradation (with the exception of multiple timing island operation, when a worst-case slip-rate of no more than one slip in 72 days between islands is considered negligible). The zero-tolerance design for normal conditions is supported by choosing distribution architectures and clocking components that limit slip-rates and pointer adjustment rates to acceptable levels of degradation during failure (usually double-failure) conditions.
Q. Why is it necessary to spend time and effort on synchronization in telecom networks when the basic requirement is simple, and when computer LANs have never bothered with it?
A. The requirement for PRS traceability of all signals in a synchronous network at all times is certainly simple, but it is deceptively simple. The details of how to provide traceability in a geographically distributed matrix of different types of equipment at different signal levels, under normal and multiple-failure conditions, in a dynamically evolving network, are the concerns of every sync coordinator. Given the number of permutations and combinations of all these factors, the behavior of timing signals in a real-world environment must be described and analyzed statistically. Thus, sync distribution network design is based on minimizing the probability of losing traceability while accepting the reality that this probability can never be zero.
Q. How many stratum 2 and/or stratum 3E TSGs can be chained either in parallel or series from a PRS?
A. There are no defined figures in industry standards. The sync network designer must choose sync distribution architecture and the number of PRSs and then the number and quality of TSGs based on cost-performance trade-offs for the particular network and its services.
Q. Is synchronization required for non-traditional services such as voice-over-IP?
A. The answer to this topical question depends on the performance required (or promised) for the service. Usually, Voice-over-IP is accepted to have a low quality reflecting its low cost (both relative to traditional PSTN voice service). If a high slip-rate and interruptions can be accepted, then the voice terminal clocks could well be free-running. If, however, a high voice quality is the objective (especially if voice-band modems including Fax are to be accommodated) then you must control slip occurrence to a low probability by synchronization to industry standards. You must analyze any new service or delivery method for acceptable performance relative to the expectations of the end-user before you can determine the need for synchronization.
Q. Why is a timing loop so bad, and why is it so difficult to fix?
A. Timing loops are inherently unacceptable because they preclude having the affected NEs synchronized to the PRS. The clock frequencies are traceable to an unpredictable unknown quantity; that is, the hold-in frequency limit of one of the affected NE clocks. By design, this is bound to be well outside the expected accuracy of the clock after several days in holdover, so performance is guaranteed to become severely degraded.
The difficulty in isolating the instigator of a timing loop condition is a function of two factors: first, the cause is unintentional (a lack of diligence in analyzing all fault conditions, or an error in provisioning, for example) so no obvious evidence exists in the network’s documentation. Secondly, there are no sync-specific alarms, since each affected NE accepts the situation as normal. Consequently, you must carry out trouble isolation without the usual maintenance tools, relying on a knowledge of the sync distribution topology and on an analysis of data on slip counts and pointer counts that is not usually automatically correlated.
Q.How do you get value of an E1 as 2.048Mbps?
A.As we know that voice signal is of frequency 3.3 Khz,and as per the Nyquist Rate or PCM quantization rate for transmission we required signal of >=2f(here ‘f’ is GIF [3.3]=4).and each sample of data is a byte. DS0: provides one 64kbps channel.E1: 32 DS0 or 32 channels with 64kbps
Also we know that voice signal frame consisits of 32 bytes .Hence value of an E1 will be
=2x4Khzx8bitsx32slots
=2.048Mbps
OR
PCM multiplexing is carried out with the sampling process, sampling the analog sources sequentially. These
sources may be the nominal 4-kHz voice channels or other information sources that have a 4-kHz bandwidth, such as data or freeze-frame video. The final result of the sampling and subsequent quantization and coding is a series of electrical pulses, a serial bit stream of 1s and 0s that requires some identification or indication of the beginning of a sampling sequence. This identification is necessary so that the far-end receiver knows exactly when the sampling sequence starts. Once the receiver receives the “indication,” it knows a priori (in the case of DS1) that 24 eight-bit slots follow. It synchronizes the receiver. Such identification is carried out by a framing bit, and one full sequence or cycle of samples is called a frame in PCM terminology.
Consider the framing structure of E1
PCM system using 8-level coding (e.g., 2^8= 256 quantizing steps or distinct PCM code words). Actually 256 samples of a signal will be sufficient to regenerate the original signal and each signal is made up of 1 or 0.
The E1 European PCM system is a 32-channel system. Of the 32 channels, 30 transmit speech (or data) derived from incoming telephone trunks and the remaining 2 channels transmit synchronization-alignment and signaling information. Each channel is allotted an 8-bit time slot (TS), and we tabulate TS 0 through 31 as follows:
TS TYPE OF INFORMATION
0 Synchronizing (framing)
1–15 Speech
16 Signaling
17–31 Speech
In TS 0 a synchronizing code or word is transmitted every second frame, occupying digits 2 through 8 as 0011011. In those frames without the synchronizing word, the second bit of TS 0 is frozen at a 1 so that in these frames the synchronizing word cannot be imitated. The remaining bits of TS 0 can be used for the transmission of supervisory information signals .Again, E1 in its primary rate format transmits 32 channels of 8-bit time slots. An E1 frame therefore has 8*32 =256 bits. There is no framing bit. Framing alignment is
carried out in TS 0.
The E1 bit rate to the line is:256 *8000 = 2, 048, 000 bps or 2.048 Mbps
Question for you Electrical E1 is ac or dc in nature????
0G: phones, standing for the 1st generation of mobile phones, were satellite phones developed for boats mainly – but anyone could get one in one’s car in the beginning of the 90s for several thousand dollars. Networks such as Iridium, Global Star and Eutelsat were truly worldwide (although for physical reasons, think of a satellite as a fixed point above the equator, some Northern parts of Scandinavia aren’t reachable), and everybody thought at that time that satellite phones would become mainstream products as soon as devices got smaller and cheaper. This vision proved wrong when the GSM concretely came to life in 1990/1991 in Finland.
1G: Firstly, there were analog GSM systems, that existed for a few years. And then came the digital systems.
2G: the second generation of mobile telecommunications still is the most widespread technology in the world; you’ve basically all heard of the GSM norm (GSM stands for Groupe Spécial Mobile in French, renamed in Global System for Mobility). The GSM operates in the 850Mhz. and 1900Mhz. bands in the US, & 900Mhz. and 1.8Mhz. bands in the rest of the world (eg did you know Bluetooth stands in the 2.4Ghz. area, just like your…microwave!? But that’s another story, not related to this article) and delivers data at the slow rate of 9.6 Kbytes/sec.
2.5G: For that last reason (9.6 Kbytes/sec doesn’t allow you to browse the Net or up/download an image), telco operators came up with the GPRS (remember all the hype around the Wap) which could enable much faster communications (115Kbytes.sec). But the market decided it was still not enough compared to what they had at home.
2.75G: EDGE (I just called it 2.75G, 2.5′s not the official or unofficial number at all), which is a pretty recent standard, allows for downloading faster. Since mobile devices have become both a TV and a ‘walkman’ or music player, people needed to be able to watch streaming video and download mp3 files faster – that’s precisely what EDGE allows for and that’s for the good news. The bad news is that if EDGE rocks at downloading, it’s protocol is asymmetrical hence making EDGE suck at uploading ie broadcasting videos of yours for instance. Still an interesting achievement thanks to which data packets can effectively reach 180kbytes/sec. EDGE is now widely being used.
3G: also called UMTS (Universal Mobile Telecommunications Standard). Aimed at enabling long expected videoconferencing, although nobody seems to actually use it (do you know any?). Its other name is 3GSM, which says literally that UMTS is 3 times better than GSM. One issue though: depending on the deployment level of the area you are in and your device, your phone will (have to be) handle(d) from the GSM network to the UMTS network, and conversely – making billing more complex to understand for the consumers. One of the major positive points of UMTS is its global roaming capabilities (roaming is the process that allows you, at a cost, to borrow bandwidth from a telco provider that’s not yours; you usually use roaming when calling from abroad).
3.5G or 3G+: HSDPA is theoretically 6 times faster than UMTS (up to 3.6 Mbytes/sec)! Practically speaking, this would mean downloading an mp3 file would take about 30 secs instead of something like 2 minutes. Not bad, uh?
4G: still a research lab standard, at least to my knowledge, that should combine the best of cellphone network technologies with WiMax, wireless Internet, voice over IP and IPv6 (a post about the latter soon). Data rates are expected to reach 100 Mbytes/sec.
LTE is popularly called a 4G technology. It is an all-IP technology based on orthogonal frequency-division multiplexing (OFDM), which is more spectrally efficient — meaning it can deliver more bits per Hertz. LTE will be the technology of choice for most existing Third Generation Partnership Project (3GPP) and 3GPP2mobile operators. It will provide economy of scale and spectrum reuse. LTE also offers smooth integration and handover to and from existing 3GPP and 3GPP2 networks, supporting full mobility and global roaming, and ensuring that operators can deploy LTE in a gradual manner by leveraging their existing legacy networks for service continuity. LTE also brings subscribers a “true” mobile broadband (~5–10 Mb/s/~15 ms latency) that enables a quality video experience and media mobility. The LTE standard has been defined with as much flexibility as possible so that operators can deploy it in all current existing frequencies as well as new spectrum. Operators can deploy the technology in as little as 1.4 MHz or as much as 20MHz of spectrum and grow the network as demand for data services grows . LTE will also appear in a number of different spectrum bands around the world, including the new 2.6 GHz band, which is perfect as a capacity band since operators are able to secure up to 2 ×20 MHz of virgin spectrum. LTE can also be deployed in reformed GSM bands in 900 MHz and 1800 MHz and digital dividend spectrum (e.g., 700 MHz in the United States), providing superior coverage and global roaming in the rest of the 3GPP market.
With improvements in capacity, speed, and latency, LTE will not only make accessing applications faster, but will enable a wealth of new applications previously available only on a wired Internet connection. The wall between wired and wireless will come down. And moving from one environment to another with your content moving seamlessly will become second nature:
•Continuing to watch the latest TV series recorded on your DVR, automatically transferred to the 4G network as you walk out the door
•Uploading content onto your social networking profile to let your friends know what you are up to
•The PowerPoint file you just saved on your laptop instantaneously becoming available on your Smartphone
•Or even your LTE-enabled digital camera uploading your latest picture onto your home server or social networking site for your family to see.
1. He bought his first share at age 11 and he now regrets that he started too late! 2. He bought a small farm at age 14 with savings from delivering newspapers. 3. He still lives in the same small 3-bedroom house in mid-town Omaha, which he bought after he got married 50 years ago. He says that he has everything he needs in that house. His house does not have a wall or a fence. 4. He drives his own car everywhere and does not have a driver or security people around him. 5. He never travels by private jet, although he owns the world’s largest private jet company. 6. His company, Berkshire Hathaway, owns 63 companies. He writes only one letter each year to the CEOs of these companies, giving them goals for the year. He never holds meetings or calls them on a regular basis. He has given his CEO’s only two rules. Rule number 1: do not lose any of your share holder’s money. Rule number 2: Do not forget rule number 1. 7. He does not socialize with the high society crowd. His past time after he gets home is to make himself some pop corn and watch Television. 8. Bill Gates, the world’s richest man met him for the first time only 5 years ago. Bill Gates did not think he had anything in common with Warren Buffet. So he had scheduled his meeting only for half hour. But when Gates met him, the meeting lasted for ten hours and Bill Gates became a devotee of Warren Buffet. 9. Warren Buffet does not carry a cell phone, nor has a computer on his desk.
His advice to young people: “Stay away from credit cards and invest in yourself and Remember: A. Money doesn’t create man but it is the man who created money. B. Live your life as simple as you are. C. Don’t do what others say, just listen them, but do what you feel good. D. Don’t go on brand name; just wear those things in which u feel comfortable. E. Don’t waste your money on unnecessary things; just spend on them who really in need rather. F. After all it’s your life then why gives chance to others to rule our life.”
Albert Einstein said: We owe a lot to the Indians, who taught us how to count, without which no worthwhile scientific discovery could have been made.
Mark Twain said: India is, the cradle of the human race, the birthplace of human speech, the mother of history, the grandmother of legend, and the great grand mother of tradition. Our most valuable and most instructive materials in the history of man are treasured up in India only.
French scholar Romain Rolland said: If there is one place on the face of earth where all the dreams of living men have found a home from the very earliest days when man began the dream of existence, it is India.
Hu Shih, former Ambassador of China to USA said: India conquered and dominated China culturally for 20 centuries without ever having to send a single soldier across her border.
India is the world’s largest, oldest, continuous civilization.
India never invaded any country in her last 10000 years of history.
India is the world’s largest democracy.
Varanasi, also known as Benares, was called “the ancient city” when Lord Buddha visited it in 500 B.C.E, and is the oldest, continuously inhabited city in the world today.
India invented the Number System. Zero was invented by Aryabhatta.
The World’s first university was established in Takshashila in 700BC. More than 10,500 students from all over the world studied more than 60 subjects. The University of Nalanda built in the 4th century BC was one of the greatest achievements of ancient India in the field of education.
Sanskrit is the mother of all the European languages. Sanskrit is the most suitable language for computer software – a report in Forbes magazine, July 1987.
Ayurveda is the earliest school of medicine known to humans. Charaka, the father of medicine consolidated Ayurveda 2500 years ago. Today Ayurveda is fast regaining its rightful place in our civilization.
Although modern images of India often show poverty and lack of development, India was the richest countryon earth until the time of British invasion in the early 17th Century. Christopher Columbus was attracted by India’s wealth.
The art of Navigation was bornin the river Sindhu 6000 years ago. The very word Navigation is derived from the Sanskrit word NAVGATIH. The word navy is also derived from Sanskrit ‘Nou’.
Bhaskaracharya calculated the time taken by the earth to orbit the sun hundreds of years before the astronomer Smart. Time taken by earth to orbit the sun: (5th century) 365.258756484 days.
The value of pi was first calculated by Budhayana, and he explained the concept of what is known as the Pythagorean Theorem. He discovered this in the 6th century long before the European mathematicians.
Algebra, trigonometry and calculus came from India. Quadratic equations were by Sridharacharya in the 11th century. The largest numbers the Greeks and the Romans used were 106 whereas Hindus used numbers as big as 10**53(10 to the power of 53) with specific names as early as 5000 BCE during the Vedic period. Even today, the largest used number is Tera 10**12(10 to the power of 12).
IEEE has proved what has been a century old suspicion in the world scientific community that the pioneer of wireless communication was Prof. Jagdish Bose and not Marconi.
The earliest reservoir and dam for irrigation was built in Saurashtra.
According to Saka King Rudradaman I of 150 CE a beautiful lake called Sudarshana was constructed on the hills of Raivataka during Chandragupta Maurya’s time.
Chess (Shataranja or AshtaPada) was invented in India.
Sushruta is the father of surgery. 2600 years ago he and health scientists of his time conducted complicated surgeries like cesareans, cataract, artificial limbs, fractures, urinary stones and even plastic surgery and brain surgery. Usage of anesthesia was well known in ancient India. Over 125 surgical equipment were used. Deep knowledge of anatomy, physiology, etiology, embryology, digestion, metabolism, genetics and immunity is also found in many texts.
When many cultures were only nomadic forest dwellers over 5000 years ago, Indians established Harappan culture in Sindhu Valley (Indus Valley Civilization).
The four religions born in India, Hinduism, Buddhism, Jainism, and Sikhism, are followed by 25% of the world’s population.
The place value system, the decimal system was developed in India in 100 BC.
India is one of the few countries in the World, which gained independence without violence.
India has the second largest pool of Scientists and Engineers in the World.
India is the largest English speaking nation in the world.
India is the only country other than US and Japan, to have built a super computer indigenously.
The Ethernet connections must be tested to ensure that they are operating correctly and also they are performing to the required levels. This is done by testing the bandwidth, the delay and the loss of frames in the connection. In Ethernet terms these are called Throughput, Latency and Frame Loss.
Throughput
Data throughput is simply the maximum amount of data, that can be transported from source to destination. However the definition and measuring of throughput is complicated by the need to define an acceptable level of quality. For example, if 10% errored or lost frames were deemed to be acceptable then the throughput would be measured at 10% error rate. Here we have generally accepted definition that throughput should be measured with zero errors or lost frames. In any given Ethernet system the absolute maximum throughput will be equal to the data rate, e.g. 10 Mbit/s
100 Mbit/s or 1000 Mbit/s. In practice these figures cannot be achieved because of the effect of frame size.
The smaller size frames have a lower effective throughput than the larger sizes because of the addition of the pre-amble and the interpacket gap bytes, which do not count as data.
Latency
Latency is the total time taken for a frame to travel from source to destination. This total time is the sum of both the processing delays in the network elements and the propagation delay along the transmission medium. In order to measure latency a test frame containing a time stamp is transmitted through the network. The time stamp is then checked when the frame is received. In order for this to happen the test frame needs to return to the original test set by means of a loopback (round-trip delay).
Frame Loss
Frame loss is simply the number of frames that were transmitted successfully from the source but were never received at the destination. It is usually referred to as frame loss rate and is expressed as a percentage of the total frames transmitted. For example if 1000 frames were transmitted but only 900 were received the frame
loss rate would be: (1000 – 900) / 1000 x 100% = 10%
Frames can be lost, or dropped, for a number of reasons including errors, over-subscription and excessive delay.
Errors – most layer 2 devices will drop a frame with an incorrect FCS. This means that a single bit error in transmission will result in the entire frame being dropped. For this reason BER, the most fundamental measure of a SONET/SDH service, has no meaning in Ethernet since the ratio of good to errored bits cannot be ascertained.
Oversubscription – the most common reason for frame loss is oversubscription of the available bandwidth. For example, if two 1000 Mbit/s Ethernet services are mapped into a single 622 Mbit/s SONET/SDH pipe (a common scenario) then the bandwidth limit is quickly reached as the two gigabit Ethernet services are loaded. When the limit is reached, frames may be dropped.
Excessive Delay – The nature of Ethernet networks means that it is possible for frames to be delayed for considerable periods of time. This is important when testing as the tester is “waiting” for all of the transmitted frames to be received and counted. At some point the tester has to decide that a transmitted frame will not be received and count the frame as lost. The most common time period used to make this decision is the RFC specification of two seconds. Thus any frame received more then two seconds after it is transmitted would be counted as lost.
Preamble/Start of Frame Delimiter, 8 Bytes – Alternate ones and zeros for the preamble, 11010101 for the SFD (Start of Frame Delimiter). This allows for receiver synchronisation and marks the start of frame.
Destination Address, 6 Bytes – The MAC destination address of the frame, usually written in hex, is used to route frames between devices. Some MAC addresses are reserved, or have special functions. For example FF:FF:FF:FF:FF:FF is a broadcast address which would go
to all stations.
Sources Address, 6 Bytes – The MAC address of the sending station, usually written in hex. The source address is usually built into a piece of equipment at manufacture. The first three bytes would identify the manufacturer and the second three bytes would be unique to the equipment. However there are some devices, test equipment for example, in which the address is changeable.
VLAN Tag, 4 Bytes (optional) – The VLAN tag is optional. If present it provides a means of separating data into “virtual” LANs, irrespective of MAC address. It also provides a “priority tag” which can be used to implement quality of service functions.
Length/Type, 2 Bytes – This field is used to give either the length of the frame or the type of data being carried in the data field. If the length/type value is less than 05DC hex then the value represents the length of the data field. If the value is greater than 0600 hex then it represents the type of protocol in the data field, for example 0800 hex would mean the frame was carrying
809B hex would mean the frame was carrying
AppleTalk.
Data, 46 to 1500 Bytes – The client data to be transported. This would normally include some higher layer protocol, such as IP or AppleTalk.
Frame Check Sequence, 4 Bytes – The check sequence is calculated over the whole frame by the transmitting device. The receiving device will re-calculate the checksum and ensure it matches the one inserted by the transmitter. Most types of Ethernet equipment will drop a frame with an incorrect or missing FCS.
The minimum legal frame size, including the FCS but excluding the preamble, is 64 bytes. Frames below the minimum size are known as “runts” and would be discarded by most Ethernet equipment.
The maximum standard frame size is 1522 bytes if VLAN tagging is being used and 1518 bytes if VLAN is not being used. It is possible to use frames larger than the maximum size. Such frames are called “Jumbo Frames” and are supported by some manufacturer’s equipment in various sizes up to 64 Kbyte. Jumbo frames are identical in form to standard frames but with a bigger data field.
This produces a better ratio of “overhead” bytes to data bytes and hence more efficient transmission. Jumbos are non-standard and manufacturer specific and therefore interoperability cannot be guaranteed.
The frames are transmitted from left to right, least significant bit first. The frames are separated by an “inter-packet gap”. The minimum length of the interpacket gap is 12 bytes. The inter-packet gap exists because in a half duplex system time is needed for the medium to go quiet before the next frame starts transmission. The inter-packet gap is not really needed for full duplex operation but is still used for consistency.
Auto-Negotiation
Most Ethernet devices support auto-negotiation. When two devices are first connected together they will send information to each other to “advertise” their capabilities. The devices will then configure themselves to the highest common setting. The capabilities negotiated are speed, full or half duplex operation and the use of flow control.
Adware
Adware is software that presents banner ads or in pop-up windows through a bar that appears on a computer screen. Those advertising spots usually can’t be removed and are consequently always visible. The connection data allow many conclusions on the usage behavior and are problematic in terms of data security.
Backdoors
A backdoor can gain access to a computer by going around the computer access security mechanisms.
A program that is being executed in the background generally enables the attacker almost unlimited rights. User’s personal data can be spied with the backdoor’s help, but are mainly used to install further computer viruses or worms on the relevant system.
Boot viruses
The boot or master boot sector of hard drives is mainly infected by boot sector viruses. They overwrite important information necessary for the system execution. One of the awkward consequences: the computer system cannot be loaded any more…
Bot-Net
A Bot-Net is collection of softwarre bots, which run autonomously. A Bot-Net can comprise a collection of cracked machines running programs (usually referred to as worms, Trojans) under a common command and control infrastructure. Boot-Nets server various purposes, including Denial-of-service attacks, etc., partly without the affected PC user’s knowledge. The main potential of Bot-Nets is that the networks can achieve dimensions on thousands of computers and its bandwidth sum bursts most conventional Internet accesses.
Dialer
A dialer is a computer programm that establishes a connection to the Internet or to another computer network through the telephone line or the digital ISDN network. Fraudsters use dialers to charge users high rates when dialing up to the Internet without their knowledge.
EICAR test file
The EICAR test file is a test pattern that was developed at the European Institute for Computer Antivirus Research for the purpose to test the functions of anti-virus programs. It is a text file which is 68 characters long and its file extension is “.COM” all virus scanners should recognize as virus.
Exploit
An exploit (security gap) is a computer program or script that takes advantage of a bug, glitch or vulnerability leading to privilege escalation or denial of service on a computer system. A form of an exploit for example are attacks from the Internet with the help of manipulated data packages. Programs can be infiltrated in order to obtain higher access.
Grayware
Grayware operates in a way similar to malware, but it is not spread to harm the users directly. It does not affect the system functionality as such. Mostly, information on the patterns of use is collected in order to either sell these data or to place advertisements systematically.
Hoaxes
The users have obtained virus alerts from the Internet for a few years and alerts against viruses in other networks that are supposed to spread via email. These alerts are spread per email with the request that they should be sent to the highest possible number of colleagues and to other users, in order to warn everyone against the “danger”.
Honeypot
A honeypot is a service (program or server), which is installed in a network.
It has the function to monitor a network and to protocol attacks. This service is unknown to the legitime user – because of this reason he is never addressed. If an attacker examines a network for the weak points and uses the services which are offered by a Honeypot, it is protocolled and an alert sets off.
Keystroke logging
Keystroke logging is a diagnostic tool used in software development that captures the user’s keystrokes. It can be useful to determine sources of error in computer systems and is sometimes used to measure employee productivity on certain clerical tasks. Like this, confidential and personal data, such as passwords or PINs, can be spied and sent to other computers via the Internet.
Macro viruses
Macro viruses are small programs that are written in the macro language of an application (e.g. WordBasic under WinWord 6.0) and that can normally only spread within documents of this application. Because of this, they are also called document viruses. In order to be active, they need that the corresponding applications are activated and that one of the infected macros has been executed. Unlike “normal” viruses, macro viruses do consequently not attack executable files but they do attack the documents of the corresponding host-application.
Polymorph viruses
Polymorph viruses are the real masters of disguise. They change their own programming codes – and are therefore very hard to detect.
Program viruses
A computer virus is a program that is capable to attach itself to other programs after being executed and cause an infection. Viruses multiply themselves unlike logic bombs and Trojans. In contrast to a worm, a virus always requires a program as host, where the virus deposits his virulent code. The program execution of the host itself is not changed as a rule.
Script viruses and worms
Such viruses are extremely easy to program and they can spread – if the required technology is on hand – within a few hours via email round the globe.
Script viruses and worms use a script language such as Javascript, VBScript etc. to infiltrate in other new scripts or to spread by activation of operating system functions. This frequently happens via email or through the exchange of files (documents).
A worm is a program that multiplies itself but that does not infect the host. Worms can consequently not form part of other program sequences. Worms are often the only possibility to infiltrate any kind of damaging programs on systems with restrictive security measures.
Spyware
Spyware are so called spy programs that intercept or take partial control of a computer’s operation without the user’s informed consent. Spyware is designed to expolit infected computers for commerical gain. Typical tactics furthering this goal include delivery of unsolicited pop-up advertisements. AntiVir is able to detect this kind of software with the category “ADSPY” or “adware-spyware”.
Trojan horses (short Trojans)
Trojans are pretty common nowadays. We are talking about programs that pretend to have a particular function, but that show their real image after execution and carry out a different function that, in most cases, is destructive. Trojan horses cannot multiply themselves, which differenciates them from viruses and worms. Most of them have an interesting name (SEX.EXE or STARTME.EXE) with the intention to induce the user to start the Trojan. Immediately after execution they become active and can, for example, format the hard drive. A dropper is a special form of Trojan that ‘drops’ viruses, i.e. embeds viruses on the computer system.
Zombie
A Zombie-PC is a computer that is infected with malware programs and that enables hackers to abuse computers via remote control for criminal purposes. The affected PC, for example, can start Denial-of-Service- (DoS) attacks at command or send spam and phishing emails.
“Hyder Ali, prince of Mysore, developed war rockets with an important change: the use of metal cylinders to contain the combustion powder. Although the hammered soft iron he used was crude, the bursting strength of the container of black powder was much higher than the earlier paper construction. Thus a greater internal pressure was possible, with a resultant greater thrust of the propulsive jet. The rocket body was lashed with leather thongs to a long bamboo stick. Range was perhaps up to three-quarters of a mile (more than a kilometre). Although individually these rockets were not accurate, dispersion error became less important when large numbers were fired rapidly in mass attacks. They were particularly effective against cavalry and were hurled into the air, after lighting, or skimmed along the hard dry ground. Hyder Ali’s son, Tippu Sultan, continued to develop and expand the use of rocket weapons, reportedly increasing the number of rocket troops from 1,200 to a corps of 5,000. In battles at Seringapatamin 1792 and 1799 these rockets were used with considerable effect against the British.” –Encyclopedia Britannica (2008). rocket and missile.
India is a rich country when it comes to its achievements and other traits such has trade and technoslogy, here I have collected some facts about India, in terms of Industries, Trade and Technology –
India is being recognized as potential emerging auto market.
Foreign players are adding to their investments in Indian auto industry.
Within two-wheelers, motorcycles contribute 80% of the segment size.
Unlike the USA, the Indian passenger vehicle market is dominated by cars (79%).
Tata Motors dominates over 60% of the Indian commercial vehicle market.
2/3rd of auto component production is consumed directly by OEMs.
India is the largest three-wheeler market in the world.
India is the largest two-wheeler manufacturer in the world.
India is the second largest tractor manufacturer in the world.
India is the fifth largest commercial vehicle manufacturer in the world.
The number one global motorcycle manufacturer is in India.
India is the fourth largest car market in Asia – recently crossed the 1 million mark. (Via Indian Automobiles)
Aston Martin contracted prototyping its latest luxury sports car, AM V8 Vantage, to an Indian-based designer and is set to produce the cheapest Aston Martin ever.
Garment exports are expected to increase from the current level of $6 billion to $25 billion by 2010.
Ranbaxy, the largest Indian pharmaceutical company, gets 70% of its $1 billion revenue from overseas operations and 40% from USA. (Via THE SANGAM FOUNDATION)
1. The English once took it to be an alphabet. The Chinese affectionately term it ‘the little mouse’. The Dutch call it an ‘elephant’s trunk’, the Germans a spider monkey, the Italians as a snail. It is ‘&’ (ampersand).
2. The inspiration for the brand name Yahoo! Came from a word made up by Jonathan Swift in his book Gulliver’s Travels. A Yahoo was a person who was ugly and not a human in appearance.
3. The prime reason the Google home page is so bare, is due to the fact that the founders didn’t know the HTML and just wanted a quick interface. In fact, the submit button was a later addition and initially, hitting the RETURN key was the only way to burst Google into life.
4. Sweden has the highest percentage of its population i.e. 76.9 per cent hooked on to the Internet. In contrast, the world average is 11.9 per cent and India has a poor 7.2 per cent.
5. The Dilbert Zone was the first comic website on the Internet.
6. A resident of Tonga could have the rights to register domains ending in .to as Tongo’s Internet code is .to. Such possibilities are fun to consider: travel.to or go.to.
7. The day after Internet Explorer 4 was released, a few Microsoft employees left a 10 by 12-foot Internet Explorer logo on Netscape’s front lawn with a message that said “We love you” at the height of the browser wars in the late 90’s.
8. The world ‘e-mail’ has been banned by the French Ministry of culture. They are required to use the word ‘Courriel’ instead, which is the French equivalent of Internet. This move became the subject of ridicule from the cyber community in general.
9. Did you know that www.symbolics.com was the first ever domain name registered online?
10. According to a University of Minnesota report, researchers estimate the volume of Internet traffic is growing at an annual rate of 50 to 60 per cent.
11. The term Internet and World Wide Web are often used in every-day speech without much distinction. However, the Internet and the World Wide Web are not one and the same. The Internet is a global data communications system. It is a hardware and software infrastructure that provides connectivity between computers. In contrast, the Web is one of the services communicated via the Internet. It is a collection of interconnected documents and other resources, linked by hyperlinks and URLs.
12. In February 2009, Twitter had a monthly growth (of users) of over 1300 per cent several times more than Facebook.
13. The first graphical Web browser to become truly popular was Marc Andresen and Jamie Zawinski’s NCSA Mosaic. It was the first browser made available for Window’s, Mac and Unix X windows System with the first version appearing in MARCH 1993.
14. The cost of transmitting information has fallen dramatically. A trillion bits of information from Boston to Los Angeles from $150,000 in 1970 to 12 cents today. E-mailing a 40 page document from Chile to Kenya costs less than 10 cents, faxing it about $10, sending it by courier $50.
15. The typical Internet user worldwide is young, male and wealthy – a member of an elite minority.
16. The average total cost of using a local dialup Internet account for 20 hours a month and USD 60 a month in the US. The average African monthly salary is less than USD 60.
17. Before they can read, almost one in four children in nursery school are learning a skill that even some adults have yet to master: using the Internet, about 23per cent of children in nursery school – kids age 3,4 or 5 – have gone online.
18. at the end of the 20th century, 90 per cent of data on Africa was stored in Europe and the United States.
19. Facebook now has 24 million users who spend an average of 14 minutes on the site every time they visit. This is up from 8 minutes last September, according to Hit wise, a traffic measuring service.
20. MySpace has 67 million numbers – nearly 3 times as many as Facebook! MySpace users spend an average of 30 minutes on the site each time they visit.
21. if you want to sell your book on amazon.com you can set the price, but then they will take 55 per cent cut and leave you with only 45 per cent.
22. R Tomlinson was the first person on records to have sent an email. His email address was: <a href=”mailto:tom-linson@bbn.tenexa”>tom-linson@bbn.tenexa</a>. He had invented this software that allowed messages to be sent between computers. He is also credited with the use of the @ in email addresses.
23. Counting only domain name sites with content, Netcraft has tracked the growth of the internet since 1995 and says of the 100 million; around 48 million are active sites that are updated regularly. When it began observing sites through the domain name system in 1995, there were 18,000 web sites in existence.
24. On the internet, a ‘bastion host’ is the only host computer that a company allows to be addressed directly from the public network.
25. Around 1 per cent of the world’s 650 million corporate e-mail accounts are plugged into hardware and software that forwards incoming messages to a mobile device. And about 3.65 million of them us a Blackberry.
26. Almost half of people online have at least three e-mail accounts. In addition the average consumer has maintained the same e-mail address for four to six years.
27. Spam accounts for over 60 per cent of all email, according to Message Labs. Google says at least one third of all Gmail servers are filled with spam.
28. Yahoo started out as “Jerry and David’s guide to the world Wide Web”. Jerry Yang and David Filo were PhD candidates at Stanford in 1994 when they started the site.
29. The first Web browser was already capable of downloading and displaying movies, sounds and any file type supported by the operating system.
30. ‘Carnivore’ is the Internet surveillance system developed by the US Federal Bureau of Investigation (FBI), who developed it to monitor the electronic transmissions of criminal suspects.
31. Anthony Greco, aged 18, became the first person arrested for spam (unsolicited instant messages) on February 21, 2005.
32. A NeXT computer used by Tim Berners-Lee was the world’s first web server.
33. The first web site was built at CERN. CERN is the French acronym for European Council for Nuclear Research and is located at Geneva, Switzerland.
34. The World Wide Web is the most extensive implementation of the hypertext but it is not the only one. A computer help file is actually a hypertext document.
35. The concept of style sheets was already in place when the first browser was released.
36. Worldwide Web was programmed with Objective C.
37. Hypertext is implemented in the web as links in the browser window. Links are references to text that the user wants to access. When a link is clicked the referenced text is displayed or brought into focus.
38. The address of the world’s first web server is <a href=”http://info.cern.ch/”>http://info.cern.ch/</a> The URL of the first web page was <a href=”http://nxoc01.cern.ch/hypertext/WWW/TheProject.html”>http://nxoc01.cern.ch/hypertext/WWW/TheProject.html</a>. Although this page is not hosted anymore at CERN, a later version of the page is posted at <a href=”http://www.w3.org/History/199921103hypertext/hypertext/WWW/TheProject.html”>http://www.w3.org/History/199921103hypertext/hypertext/WWW/TheProject.html</a>.
39. In December 1991, the first institution in the US to adopt the web was the Stanford Linear Accelerator center (SLAC). True to the Berners-Lee vision, it was used to display an online catalog of SLAC’s documents.
40. Marc Andreessen started Netscape and released Netscape Navigator in 1994. during the height of its popularity, Netscape Navigator accounted for almost 90 per cent of all web use.
41. The first browser that made the web available to PC and Mac users was Mosaic. It was developed by National Center for Supercomputing (NCSA) led by Marc Andreessen in February, 1993. Mosaic was one of the first graphical web browsers and led to an explosion in web use.
42. April 30, 1993 is an important date for the Web because on that day, CERN announced that anyone may use WWW technology freely.
43. Microsoft released Internet Explorer on 1995. This event initiated the browser wars. By bundling internet explorer with the Windows operating system, by 2002, Internet Explorer became the most dominant web browser with a market share over 95 per cent.
44. It was in the Conference Dinner in May 26, 1994 where the first Best of WWW awards were given. It was by pure coincidence that the jazz band that played during the awards was called “Wolfgang and the Were Wolves”.
45. Only 4 per cent of Arab women use the Internet. Moroccan women represent almost a third of that figure.
46. As of July 2009, Microsoft Internet Explorer accounted for 67.68 per cent of all browsers used Mozilla Firefox was used by 22.47 per cent of all users.
47. The development of standards for the World Wide Web is managed by the W3C or the World Wide Web consortium. The W3C was founded in October, 1994 and headed by Tim Berners-Lee.
48. The first White House website was launched during the Clinton-Gore administration on October 21, 1994. Coincidentally, the site www.whitehouse.com linked to a pornography web site.
49. Open source technology dominates the web. The most common software used for web serving is called LAMP standing for the Linux operating system, apache web server, MySql database and PHP scripting language.
50. The “www” part of a web site (www.google.com) is optional and is not required by any web policy or standard.
51. Despite IPv4’s 4.3 billion unique addresses, it is forecasted that by 2011, the address space will be consumed. A newer scheme called IPv6 is slowly replacing IPv4 in some countries. IPv6 has the capability to address 2128 computers. to give perspective to this very big number, the world’s population of 6.5 billion people as of 2006 can be given 295 unique addresses.
52. YouTube’s bandwidth requirements to upload and view all those videos cost as much as 1 million dollars a day and drawing. The revenues generated by YouTube cannot pay for its upkeep.
53. The blue colored links on a web page is just a browser default because way back on the days when monitors only had 16 colours, blue was the darkest colour that did not affect text legibility.
54. All three letter word combinations from aaa.com to zzz.com are already registered as domain names.
55. Around 75 per cent of the music that is available for download has never been purchased and it is costing money just to be on the server.
56. One million domain names are registered every month.
57. According to AT&T vice president Jim Cicconi, 8 hours of video is uploaded into YouTube every minute. This was on April 2008. On May 21, 2009, YouTube received 20 hours of video content per minute.
58. Of the 13 million music files available on the web, 52,000 tunes accounted for 80 per cent of download.
59. By 2012 it has been said that there will be 17 billion devices connected to the internet. In most of Asia, mobile phones are leading the way to internet connectivity.
60. The term Deep Web is used to refer to a wealth of information that is at least 400 to 550 times larger than the searchable Internet. This content consisting of most of the information on today’s active websites is stored in databases which are invisible to search engines. this information contains data such as prices of items, airfares and other stuff that will never surface unless somebody queries for that information. The Deep Web and all that hidden information is what prevents search engines from giving us a definitive answer to simple questions like “How much is the cheapest airfare from New York to London next Thursday?”
61. In a recent survey conducted by security specialist Symantec of the 100 most unsafe and malware infested web sites, 48 per cent of them feature adult content.
62. Naked women make up 80 per cent of all the pictures on the internet.
63. The online population of Facebook, 250 million users worldwide, and MySpace, which had 100 million accounts by 2007, are bigger than the populations of many nations worldwide. On April 2008, Facebook overtook MySpace in terms of monthly visits.
64. It took the web only 4 years to reach 50 million users. Radio took 38 years while TV made it in 13 years.
65. Amazon.com was formerly known as Cadabra.com
66. A blogger Kyle MacDonald, made history in 2006 by trading his way to glory. Starting out with a paper clip, he traded his way to increasingly costlier items and of value including a year’s rent and an afternoon with the Alice Cooper. He eventually traded a film role for a two-storey farmhouse Kipling, Saskatchewan.
67. Bit torrents, depending on location, are estimated to consume 27 to 55 per cent of all internet bandwidth as of February, 2009.
68. Domain registration was free until the National Science foundation decided to change this on September 14th, 1995.
69. It is estimated that one of every eight married couples started by meeting online.
70. Lee Stein invented the first online electronic bank in 1994 entitled, “First Virtual Holdings”.
71. The Internet is roughly 35% English with the Chinese at 14%. Yet only 13% of world’s population i.e. 812 million are Internet users as of December 2004. North America has the highest continental concentration with 70 per cent of the populace using the Internet.
72. Official statistics in the UK say that 29 per cent of women have never used the internet, but only 20 per cent of men.
73. In 1995, Bob Metcalfe coined the phrase ‘The Web might be better than sex’.
74. Iceland has the highest percentage of the Internet users at 68 per cent. The United States stands at 56%. 34% of all Malaysians us the Internet while only eight per cent of Jordanians are connected, 4% of Palestinians; 0.6% of Nigerians and 0.1% of Tajikistanis.
75. Employees at Google are encouraged to use 20 per cent of their time working on their own projects. Google News, Orkut are both examples of projects that grew from this working model.
76. Afghanistan has a combined telephone penetration of 3.4 per cent.
77. Someone is a victim of a cybercrime every 10 seconds and it is on the rise.
78. The first search engine for Gopher files was called Veronica, created by the University of Nevada System Computing Services group.
79. The Electrohippies Collective (Ehippies) is an international group of internet activists based in Oxfordshire, England, whose purpose is to express disapproval of governmental policies of mass media censorship and control of the Internet “in order to provide a ‘safe environment’ for corporations to do their deals.”
80. Luking is to read through mailing lists or news groups and get a feel of the topic before posting one’s own message.
81. The Internet was called the ‘Galactic Network’ in memos written by MIT’s JCR Licklider in 1962.
82. The first internet worm was created by Robert Morris, Jr, and attacked more than 6,000 Internet hosts.
83. SRS stands for Shared Registry Server which is the central system for all accredited registrars to access, register and control domain names.
84. The search engine Lycos is named after Lycosidae which is a Latin name for the wolf spider family.
85. It is believed that Subhash Ghai’s film Taal was the first bollywood movie to be widely promoted on the internet.
86. Rob Glasser’s company Progressive Networks launched the RealAudio system on April 10, 1995.
87. Butter Jeeves of the internet site AskJeeves.com made its debut as a large helium balloon in the Macy’s Thanksgiving Day parade in 2000.
88. In Beijing, the internet community has coined the word ‘Chortal’ as a shortened version of ‘Chinese’ Portal.
89. Satyam Online became the first private ISP in December 1998 to offer internet connection in India.
90. In 1946, the Merriam Webster defined a computer as a person who tabulates numbers, accountant, actuary, book keeper.
91. In 1969, advanced Research Projects Agency (ARPA) went online connecting four major US universities. The idea was to have a backup in case a military attack destroyed conventional communication system.
92. The first ever ISP was CompuServe which still exists under AOL, Timer Warner.
93. Jeff Bezos while starting his business could not name his website Cadabra due to copyright issues. He later named it amazon.com.
94. The longest phone cable is a submarine cable called FLAG (Fiber-Optic Link Around the Globe). It spans 16,800 miles from Japan to the United Kingdom and can carry 600,000 calls at a time.
95. The first coin operated machine ever designed was a holy-water dispenser that required a five-drachma piece to operate. It was the brainchild of the Greek scientist Hero in first century A.D.
Android, BlackBerry, iOS and Symbian are the world’s best mobile operating systems. However, there are many differences between their features and performance. The following are the key areas of comparison –
User Interface
Android 2.3 is loaded with several new color schemes and various changes have been made in the user interface. Changes in settings and menus make it easier for the mobile users to navigate and control the features of system and device.
Blackberry OS 6 is having the same professional home screen of its previous version. The swipe-up application menu is included on the bottom on the screen, which is very similar to Android’s pull-down menu.
Symbian OS 3 is an enhanced version of its previous versions of operating system. It features multi-touch support for gestures (for example, pinch to zoom functionality), homescreen support multiple widgets, etc.
iOS user interface is visually striking with bright, finger-friendly icons, pleasing color schemes and fonts, and lovely menu transitions. There is no match to Apple’s beautiful design and intuitive user interfaces.
Winner – iOS
Application Support
There are not many applications for the Android operating system. Android Marketplace is not full of applications. However, the count for total numbers of applications is increasing day by day.
There are also not many applications available for the BlackBerry platform. However, you will certainly find all the major applications in the BlackBerry App World.
Nokia is the oldest among the other big mobile phones, so it is having a massive number of applications in their Ovi Store.
Apple’s App Store is having the most number of applications than any other App Store available in the market. You will find applications for everything.
Winner – iOS
Performance
Android supports NVIDIA Tegra 2 dual core processor, whereas Blackberry, Apple and Nokia are planning to include dual core processor support in their upcoming Smartphones. Therefore, there is no doubt that the performance of Android operating system will be higher than any other mobile operating system. Android is a clear winner in terms of performance.
Device Support
Android is an open source operating system. Therefore, any mobile manufacture can integrate this operating system in their mobile phones. Whereas, BlackBerry’s OS, iOS and Symbian are available only for their respective manufacturing companies, so you will see those operating systems in their manufacturer’s devices only. Therefore, we can say that Android supports most number of devices than any other mobile operating systems.
Winner – Android
From above comparison, we can draw conclusion that Android and iOS are the only two major operating systems available in the market until 2010. However, there are several possibilities that BlackBerry and Symbian operating systems will give tough competition to them in the year 2011.
Symbian 3 and Android 2.2 (Gingerbread) are operating systems for mobile phones and handheld devices. Symbian is an open source platform developed by Nokia and it is mainly used in Nokia phones while Android is also an open source platform developed by software giant Google. Different versions of both the operating systems have been released and Symbian 3 and Android 2.2 or Froyo are one of them.
Symbian 3
Symbian 3 is the latest version of the Symbian mobile platform. A number of developments have been made ranging from architectural renewal in networking and graphics to advancements in the usability of the operating system. The user interface has been made faster than the previous versions. Now, it is easy to connect to the web browser. The radio and gaming has been improved too on this version of Symbian OS. The whole operating system is said to be better, simpler and faster.
The ‘single tap’ method has been applied to the touch interface and the users do not need to tap to select and then tap again for action. It is easier to navigate the user interface. The process of connecting to internet is also easier in this version as the platform-wide behavior can be configured easily by using new global settings.
The hardware acceleration has been fully utilized by the new graphics architecture which also helps in delivering responsive as well as faster user interface. With this architecture, new transitions and effects can be added to the user interface. The data networking architecture has also been modified so that different network aware applications can be handled easily.
The Home screen has also been improved in this new version. Now multiple pages of widgets can be used on the home screen and users can easily navigate between them with a gesture. Multiple widgets’ instances are supported by the Home screen of Symbian 3 platform.
Android 2.2
Andoid 2.2 or Froyo is the next upgrade to Android 2.1 or Éclair. It is developed by Google. Several new features have been added to this version of Android mobile operating system.
A new tips widget has been added to the OS that helps users in configuring their home screens with widgets and shortcuts in an efficient manner. Dedicated shortcuts for Browser, App launcher and Phone have been provided on the Home screen and users can access them from any one of the five Home screens.
Alpha-numeric or numeric pin password protection to unlock the device has also been added to the OS. This greatly helps in improving the security. Remote wipe has also been added through which the device can be reset remotely by Exchange administrators.
Exchange account can be easily setup and synced with the help of Auto discovery. Auto-complete feature have been provided into the email application which searches the global address lists. The gallery has also been improved as users can easily peek into the pictures using the zoom gesture.
Difference between Symbian 3 and Android 2.2
• Symbian 3 OS has been developed by Nokia while Android 2.2. has been developed by Google.
• Nokia N8 is the only phone that currently supports the Symbian 3 platform while Android 2.2 is available in most of today’s Smartphones.
• There is less number of applications based on Symbian 3 OS as compared to Android.
• The Symbian 3 OS supports three Home screens with six static slots on each screen whereas Android supports five Home screens with more dynamically fitting widgets.
• Android 2.2 has built-in support for Flash 10.1 and Wifi hotspot but it does not supports different video formats except the Samsung Galaxy S Smartphone whereas Symbian 3 has Nokia N8 that supports wide variety of video formats.
This term is made from Mobile phone and Biotechnology.As we know that Mobile Phones are the most powerfull tool nowdays.Think if we integrate some of Biometric sensors on mobile phone like sensors that can measure your BP level by touch,narcotics level by your breath as well as sensor that can sense and scan our breath as well as check some of our abnormal body parameters .Then how much powerful tool it will be for human beings e.g:Timely people can get alerts for abnormalities as well as government can utilize this for data collection by bufferingall data to some core servers and then commuting together.Even with the help of ITU-T ;some bytes can be reserved for user health or abnormality monitoring.
For this we can use piezoelectric transducers that have property to convert pressure or weight into electricity.Either we can introduced that sensors or transducers below road at the time of constructions or we can use peizoelectrical substances or particles at the time of construction or even we can add one layer of the material.We know that day by day population is increasing. Thus,traffic too.Now you can think how much volume we can generate electricity anywhere.