
Continue Reading This Article
Sign in with a free account to unlock the full article and access the complete MapYourTech knowledge base.
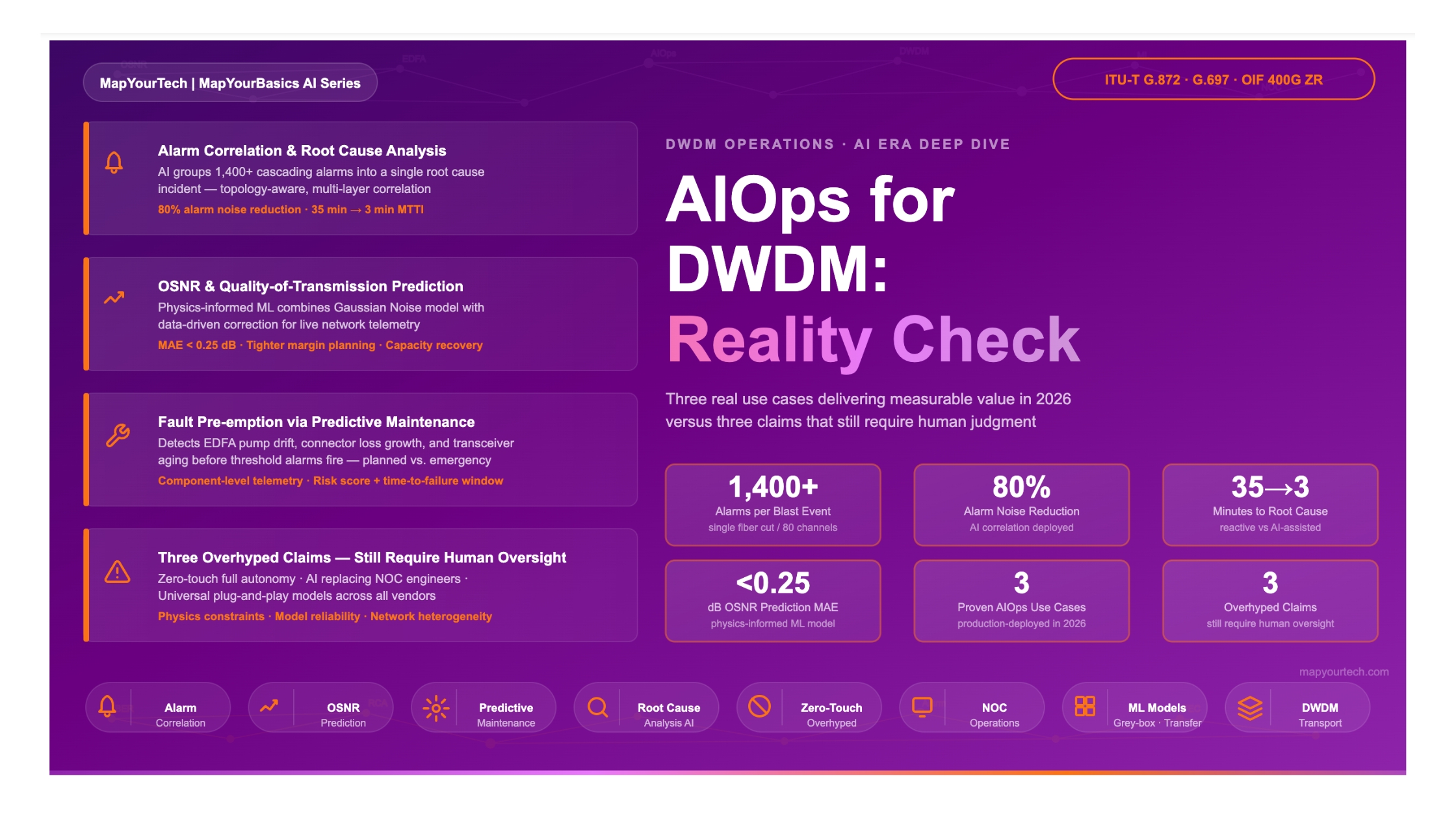
1. Introduction
Setting the context for AI in optical transport operations
Dense Wavelength Division Multiplexing (DWDM) networks carry the bulk of the world's long-haul and metro traffic. As channel counts reach 96 and beyond on the C-band, as modulation formats evolve from QPSK to 64QAM, and as per-channel bit rates push toward 800 Gbps and higher, the volume and complexity of operational telemetry has grown faster than human teams can process manually. Network management systems that were adequate for 10G single-span links become strained when every amplifier span generates continuous OSNR, gain, tilt, and noise figure data across dozens of channels simultaneously.
AIOps — Artificial Intelligence for Operations — has entered optical networking as a response to this data explosion. The premise is straightforward: machine learning models can process telemetry at a scale and speed that human operators cannot match, and they can identify patterns that correlate precursor signals with eventual failures. The industry has embraced this premise enthusiastically, and in some areas, the results are real and measurable. In other areas, the marketing language has outpaced the engineering reality.
This article separates the two. The first half examines three areas where AI delivers verified, production-grade value in DWDM operations today: intelligent alarm correlation and root cause analysis, OSNR and quality-of-transmission prediction, and predictive maintenance for fault pre-emption. The second half examines three claims that remain aspirational rather than operational: fully autonomous zero-touch networks, AI eliminating the need for NOC engineers, and vendor-agnostic universal AI models. Both assessments are grounded in the physics and engineering constraints of optical transport, not in product announcements.
Scope and Boundaries
This article addresses AI-assisted operations for coherent DWDM transport networks using wavelength routing, optical amplification, and real-time performance monitoring. The focus is on the physical and optical transport layers — OSNR management, amplifier chains, wavelength channels, and their associated alarm and telemetry streams. Higher-layer service orchestration, IP/MPLS operations, and enterprise IT AIOps are related but outside this scope.
2. Fundamentals — The Data Foundation of DWDM AIOps
What makes optical networks well-suited for machine learning, and what limits it
2.1 The Telemetry Richness of DWDM Systems
DWDM systems generate a uniquely data-rich operational environment compared to packet networks. For every active wavelength channel on every span, the network produces continuous time-series data across multiple dimensions. At the channel level, this includes optical signal-to-noise ratio (OSNR), Q-factor, pre- and post-FEC bit error rate (BER), channel power, and central frequency deviation. At the amplifier level, it includes EDFA input and output power per span, gain, gain tilt, noise figure, pump laser bias current, pump laser temperature, and total optical power. Coherent transponders add DSP-layer metrics: equalizer convergence state, chromatic dispersion (CD) estimate, differential group delay (DGD), polarization state rotation rate, and nonlinear noise contribution.
This multi-dimensional, continuously updated telemetry is the fuel that makes machine learning viable in optical networks. A 32-span long-haul route with 80 active channels produces thousands of distinct data points per polling cycle. No human operator can track all of these metrics simultaneously or perceive the slow drift patterns that precede a failure. This is precisely where machine learning excels — in finding weak correlations across many variables over long time periods.
Live Telemetry Richness — DWDM Span × Metric Grid (hover a cell for details)
| OSNR (dB) | Rx Power | Q-Factor | EDFA Gain | Pump I | Pump Temp | Pre-FEC BER | CD Est. |
|---|
2.2 Machine Learning Approaches in Optical Operations
Supervised Learning
Trains models on labeled historical data — for example, EDFA telemetry records tagged with whether a failure occurred within the next 30 days. Effective for fault prediction and modulation format classification when sufficient labeled failure examples are available. Requires careful data curation, as failure events are rare and labeling errors degrade model performance.
Unsupervised Learning
Identifies anomalies and clusters in telemetry without labeled training data. Particularly useful for establishing a baseline of "normal" behavior per link or per amplifier, then flagging statistical deviations. Does not require failure history, making it applicable to newly deployed or modified links where historical fault data is unavailable.
Time-Series and Regression Models
Recurrent neural networks (RNNs), Long Short-Term Memory (LSTM) networks, and gradient boosting methods are well-matched to optical telemetry because the data is naturally ordered in time. These approaches can model drift trends — such as a pump laser bias current rising by 0.5 mA per week — and project forward to a likely failure threshold crossing.
Physics-Informed and Grey-Box Models
Combine analytical propagation models (Gaussian noise model, EDFA amplified spontaneous emission formulas) with data-driven correction factors. These hybrid approaches perform well with limited training data because the physical model provides the structural backbone, and the ML component handles the residual uncertainty from real-world manufacturing variation and fiber aging.
2.3 Key Performance Parameters and Their Physical Significance
Understanding AIOps in optical networks requires a clear view of the parameters that AI models operate on. OSNR is the ratio of signal power to accumulated amplified spontaneous emission (ASE) noise power, measured per channel in a reference optical bandwidth. For a chain of N amplifiers, the system OSNR degrades with each added amplifier stage because each EDFA contributes ASE noise in both forward and backward directions.
/* System OSNR for a cascade of N amplifiers */ OSNRsystem = Pch / (N × PASE,span) Where: Pch = Channel launch power per span (mW) N = Number of amplifier spans PASE,span = ASE noise power per amplifier = 2 × nsp × h × ν × (G - 1) × Bref nsp = Spontaneous emission factor (noise figure dependent) G = Amplifier gain (linear) Bref = Reference optical bandwidth (typically 0.1 nm or 12.5 GHz) h = Planck constant (6.626 × 10-34 J·s) ν = Optical frequency (Hz) Typical OSNR targets (at receiver, for BER < 10⁻³ pre-FEC): 100G PDM-QPSK : OSNR > 14–16 dB (0.1 nm noise BW) 200G PDM-16QAM : OSNR > 20–22 dB 400G PDM-64QAM : OSNR > 26–28 dB
The Q-factor is a related metric, often derived from pre-FEC BER measurements, that provides a single scalar representing channel health. AI models typically operate on both OSNR and Q-factor alongside raw power levels and component telemetry, because the correlation patterns between these metrics reveal failure modes that no single parameter captures alone.
3. Real Use Case 1 — Alarm Correlation and Root Cause Analysis
Where AI reliably cuts alarm noise and accelerates fault isolation
1 Alarm Correlation & Root Cause Analysis (RCA)
When a single amplifier fails in a multi-span DWDM network, the cascading effect can trigger hundreds of downstream alarms within seconds — LOS on every channel that traversed that span, FEC-EXC on affected transponders, BDI propagation upstream, and AIS insertion on all dependent paths. Without correlation intelligence, a Network Operations Center (NOC) operator sees hundreds of separate alarms and must manually identify which is the root event and which are symptoms. AI-based alarm correlation solves this by grouping causally related alarms and presenting a single root cause incident.
3.1 The Alarm Storm Problem in DWDM
DWDM networks operating at scale generate alarms at multiple protocol layers simultaneously. A single physical event — such as a fiber cut, an amplifier pump failure, or a connector contamination event — propagates alarms at the optical channel layer (OCh), the optical multiplex section layer (OMS), the OTN layers (OTU, ODU, OPU), and client service layers. Each layer may generate its own alarm independently, with its own timestamp, severity label, and affected entity identifier. In a network carrying 80 channels across 20 spans, a single fiber cut can realistically generate over 500 individual alarm records within the first 60 seconds.
The traditional approach to this problem was parent-child alarm suppression based on statically defined topology rules: if a Loss of Signal (LOS) is raised on a line port, suppress all downstream alarms on services carried by that port. These rule-based systems work well for well-understood, simple failure scenarios. They perform poorly when the failure mode is ambiguous, when multiple simultaneous events overlap, or when the network has been recently modified and the static rules have not been updated.
3.2 How AI-Based Correlation Works
AI-based alarm correlation goes beyond static parent-child rules by training on historical alarm sequences to learn which combinations of alarms co-occur during specific failure scenarios. The model learns that a particular pattern — amplifier gain deviation followed within 2 minutes by OSNR degradation on downstream channels, accompanied by rising pump laser temperature — represents a predictable signature of pump laser thermal instability. When that pattern reoccurs, the system groups all related alarms into a single incident, assigns a root cause hypothesis, and presents it with a confidence score.
Modern implementations also incorporate topology awareness: rather than applying correlation rules globally, the model operates on the physical and logical topology of the network, restricting its correlation scope to alarms that share a common physical path or equipment node. This significantly reduces false positive correlations that would otherwise group unrelated events from different network segments.
Figure 1: Alarm Volume Reduction Through AI Correlation — Illustrative Operational Profile
Figure 1: Illustrative comparison of raw alarm events versus AI-correlated actionable incidents per operational shift. Figures represent typical reduction ratios observed in NOC environments with alarm correlation deployed. Actual results vary by network topology and configuration.
3.3 Practical Deployment Considerations
Alarm correlation AI requires accurate, real-time topology data to function correctly. If the network topology model in the management system does not reflect the current physical configuration — a common situation in networks that are frequently provisioned or modified — the correlation engine may fail to group related alarms or may incorrectly group unrelated ones. Topology accuracy is therefore a prerequisite for effective alarm correlation, not a side condition.
A second practical consideration is the training data requirement. Supervised correlation models require a substantial labeled dataset of historical alarm storms with confirmed root causes. Building this dataset demands that previous incidents were accurately documented — root cause identified, timeline of events recorded, and all contributing alarms captured. Many operators find that their historical incident records lack this level of detail, which means the model must be trained on a limited dataset and initially tuned conservatively to avoid false positives.
Despite these constraints, alarm correlation represents one of the most mature and reliably deployed AIOps applications in optical networking. The problem is well-scoped: inputs are structured telemetry events with timestamps, the output is an incident grouping decision, and the success metric (mean time to identify root cause) is measurable. Operators deploying AI-based correlation consistently report reductions in active alarm count reaching 80% or more during major events, allowing NOC teams to focus response effort on confirmed root causes rather than chasing symptoms.
3.4 The ROI of Alarm Correlation — It Pays Off When Things Go Wrong at Scale
There is a straightforward truth about the return on investment from alarm correlation and automation: in a network where things rarely break, the value is real but modest. In a network where a single event causes a large blast radius — dozens of services down, hundreds of alarms firing across multiple layers, and every available engineer pulled into incident response simultaneously — the value becomes immediate and enormous. The ROI of automation is felt most sharply at exactly the moments when the network is under maximum stress.
Consider what happens during a large-blast-radius event without automated correlation. A core DWDM fiber cut on a hub-and-spoke route carries traffic for 60 services across 12 enterprise customers. Within 90 seconds, the management system generates over 1,400 alarms: LOS on every channel at every downstream node, LOF and FEC-EXC cascading across OTN layers, BDI propagating upstream, AIS insertion on client-side interfaces, and SLA breach notifications from the service layer. Three engineers are now simultaneously staring at alarm panels that look identical except in total alarm count. Each engineer begins investigating independently, pulling up link histories, checking amplifier status, querying configuration — and within the first 20 minutes, at least two of them are investigating symptoms rather than the cause. Mean time to identify the root fiber cut: 35–45 minutes, sometimes longer during off-hours when junior staff are the first responders. Service restoration does not even begin until the root cause is confirmed.
With alarm correlation running, the same 1,400-alarm event is presented to the NOC as a single incident: "Fiber cut detected — span between Node A and Node B — 60 services affected — protection switching available on 48 of 60." The on-call engineer sees one entry, not a wall of red. The AI has already cross-referenced the topology, identified that all affected services share a common physical path segment, and suppressed every downstream symptom alarm as correlated to the single root cause. The engineer confirms the assessment — which takes under a minute when the evidence is coherent and pre-organized — and triggers the protection switching workflow. Services on protected paths restore within seconds of the trigger. The remaining 12 services on unprotected paths are immediately visible as the residual work item, with the repair team dispatch already suggested.
The same principle applies to subtler large-scale events. A software fault on a line card that begins dropping traffic intermittently across 30 services will generate a complex, inconsistent alarm pattern — some channels recovering, some staying down, some triggering FEC-EXC and clearing repeatedly. Without correlation, engineers spend time trying to reconcile a shifting alarm picture while the blast radius grows. With a trained correlation model, the inconsistency pattern itself becomes a signature that maps to known failure modes — and the NOC is directed to the suspect element rather than spending 40 minutes ruling out fiber, amplifiers, and transponders one by one.
This is the core insight about ROI: alarm correlation and automation tools may appear to justify themselves modestly in normal operations. But they pay back their entire cost — and the cost of the entire AI operations platform — within one or two large-scale incidents handled faster, with fewer resources, and with significantly less customer impact. The ROI calculation does not require a monthly average. It requires one bad night when the blast radius is large and the clock is running.
Summary — Use Case 1
- AI alarm correlation reduces thousands of symptomatic alarms to a small number of actionable root cause incidents during network events.
- The ROI of alarm correlation is most visible during large-blast-radius events — a single fiber cut generating 1,400+ alarms is resolved in minutes instead of hours when correlation is deployed.
- The approach works best when combined with accurate, real-time topology data and requires well-curated historical incident records for training.
- Mature deployments report active alarm reductions of 80% or more during major events, measurably reducing mean time to identify root cause.
- Human engineers remain responsible for approving remediation actions — the AI identifies and proposes, the operator decides and executes.
4. Real Use Case 2 — OSNR Prediction and Quality-of-Transmission Estimation
Where AI enables proactive margin management and capacity planning
2 OSNR Prediction and Quality-of-Transmission (QoT) Estimation
Predicting the OSNR and Q-factor that a new wavelength will experience on a given optical path — before activating that wavelength — is a long-standing challenge in DWDM network planning. Traditional analytical models provide estimates, but they require accurate knowledge of fiber span losses, EDFA gain settings, channel loading, and nonlinear effects, all of which carry real-world uncertainty. AI models trained on live network telemetry can produce more accurate QoT predictions by learning the actual, as-deployed behavior of each amplifier and span rather than relying on nominal specifications.
4.1 The QoT Estimation Problem
When an operator wants to add a new wavelength channel to an existing DWDM line system, the fundamental question is: will the new channel achieve adequate OSNR at the destination? This question is complicated by several factors. First, the fiber span losses in an installed plant differ from the nominal fiber loss coefficient due to splice losses, connector aging, and fiber aging effects. Second, EDFA gain curves are not perfectly flat, and the gain tilt changes with channel loading — adding a new channel shifts the total optical power distribution and alters the operating point of each EDFA in the chain. Third, fiber nonlinear effects (self-phase modulation, cross-phase modulation, and four-wave mixing) produce penalties that depend on the launch power levels and spacing of all channels present.
Analytical models based on the Gaussian Noise (GN) model or its enhanced variants provide a tractable framework for QoT estimation, but their accuracy depends on the quality of the input parameters. In operational networks, many of these parameters are known only approximately. Machine learning can bridge this accuracy gap by learning the residual difference between the analytical model's predictions and the actual measured OSNR values across the installed plant.
4.2 Physics-Informed AI for OSNR Prediction
A particularly effective approach combines the Gaussian Noise model as a structural backbone with a data-driven correction layer. The physical model provides the dominant OSNR contribution from amplifier noise accumulation over the span chain. The ML correction layer learns the systematic deviations between the model's predictions and actual measured values, accounting for effects that the analytical model handles imperfectly — spectral hole burning in EDFAs, non-uniform channel loading effects, and span-specific fiber non-idealities.
Research at academic and industrial labs as of 2026 has demonstrated that cascaded learning frameworks using separate component models for EDFAs and fiber spans — trained jointly on real network measurement data — achieve mean absolute prediction errors below 0.25 dB for OSNR over multi-span links under dynamic channel loading conditions. This prediction accuracy is sufficient to make reliable activation decisions for new wavelengths with much tighter margin requirements than traditional worst-case planning approaches.
/* Gaussian Noise Model — simplified OSNR estimation for WDM channel */ GSNR = Pch / (PASE + PNLI) Where: GSNR = Generalized Signal-to-Noise Ratio (dB) Pch = Channel signal power (dBm) PASE = Accumulated ASE noise from amplifier chain (dBm) PNLI = Nonlinear interference noise power (dBm) PNLI ≈ ηNL × Pch3 /* GN model nonlinear coefficient */ /* AI correction layer adds Δ to the GN model output: */ OSNRpredicted = OSNRGN-model + ΔML(features) ΔML = ML-predicted correction term based on: — span-specific fiber loss telemetry — EDFA gain tilt measurements — channel loading configuration — operating temperature at amplifier sites
4.3 Operational Applications of QoT Prediction
Accurate QoT prediction enables several practical improvements in network operations. The most immediate is reducing the engineering margin that operators add when planning new wavelengths. Traditional margin stacking — adding worst-case estimates for each uncertainty in the link budget — often results in a total margin of 3–5 dB above the minimum required OSNR. AI-based QoT prediction, by reducing the prediction uncertainty, can allow operators to reduce this margin to 1–2 dB. This makes it possible to activate wavelengths on routes that would otherwise be considered infeasible under conservative planning, effectively recovering capacity from existing fiber infrastructure without any physical upgrade.
A second application is real-time margin monitoring. As a network ages, fiber spans accumulate additional loss (due to connector degradation, splice point aging, and fiber bend changes), and EDFA pump lasers drift from their initial operating points. AI models tracking the continuous QoT measurements can detect a gradual OSNR margin erosion trend and alert operations teams before the channel reaches its FEC threshold — converting a reactive outage event into a planned maintenance window.
Figure 2: OSNR Margin Erosion Over Network Lifetime — AI-Monitored Trend Detection
Figure 2: Illustrative trend showing OSNR margin for a representative 400G channel decaying over 36 months due to span aging effects. The AI monitoring system detects the trend and triggers a proactive maintenance alert when margin falls below a configurable threshold, before the channel reaches the minimum OSNR required for error-free operation.
Summary — Use Case 2
- Physics-informed AI models combining the Gaussian Noise model with data-driven correction layers can predict OSNR for new wavelength activations with mean absolute error below 0.25 dB in research demonstrations as of 2026.
- Reduced prediction uncertainty allows tighter margin planning, potentially recovering usable capacity on routes constrained under conservative worst-case assumptions.
- Continuous OSNR trend monitoring converts gradual margin erosion from a surprise outage risk into a predictable maintenance item.
- These models require accurate topology data and a calibration phase on the deployed plant — prediction accuracy is link-specific, not universal.
5. Real Use Case 3 — Fault Pre-emption via Predictive Maintenance
Where AI detects early failure signatures before service impact occurs
3 Fault Pre-emption via Predictive Maintenance
Many optical component failures do not occur instantaneously. Laser wavelength drift, EDFA pump laser output degradation, connector contamination, and fiber aging typically develop over days to weeks, leaving traces in the telemetry long before a hard failure is triggered. AI models trained to recognize these precursor patterns can identify at-risk components and generate maintenance alerts while the service remains within its operational margins — enabling planned replacement rather than emergency response.
5.1 Failure Precursor Signatures in DWDM Telemetry
The key insight enabling predictive maintenance is that most optical component failures have a measurable precursor phase. A degrading EDFA pump laser exhibits rising bias current as the pump control loop attempts to maintain constant output power against a declining laser efficiency. The current increase may be small — a few milliamps per week — and will not trigger any threshold alarm in a conventional monitoring system that evaluates each measurement in isolation. However, a machine learning model trained on historical records of pump failures can recognize this slow upward drift as statistically significant and correlated with a future failure event.
Similarly, a contaminated or degrading optical connector progressively increases the insertion loss on the affected span. This loss increase reduces the OSNR of all channels traversing that span, but the reduction may be slow enough — 0.1 dB per month — that it remains below the alarm threshold for many months while accumulating. AI trend analysis on span loss telemetry can detect this drift and flag the connector for inspection before the cumulative loss pushes OSNR below the required minimum.
Coherent transponder health is a third area where predictive maintenance adds measurable value. DSP-layer metrics such as laser wavelength drift, chromatic dispersion estimate variation, and equalizer tap coefficient evolution carry information about transceiver health that is invisible to traditional optical power monitoring. AI models that correlate these DSP metrics with known transceiver failure modes can identify a failing transponder while it is still transmitting within FEC-correctable error rates.
5.2 From Detection to Action — The Maintenance Workflow
A predictive maintenance alert from an AI system is only valuable if it flows into an actionable maintenance process. The operational workflow that follows an alert must address several questions: How confident is the prediction? How much time does the operations team have before the predicted failure? What is the maintenance action required, and is a replacement component available? Can the maintenance be performed without disrupting the affected service?
In practice, well-designed AIOps platforms present predictive alerts with a risk score and an estimated time-to-failure window rather than a binary fault prediction. A risk score of 85% with a time-to-failure estimate of 7–14 days gives the operations team a clear decision point: schedule a maintenance action within the available window, with enough lead time to procure spares and arrange the site visit. This contrasts with the reactive scenario — an unplanned outage at 2 AM requiring emergency truck roll and extended customer impact.
Figure 3: Predictive vs. Reactive Maintenance — Operational Cost and MTTR Comparison
Figure 3: Illustrative comparison of operational cost factors and mean time to repair (MTTR) for reactive maintenance (fault occurs, emergency response) versus predictive maintenance (AI pre-emption, planned response). Values are representative of Tier-1 operator operational experience and are not specific to any single deployment.
5.3 Data Requirements and Model Limitations
Predictive maintenance AI faces a fundamental challenge: failure events are rare. A well-maintained DWDM network may experience fewer than 10–20 component failures per year across a large installed base. Building a statistically robust failure prediction model requires either years of historical data or a large enough fleet to accumulate sufficient examples. Operators with small networks — fewer than 100 nodes — may not have enough failure history to train a reliable model from their own data alone.
One response to this limitation is the use of transfer learning and grey-box modeling, where a model trained on component physics (the expected behavior of an EDFA pump laser as it ages) is fine-tuned with a small number of actual failure examples from the operator's network. Research demonstrations have shown that grey-box EDFA models fine-tuned with as few as 4–8 measurements per amplifier can maintain low OSNR prediction error across diverse amplifier configurations — suggesting this approach has practical validity for smaller deployments.
Summary — Use Case 3
- Gradual component degradation — pump laser drift, connector loss increase, coherent transceiver aging — leaves measurable traces in telemetry that AI can detect before threshold alarms are raised.
- Effective predictive maintenance requires rich telemetry collection (bias current, temperature, gain, power at component resolution) and a management system that preserves this data at adequate temporal resolution.
- The value is converting unplanned emergency events into planned maintenance windows, reducing truck roll costs, emergency parts expenses, and customer-visible outage duration.
- Small networks face a training data limitation — transfer learning and physics-informed models partially address this, but a minimum operational history remains necessary.
6. Three Overhyped Claims That Still Require Human Oversight
Where the engineering reality does not yet match the marketing narrative
The three real use cases above represent areas where AI delivers measurable, reproducible value in deployed networks. The following three claims appear frequently in vendor presentations, industry analyst reports, and conference keynotes but, as of 2026, remain aspirational rather than operational in the vast majority of production environments. Understanding why these claims remain unrealized is as important as understanding what AI can do.
1 Claim: Fully Autonomous Zero-Touch Optical Networks
The claim is that AI will enable networks to detect faults, determine remediation actions, and implement those actions entirely without human involvement — from initial anomaly detection to service restoration. In its strongest form, this claim extends to provisioning, optimization, and configuration changes executed autonomously at the speed of software.
6.1 Why Full Autonomy Remains Unreached
Zero-touch autonomy in optical transport faces a set of engineering constraints that AI does not resolve. The first is the consequence asymmetry of optical remediation actions. In a packet network, rerouting a flow is a low-risk action — the original path can be restored at any time with no physical consequence. In an optical network, actions such as adjusting amplifier gain, changing channel launch power, or switching protection paths have physical consequences on all co-propagating channels. An incorrect gain adjustment on one amplifier can push co-propagating channels into nonlinear noise or receiver overload. An autonomous system that makes an incorrect remediation action may convert a single degraded channel into a multi-channel outage.
The second constraint is AI model reliability in out-of-distribution scenarios. A machine learning model trained on the normal operating range of a network performs reliably within that range. When the network encounters a scenario that differs significantly from the training distribution — a cascade of simultaneous failures, an unusual combination of fiber impairments, or a novel failure mode in a component introduced after the model was trained — the model's confidence and accuracy can degrade without the model itself being aware of its own uncertainty. In a fully autonomous system, this undetected uncertainty translates directly into unreliable actions.
The current industry best practice for autonomous optical actions is a layered autonomy model: AI operates autonomously for low-risk, well-understood, reversible actions (such as adjusting optical power within a defined safe range or switching to a pre-validated protection path), while higher-risk actions (gain block adjustments, amplifier gain tilt correction, new wavelength activation) require human confirmation before execution. This is not a transitional state on the way to full autonomy — it is a design principle that reflects the irreversibility and coupling complexity of optical actions.
Industry Context: Autonomous Network Level Classifications
The TMF (TeleManagement Forum) Autonomous Networks framework defines five levels of network autonomy, from Level 0 (manual operations) to Level 5 (full self-management). As of 2026, most production optical networks operate at Level 2 (partial automation) or Level 3 (conditional autonomy), where AI-generated recommendations are reviewed before execution. Level 4 (high autonomy, human exception handling) is the near-term target for well-constrained action categories. Level 5 is not considered achievable for core transport networks given current safety and reliability requirements.
2 Claim: AI Will Eliminate the Need for NOC Engineers
A persistent narrative frames AIOps as a path to dramatically reducing or eliminating the human workforce in network operations centers. The argument is that AI can handle anomaly detection, alarm triage, root cause analysis, and incident management automatically, reducing the NOC headcount requirement to near zero.
6.2 What AI Replaces and What It Does Not
AI systems that handle alarm correlation, anomaly detection, and predictive alerting do eliminate a specific category of NOC work: the manual task of reading through thousands of active alarms to determine which require attention. This is real and significant — a task that previously occupied a large portion of NOC engineer time. However, the reduction in this specific activity does not translate to a reduction in the overall need for experienced engineers. It translates to a reallocation of engineer time toward higher-value activities.
Engineers are still needed to verify AI recommendations before execution, particularly for actions that have physical consequences. They are needed to investigate novel failure modes that the AI has not encountered before — and to feed the findings back into the training data so the model improves. They are needed to manage the exceptions that any probabilistic system generates, because an AI operating at 95% accuracy on a network processing 1,000 events per day still produces 50 incorrect assessments daily. They are needed when multiple simultaneous failures create a situation that exceeds the AI's training distribution, which is precisely when the network most needs skilled human judgment.
The accurate framing is that AI acts as a force multiplier for NOC engineers — enabling a smaller team to manage a larger and more complex network with better outcomes — rather than a replacement. Operators that have deployed AI-assisted NOC tools report that engineer roles shift from reactive alarm watching to proactive monitoring, model oversight, and complex incident management. This shift requires more technically capable engineers, not fewer.
3 Claim: Universal Plug-and-Play AI Models Across All Vendors and Networks
Some vendors and platforms claim that their AI models, once trained, can be deployed universally across any optical network — regardless of equipment vendor, fiber type, amplifier configuration, or geographic context — without site-specific calibration or retraining.
6.3 The Network-Specificity Problem
Optical networks are physical systems, and the behavior of a given link is determined by the specific fiber installed, the specific amplifiers deployed at specific gain settings, the specific connectors with their specific aging states, and the specific channel loading at any given time. Two 1,000 km links that appear identical on paper — same fiber type, same amplifier count, same channel plan — will differ in their actual OSNR profiles, their amplifier gain tilt behavior, and their failure mode statistics because they are composed of different physical components deployed in different environments.
A QoT prediction model trained on one network's measurement data will encode the specific characteristics of that network's amplifiers, fiber spans, and channel loading patterns. When deployed on a different network with different equipment or fiber, its predictions will carry a systematic error that reflects the difference between the training environment and the target environment. This is not a solvable problem through more training data alone — it is a physical reality of network heterogeneity.
Transfer learning and grey-box modeling approaches mitigate this problem by requiring only a small calibration dataset from the target network, but they do not eliminate the need for calibration entirely. Any AI model intended for use in optical operations must undergo a site-specific validation phase to confirm that its predictions are accurate within the required error tolerance for that specific network. Models that skip this calibration may perform well on average across many networks while performing poorly on specific links where the physical characteristics deviate significantly from the training distribution.
This constraint is particularly relevant in multi-vendor open optical networks, where a controller may aggregate telemetry from amplifiers and transponders from different manufacturers, each with different internal monitoring calibrations and slightly different parameter definitions. Building a unified AI model that correctly interprets and acts on heterogeneous telemetry from multiple vendors requires careful data normalization and often vendor-specific calibration work that is not reflected in the "plug-and-play" claim.
Summary — Overhyped Claims
- Full zero-touch autonomy is not achievable for high-consequence optical actions — layered autonomy with human confirmation for reversible decisions is the current and near-term production model.
- AI does not eliminate NOC engineers — it reallocates their work from reactive alarm watching to higher-value supervision, model oversight, and complex incident management.
- Universal AI models that require no site-specific calibration are not achievable for physics-based optical predictions — every deployed model must be validated on the target network's actual telemetry.
7. Comparative Assessment — Real vs. Overhyped
Engineering maturity, deployment readiness, and human oversight requirements
| AIOps Application | Maturity Level | Data Requirement | Human Oversight Required | Primary Benefit | Key Constraint |
|---|---|---|---|---|---|
| Alarm Correlation & RCA | Labeled historical alarm storms + topology model | Remediation confirmation; exception review | Alarm noise reduction; faster MTTI | Requires accurate topology data; training dataset quality | |
| OSNR / QoT Prediction | Link-specific telemetry; calibration measurements | Activation decision review; model validation | Reduced engineering margin; capacity recovery | Network-specific calibration required; accuracy degrades on novel routes | |
| Predictive Maintenance | Component-level telemetry; failure history | Maintenance scheduling; replacement authorization | Planned replacement vs. unplanned outage | Rare failure events; small networks face training data gaps | |
| Full Zero-Touch Autonomy | Complete network model + proven action library | Required for all consequential actions | Operational labor reduction | Consequence coupling; out-of-distribution reliability gap | |
| AI Replacing NOC Engineers | N/A | Always required | Work reallocation to higher-value tasks | Exception management; novel failures; safety verification | |
| Universal Plug-and-Play Models | Transfer learning reduces but does not eliminate calibration | Validation required on each new network | Faster deployment with transfer learning | Physical network heterogeneity; multi-vendor telemetry normalization |
Table 1: AIOps Application Assessment for DWDM Operations — Engineering Maturity and Deployment Readiness as of 2026.
8. Implementation Considerations for Optical AIOps
Practical requirements for deploying AI in DWDM operations
8.1 Telemetry Infrastructure Prerequisites
AI in optical operations is only as capable as the telemetry it receives. Before deploying any AI application, operators should assess their telemetry collection infrastructure against three dimensions: resolution, completeness, and history. Resolution refers to how frequently metrics are polled and stored — many management systems poll optical performance parameters on 15-minute intervals, which is too infrequent to capture the fast transient events needed for alarm correlation models. Effective AIOps implementations typically require 1-minute or sub-minute polling for key metrics such as OSNR, channel power, and amplifier status. Completeness refers to whether all relevant metrics are collected — if EDFA bias current data is not collected, predictive maintenance models for pump laser degradation cannot be built. History refers to the duration over which telemetry is retained — 6 months of data is the practical minimum for drift trend analysis, and 2–3 years is preferable for failure prediction model training.
8.2 Model Validation and Confidence Management
Deploying an AI model in a production optical network requires a validation phase before the model's outputs are used in operational decisions. The validation should cover the model's performance across all link types present in the network (short metro links, multi-span long-haul, submarine), across different channel loading conditions, and across different seasons if the network shows seasonal variation in span loss or amplifier performance. Any systematic bias in the model's predictions — such as consistently underestimating OSNR on links with specific fiber types — should be corrected before production deployment.
Model confidence management is equally important. AI models should always output a confidence indicator alongside their prediction. Operations teams should be trained to treat low-confidence predictions as requiring additional verification before action, and the AIOps platform should route low-confidence incidents to higher-skill operators rather than junior NOC staff. A model that presents all predictions with equal confidence — regardless of how far the current network state deviates from the training distribution — is less safe than one that explicitly communicates its uncertainty.
8.3 Closed-Loop Safety Architecture
Any AI system that can generate actions on the network — not just recommendations — must incorporate a safety architecture that limits the scope of autonomous action and provides reliable rollback capability. The key design principles for optical AIOps safety include action categorization (classifying every possible action by its reversibility and potential blast radius), action pre-validation (confirming through simulation or model prediction that the proposed action will not degrade any other active service before executing), rate limiting (restricting the number of autonomous actions per time window to prevent compounding errors from rapid sequential decisions), and mandatory human confirmation for any action whose predicted consequence uncertainty exceeds a defined threshold.
9. Future Directions
Where the technology is heading and what milestones remain
The near-term evolution of AIOps in optical networking will be shaped by three converging developments. The first is the increasing deployment of digital twins — software representations of the optical network that are continuously updated with live telemetry and can be used to simulate the effect of proposed actions before they are executed. Digital twins allow autonomous action systems to validate their decisions against a physics-accurate model of the network state, significantly reducing the out-of-distribution risk that currently limits autonomous action confidence.
The second development is the maturation of open line system interfaces and standardized telemetry APIs, which make it progressively easier to aggregate multi-vendor telemetry into a common format suitable for AI model training. As the data normalization problem is progressively addressed through standards work at bodies such as OpenConfig and the TeleManagement Forum, the vendor-agnosticism constraint on AI models will partially ease — not disappear, but become more tractable.
The third development is the expansion of AI-assisted network planning. Current deployments focus on operations — monitoring, fault management, and real-time optimization of an existing network. The next phase extends AI to the planning layer, where models trained on operational network behavior feed back into capacity planning tools, helping operators design new routes with realistic margin assumptions rather than conservative worst-case estimates. This closes the loop between operations experience and network design, creating a continuously improving planning baseline grounded in measured network behavior.
The overarching trajectory is toward tighter integration between AI-assisted operations and physics-based network modeling, with human engineers maintaining oversight of the model quality and the boundary conditions of autonomous action. The goal is not networks that operate without human involvement but networks whose operational complexity can be effectively managed by skilled human teams even as scale and capacity continue to grow.
10. Reference Architecture — AIOps in DWDM Operations
Component view of an operational AI-assisted optical management platform
Figure 4: AIOps Reference Architecture for DWDM Operations — showing the four-layer structure from physical network telemetry through data platform, AI inference engine, and human-in-the-loop operations.
11. Conclusion
AIOps in DWDM operations is neither a complete solution to operational complexity nor a marketing illusion. It is a set of engineering tools that, when applied to the right problems with appropriate data infrastructure and human oversight, deliver measurable and reproducible operational improvements.
The three areas where AI reliably adds value today — alarm correlation and root cause analysis, OSNR and quality-of-transmission prediction, and fault pre-emption through predictive maintenance — share a common characteristic: they are well-scoped problems with structured inputs, measurable outputs, and clearly defined success metrics. Alarm correlation reduces noise and accelerates root cause identification. QoT prediction improves margin utilization and enables safer wavelength activation. Predictive maintenance converts unplanned outage events into scheduled maintenance windows. These are real, significant improvements that translate directly to reduced operational costs and improved service reliability.
The three areas where the claims exceed the current reality — full zero-touch autonomy, engineer replacement, and universal plug-and-play models — share a different characteristic: they underestimate the physical constraints of optical networking, the consequence of model errors in coupled physical systems, and the irreplaceable value of experienced human engineering judgment at the boundaries of well-understood operational ranges.
The productive path forward for optical network operators is to invest in the data infrastructure that enables effective AI applications, deploy the proven use cases with appropriate human oversight, and evaluate vendor AI claims against the specific engineering constraints of optical transport rather than against generic IT operations benchmarks. Networks that do this will capture real operational benefits. Networks that deploy AI in pursuit of the overhyped claims without the necessary data infrastructure and operational discipline will find that the promise outpaces the delivery.
Glossary
Artificial Intelligence for Operations. The application of machine learning and data analytics to automate and improve network operations tasks such as event correlation, anomaly detection, root cause analysis, and predictive alerting.
A transmission technology that multiplexes multiple optical carrier signals onto a single fiber using different wavelengths, enabling high-capacity transport over long distances.
An optical amplifier that amplifies light signals in the 1530–1565 nm C-band using erbium-doped fiber excited by pump lasers. The primary amplification technology in long-haul and metro DWDM systems.
A metric that extends OSNR by including the contribution of fiber nonlinear interference noise in addition to amplifier ASE noise, providing a more accurate representation of channel quality in high-power or multi-span scenarios.
An analytical framework for estimating fiber nonlinear interference as an additive Gaussian noise term, allowing closed-form QoT estimation for WDM transmission links without full numerical simulation.
A recurrent neural network architecture designed to learn dependencies in sequential time-series data. Particularly suited for optical telemetry trend analysis due to its ability to retain context over long time windows.
The average time elapsed between the occurrence of a fault and its correct identification by the operations team. AI-based alarm correlation directly targets reduction of this metric.
The ratio of signal optical power to amplified spontaneous emission noise power, measured in a specified reference optical bandwidth. A primary quality-of-transmission indicator for DWDM channels.
A scalar representation of signal quality, typically derived from pre-FEC BER measurements. Provides a single-number summary of channel health that combines multiple impairment contributions.
A composite measure of how well a wavelength channel meets its signal quality requirements over a given optical path, taking into account noise accumulation, nonlinear effects, and component impairments.
The process of identifying the fundamental cause of a network fault or degradation event, as opposed to its symptomatic manifestations in downstream layers and services.
A machine learning technique where a model trained on one dataset is adapted to a different but related dataset using a small amount of target-domain data. Used in optical AIOps to deploy models to new networks without requiring full retraining from scratch.
References
- ITU-T Recommendation G.872 – Architecture of optical transport networks.
- ITU-T Recommendation G.697 – Optical monitoring for dense wavelength division multiplexing systems.
- ITU-T Recommendation G.7710 – Common equipment management function requirements.
- IEEE 802.3bs – 200 Gb/s and 400 Gb/s Ethernet.
- OIF IA # OIF-FLEX-400G-01.0 – 400G ZR/ZR+ Implementation Agreement.
- P. Poggiolini, "The GN Model of Non-Linear Propagation in Uncompensated Coherent Optical Systems," Journal of Lightwave Technology, 2012.
- D. Rafique and L. Velasco, "Machine Learning for Optical Network Applications," IEEE/OSA Journal of Lightwave Technology, 2018.
- TeleManagement Forum (TMF) TR-290 – Autonomous Networks — Levels of Autonomy Framework, 2023.
- NEC Laboratories America, "Multi-span OSNR and GSNR Prediction using Cascaded Learning," ECOC 2025.
- Sanjay Yadav, "Optical Network Communications: An Engineer's Perspective" – Bridge the Gap Between Theory and Practice in Optical Networking.
Developed by MapYourTech Team
For educational purposes in Optical Networking Communications Technologies
Note: This guide is based on industry standards, best practices, and real-world implementation experiences. Specific implementations may vary based on equipment vendors, network topology, and regulatory requirements. Always consult with qualified network engineers and follow vendor documentation for actual deployments.
Feedback Welcome: If you have any suggestions, corrections, or improvements to propose, please feel free to write to us at [email protected]

Optical Networking Engineer & Architect • Founder, MapYourTech
Optical networking engineer with nearly two decades of experience across DWDM, OTN, coherent optics, submarine systems, and cloud infrastructure. Founder of MapYourTech. Read full bio →
Follow on LinkedIn